








来自阿联酋起源研究院的工作
论文地址:https://arxiv.org/pdf/2111.09881.pdf
代码地址:https://github.com/swz30/Restormer
这个论文的主要想法是将 Transformer 模型应用到图像修复中,不过和一般的VIT模型不同的是,没有使用 patch 级的特征进行 token 建模,可以理解为每个像素就是一个 token。
Transformer block 主要包括两部分:一部分是self-attention 的计算,另一部分是 FFN 部分。作者也很自然的想到了改进这两个部分,提出了两个模块,分别是:
- Multi-Dconv Head Transposed Attention,主要改进 self-attention 部分
- Gated-Dconv Feed-Forward Network,主要改进FFN部分
1、 Multi-Dconv Head Transposed Attention (MDTA)
作者提出的这个模块没有进行 patch 级的 token 计算,而是像素级的。对于输入的特征首先利用 1X1 的 point-wise卷积处理,然后用 3X3 的 depth-conv 来处理。接下来就是很常规的 self-attention 计算了。值得注意的是,因为
W
∗
H
W*H
W∗H 的维度远高于
C
C
C,因此相似性的计算是在
C
C
C 这个维度上进行的。这里也使用了 multi-head 来降低计算量来分组学习。
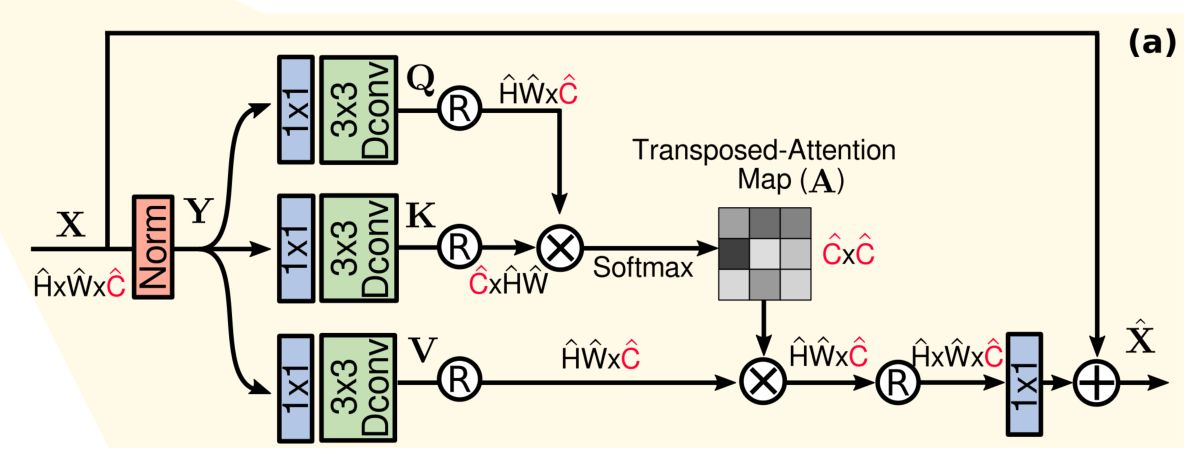
该模块的代码如下:
## Multi-DConv Head Transposed Self-Attention (MDTA)
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b,c,h,w = x.shape
# 升维,卷积,分块得到qkv
qkv = self.qkv_dwconv(self.qkv(x))
q,k,v = qkv.chunk(3, dim=1)
# 维度变化 [B, C, H, W] ==> [B, head, C/head, HW]
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
# [B, head, C/head, HW] * [B, head, HW, C/head] * [head, 1, 1] ==> [B, head, C/head, C/head]
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
# [B, head, C/head, C/head] * [B, head, C/head, HW] ==> [B, head, C/head, HW]
out = (attn @ v)
# [B, head, C/head, HW] ==> [B, head, C/head, H, W]
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
2、Gated-Dconv Feed-Forward Network (GDFN)
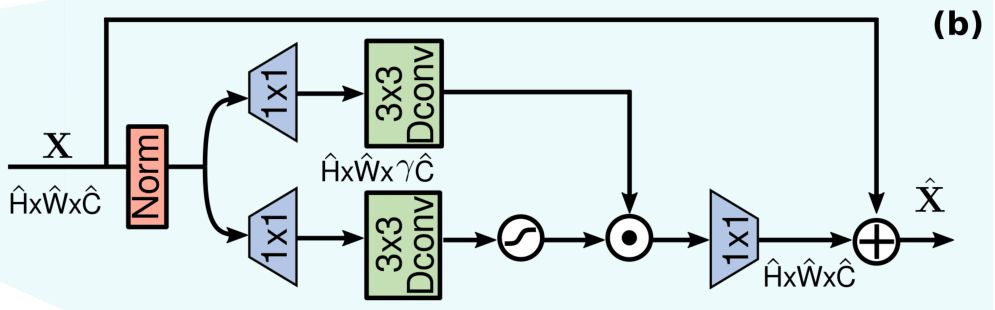
这里作者提出了一个新的模块来取代 Transformer block 里的 FFN 部分,是一个双路的门控网络,两个分支都是先用 1X1 的 point conv 处理,用于扩展特征通道(膨胀比为
γ
=
2.66
\gamma=2.66
γ=2.66),然后两个分支都使用 3X3 的 depth conv 提取特征。下面分支使用GELU激活函数得到门控。最后用 1X1 的 point conv 来降回以前的维度。
NOTE:组会讨论这个论文时,都不明白为啥要使用这个激活函数,今天查了查,有个知乎文章 里解释说:GELU可以看作 dropout的思想和relu的结合,从公式上来看,GELU对于输入乘以一个0,1组成的mask,而该mask的生成则是依靠伯努利分布的随机输入。早期的深度学习库里没有 GELU 函数,因此在较早的keras和torch的transformer实现的代码里都是用relu+dropout而没有使用gelu来引入一定的随机性,可以让神经网络对大数据的训练更鲁棒
该模块的代码如下:
## Gated-Dconv Feed-Forward Network (GDFN)
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
return x
3、网络总体框架
论文的总体框架如下图所示,包括四层对称的 encoder-decoer 结构,还有一个用于 refinement 的部分。四层的 transformer block 的个数依次为(4,6,6,8),refinement部分的transformer block数量为4 。
- 特征下采样,使用 torch.nn.PixelShuffle 实现:Rearranges elements in a tensor of shape ( ∗ , C × r 2 , H , W ) (*, C \times r^2, H, W) (∗,C×r2,H,W) to a tensor of shape ( ∗ , C , H × r , W × r ) (*, C, H \times r, W \times r) (∗,C,H×r,W×r), where r r r is an upscale factor.
- 特征上采样,使用 torch.nn.PixelUnshuffle 实现:Reverses the PixelShuffle operation by rearranging elements in a tensor of shape
(
∗
,
C
,
H
×
r
,
W
×
r
)
(*, C, H \times r, W \times r)
(∗,C,H×r,W×r) to a tensor of shape
(
∗
,
C
×
r
2
,
H
,
W
)
(*, C \times r^2, H, W)
(∗,C×r2,H,W), where r is a downscale factor.
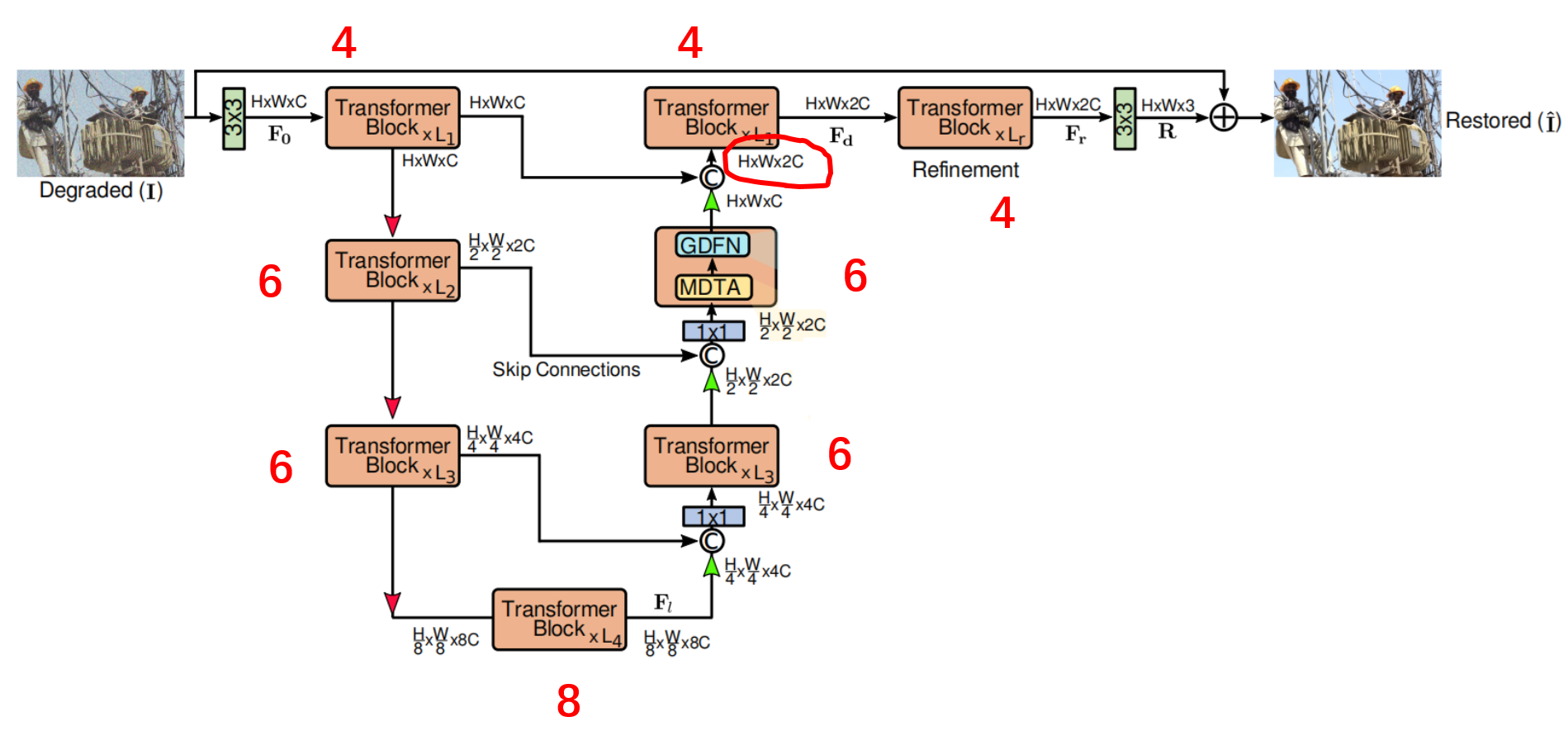
通过 skip connection 将编码器和解码器的输出拼接,拼接时得到 C 上的维度会翻倍,然后使用 1X1 的总面积来降维。值得注意的是,最后一层(画红圈的部分),没有使用 1X1 的卷积处理。
4、实验结果和一些想法
训练时应用了 Progressive Learning (训练的图像逐渐增大),这是因为在裁剪的小块图像上训练时,难以获足够的全局信息,从而在测试大尺寸图像时性能不够好。因此,在训练时将 patch 逐渐从128 增大到 384 ,实验中也有地方分析了这样做确实能够涨点。
作者在图像去寸、图像去模糊、图像去噪等应用上进行了实验评估,该方法都能够取得最优的性能,这里不过多介绍。
个人想法:
- 感觉论文在进行实验对比时,只是比较了PSNR和SSIM值,没有比较网络的参数量,不清楚性能的提升是来自于网络参数的增加还是改进的两个模块。
- GDFN 里有个参数 γ = 2.66 \gamma=2.66 γ=2.66,不清楚为什么设置为这个值,实验部分也没有分析。
- 实验部分大多在介绍方法性能非常好,为什么性能会好,分析的内容相对少。














 1826
1826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









