







车道线检测:End-to-end Lane Shape Prediction with Transformers论文解析
论文链接:https://arxiv.org/pdf/2011.04233.pdf
论文出处:WACV2020
论文代码:https://github.com/liuruijin17/LSTR
研发团队:西安交通大学人工智能与机器人研究所
1. Abstract
- 车道线检测是将车道识别为近似曲线的过程。
- 主流的pipeline是分成2步解决问题:特征提取和后处理。虽然有用,但效率低下。
- 本文提出了一种端到端方法,该方法可以直接输出车道形状模型的参数,使用通过transformer构建的网络来学习更丰富的结构和上下文。
- 车道形状模型是基于道路结构和摄像头姿势制定的,可为网络输出的参数提供物理解释。
- transformer使用自我注意机制(self-attention mechanism)对非局部交互进行建模,以捕获细长的结构和全局上下文。
- 该方法已在TuSimple基准测试中得到验证,并以最轻巧的模型尺寸和最快的速度显示了最新的准确性。
2. Introduction
- 之前的车道线检测流程一般是:先分割车道线,再做聚合(segment clustering),再做曲线拟合。
- 缺点:这些方法效率低,且做车道线分割时忽略全局上下文信息(global context)。
- 为了解决效率和车道线结构的问题,建议将车道检测输出重构为车道形状模型的参数(parameters of a lane shape model),并开发一个由非局部构件(non-local building blocks)构建的网络,以加强对全局上下文信息(non-local building blocks)和车道细长结构的学习。
- 每个车道的输出是一组参数,这些参数通过从道路结构和摄像机姿态推导出的显式数学公式近似于车道标记。在给定摄像机固有参数等特定先验条件下,无需任何3D传感器,这些参数就可以用于计算道路曲率和摄像机俯仰角。
- 开发了一个基于transformer的网络,该网络从任何成对的视觉特征中总结信息,使其能够捕获车道线的狭长结构和全局上下文信息( global context)。
- 整个体系结构立即预测输出,并采用匈牙利损失(Hungarian loss)进行端到端训练。
- 损失模型采用预测与真值之间的双边匹配( bipartite matching),保证一对一的无序分配,使模型消除了显性的非极大抑制过程。
- 在常规的多车道检测基准TuSimple上验证了该方法的有效性。
- 为了评估对新场景的适应性,我们在多个城市收集了大量具有挑战性的数据集,称为前视车道(FVL),跨越各种场景(城市和高速公路、白天和夜晚、各种交通和天气条件)。该方法在复杂数据集不包含夜景等场景的情况下,对新场景具有较强的适应性。
- 本文主要贡献:
(1)提出了一种车道形状模型,其参数作为直接回归输出,反映道路结构和摄像机姿态。
(2)开发了一个基于transformer的网络,该网络考虑了非局部的相互作用,以捕获车道和全局上下文的细长结构。
(3)本文方法以最少的资源消耗达到了最先进的精度,并对具有挑战性的自采集车道检测数据集显示了良好的适应性。
3. Related Work
- 将车道线检测视为实例分割的问题,如:Towards End-to-End Lane Detection an Instance Segmentation Approach
- 将车道线检测视为目标检测的问题,如:Line-cnn: Endto-end traffic line detection with line proposal unit
- 将车道线检测视为关键点检测的问题,如:Key Points Estimation and Point Instance Segmentation Approach for Lane Detection
4. Method
- 本文端到端方法重构输出为车道形状模型的参数。通过基于transformer的网络with匈牙利拟合损失对参数进行预测。
4.1 车道形状模型(Lane Shape Model)
- 车道形状的先验模型被定义为多项式。通常,三次曲线用来近似平地上的单车道线:
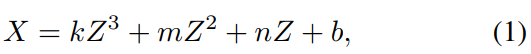
其中k,m,n,b是实数参数,(X,Z)表示地平面的点。
- 当光轴平行于地平面时,从道路屏幕投影到图像平面的曲线为:
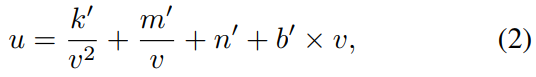
其中 k’,m’,n’,b’ 是参数和相机内外参的混合。 (u,v)是图像平面的点。
- 对于一个倾斜相机的光轴与地平面成φ角时,从不倾斜的图像平面到倾斜的图像平面的曲线转换为:
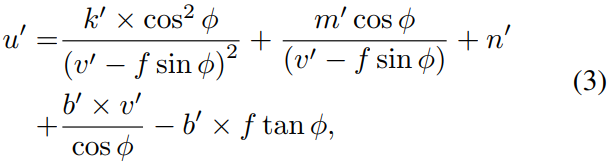
其中 f 是焦距,(u’, v’)是倾角转换的点位置,当 φ = 0,公式(3)简化成公式(2)。
曲线的重新参数化
-
将参数与俯仰角φ相结合,倾斜摄像机平面的曲线为:
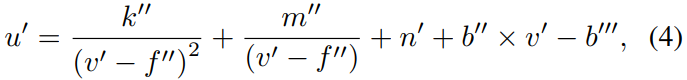
其中,两个常数项 n’ 和 b’’’ 没有集成,因为他们包含不同的物理参数。 -
此外,还引入了垂直起止偏移量α、β来参数化各车道线。这两个参数提供了基本的定位信息来描述车道线的上下边界。
-
在真实的道路条件下,车道通常具有全局一致的形状。因此,近似圆弧从左到右车道的曲率相等,因此k′′,f′′,m′′,n′将被所有车道共享。因此,t-th车道的输出被重新参数化为gt:
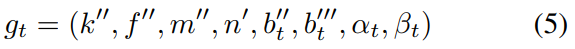
其中 t∈{1,…,T},T 是图像中车道线的数量,每个车道仅在偏差项和上下边界上有所不同。
4.2 匈牙利拟合损失(Hungarian Fitting Loss)
- 匈牙利拟合损失在预测参数和车道真值之间进行匹配,采用匈牙利算法有效地解决了匹配问题,然后利用匹配结果优化路径相关回归损失。
- 损失模型采用预测与真值之间的双边匹配( bipartite matching)。
- 回归误差:
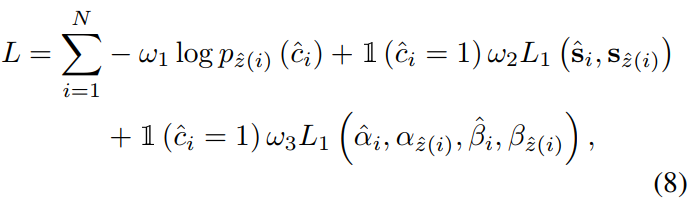
4.3 网络结构
- 图1所示的体系结构包括一个主干(backbone)、一个简化transformer网络、几个用于参数预测的前馈网络(FFNs)和匈牙利损失。
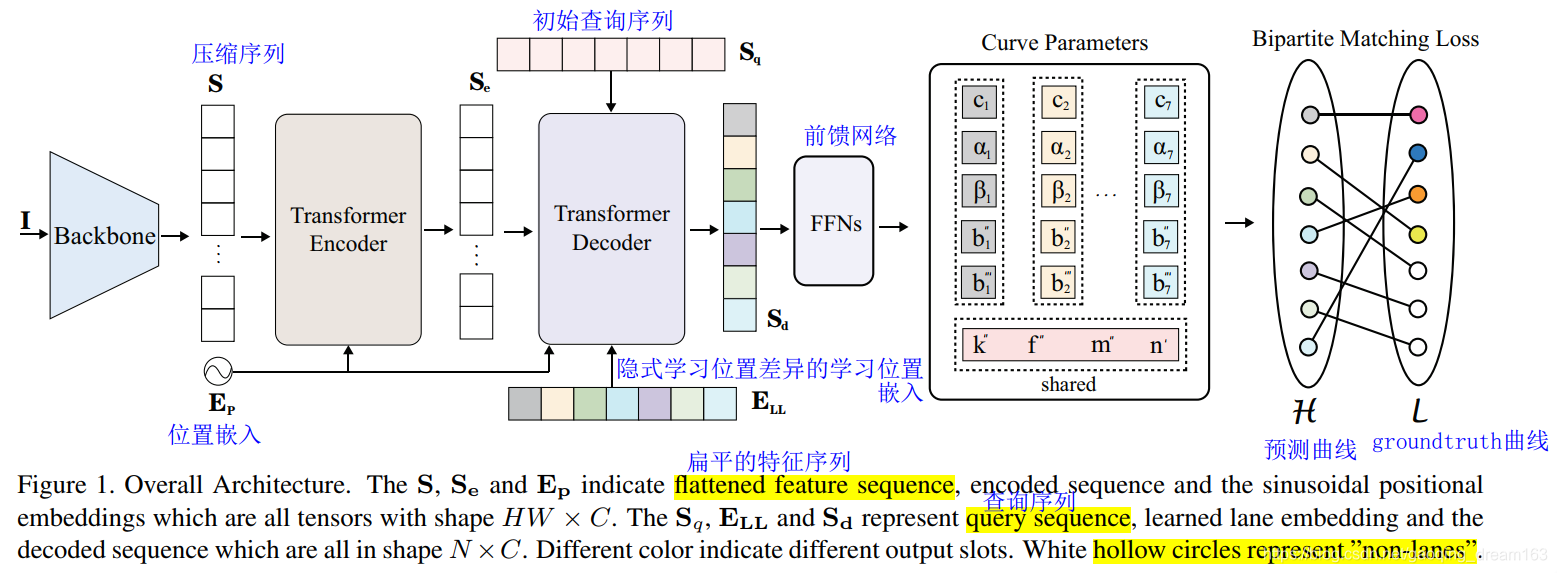
- 给定输入图像 I,主干提取低分辨率特征,然后通过压缩空间维度将其压缩成一个序列 S。S和位置嵌入 Ep 馈入transformer, Encoder以输出表示序列 Se。
- 然后,Decoder首先处理一个初始查询序列 Sq 和一个隐式学习位置差异的学习位置嵌入 ELL 生成输出序列 Sd,计算与 Se 和 Ep 的交互以处理相关特征。
- 最后,有几种FFNs直接对所提出的输出参数进行预测。
4.3.1 Backbone
- 主干是建立在reduced ResNet18的基础上。原ResNet18有4个block和16倍下采样功能。每个块的输出通道为“64、128、256、512”。
- 本文简化 ResNet18将输出通道削减为“16、32、64、128”以避免过拟合,并将降采样因子设置为8以减少车道结构细节的损失。
- Backbone利用输入图像作为输入,提取低分辨率特征,对高分辨率车道空间表示进行编码。
- 接下来,为了构造一个作为编码器输入的序列,将该特征在空间维度上进行平铺,得到一个长度为HW×C的序列S,其中HW表示序列的长度,C为信道数。
4.3.2 Encoder
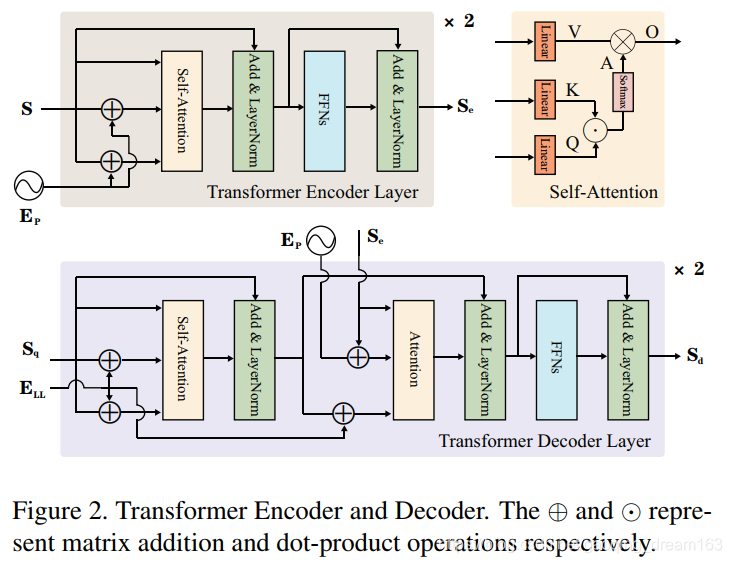
- 编码器有两个按顺序链接的标准层。它们分别由一个自注意模块和一个前馈层组成,如图2所示。
- 在抽象空间表示序列S的基础上,利用基于绝对位置的正体嵌入Ep对位置信息进行编码,以避免排列变化。该Ep具有与s相同的尺寸。编码器通过下式执行缩放点积注意(scaled dot-product attention):
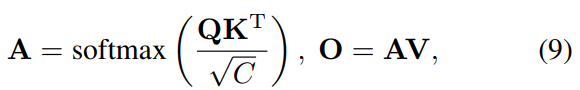
- 其中Q,K,V表示对每个输入行进行线性变换的查询、键和值序列,A表示度量非局部交互以捕获纤细结构和全局上下文的注意力映射,O表示自注意的输出。
- HW×C形状的编码器Se的输出序列是通过FNNs、层归一化的residual连接和另一个相同的编码器层得到的。
4.3.3 Decoder
- 解码器也有两个标准层。与编码器不同的是,每一层都插入另一个注意模块,该模块期望编码器的输出,使编码器能够对包含空间信息的特征执行注意机制,从而与最相关的特征元素相关联。
- 面对翻译任务,原转换器将地真序列移位一个位置,作为译码器的输入,使其每次并行输出序列中的每个元素。
- 在车道检测任务中,我们将输入的Sq设置为一个空的N×C矩阵,并直接一次解码所有的曲线参数。
- 此外,我们引入了一种N×C的学习车道嵌入算法,作为隐式学习全局车道信息的位置嵌入。注意机制与公式9相同,解码后的N×C形状的序列Sd与编码方法相似。
- 训练时,在每一解码层之后进行中间监督。
4.3.4 FFNs用于预测曲线参数
- 预测模块通过三部分生成预测曲线H集合。单个线性操作直接将Sd投射为N×2,然后softmax层对其进行最后维运算,得到预测标签(background或lane)ci.
- 同时,一个具有ReLU激活和隐C维的3层感知器将Sd投射为N×4,其中维4表示四组特定路径参数。另一个3层感知器首先将一个特征投影到N×4,然后在第一维取平均值,得到4个共享参数。
5. Experiments
- 数据集:
(1)The TuSimple dataset :consists of 6408 annotated images which are the last frames of video clips recorded by a high-resolution (720×1280) forward view camera across various traffic and weather conditions on America’s highways in the daytime. It is split initially into a training set (3268), a validation set (358), and a testing set (2782).
(2)自制数据集Forward View Lane (FVL):The FVL contains 52970 images with a raw resolution of 720 × 1280. These images were collected by a monocular forward-facing camera typically located near the rear-view mirror in multiple cities across different scenes (urban and
highway, day and night, various traffic and weather conditions). - 评估标准:
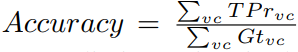
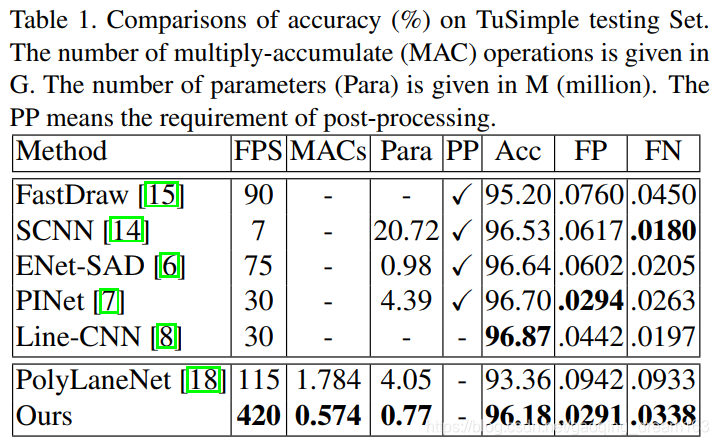
5.1 State-of-the-Art方法比较

5.2 消融实验(Ablation Study)
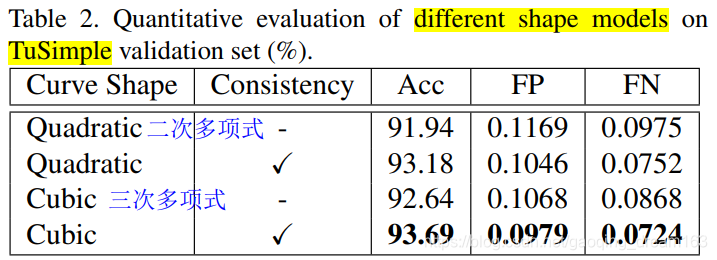
- 针对形状模型的对比
- 编码器层数的对比(Number of encoder layers)
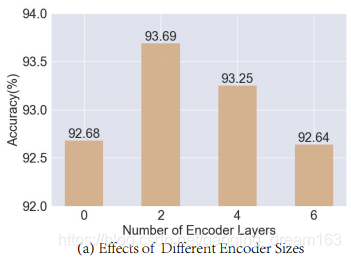
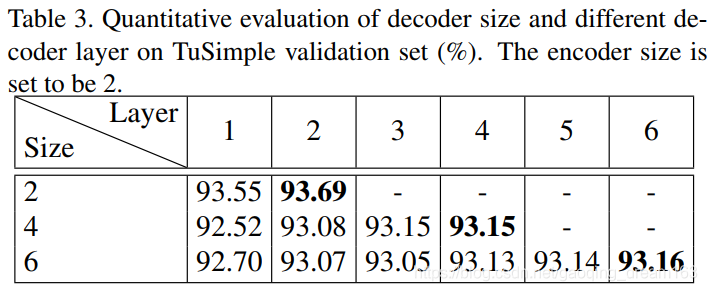
- 解码器层数的对比(Number of decoder layers)
- 预测曲线数量的对比(Number of predicted curves)
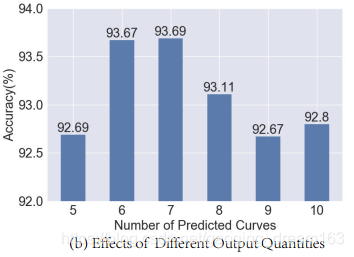
5.2 FVL Dataset上的迁移测试
- 并没有在FVL数据集上训练。
- 测试结果

6. 结论
- Future work:
(1)研究复杂、细微的车道线检测任务;
(2)引入跟踪功能。

















 1817
1817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









