







Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
3.1 Introduction and Transport-Layer Services
- A transport-layer protocol provides for logical communication between application processes running on different hosts. Application processes use the logical communication to send messages to each other.
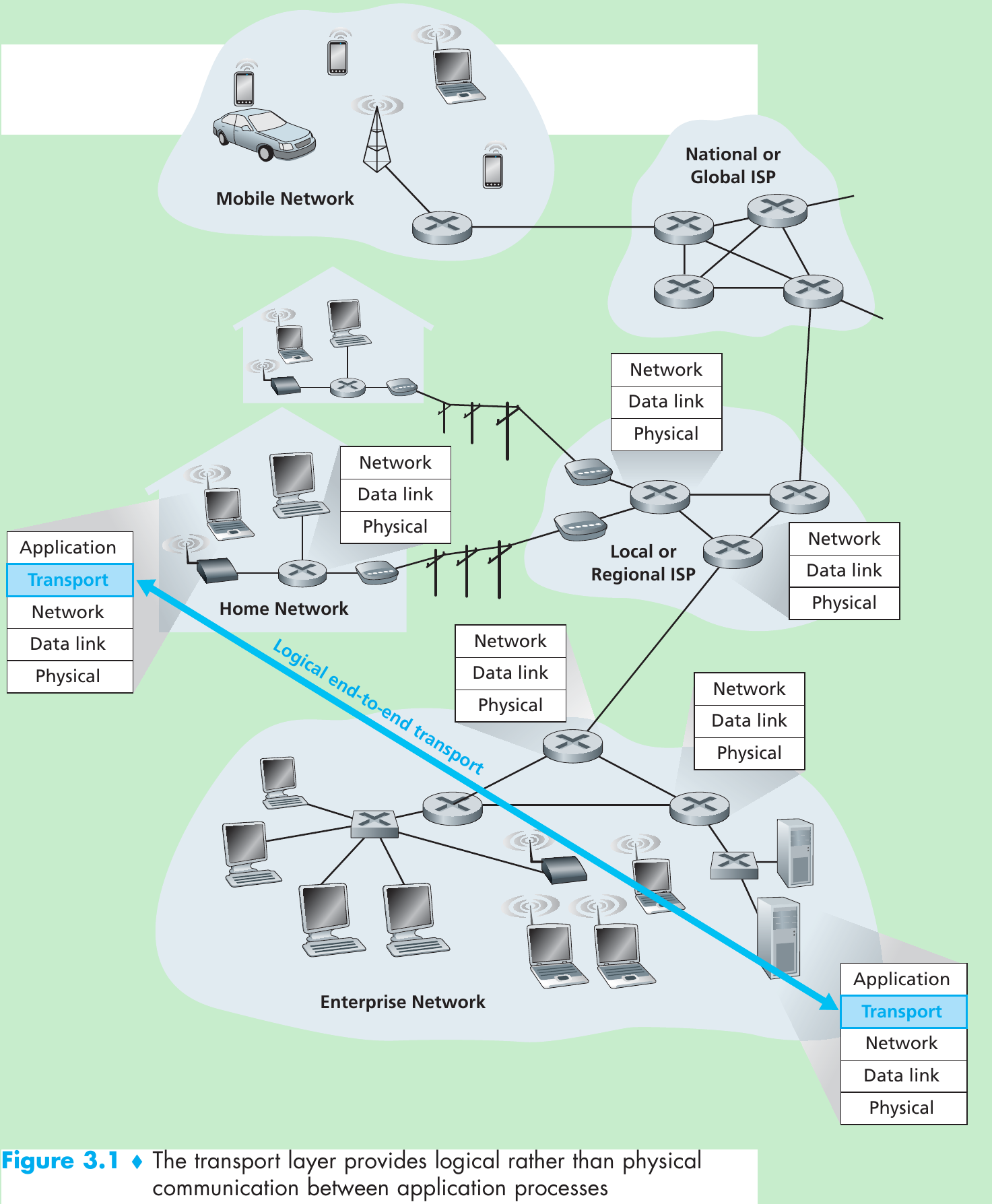
- Transport-layer protocols are implemented in the end systems but not in network routers.
- On the sending side, the transport layer converts the application-layer messages it receives from a sending application process into transport-layer segments by breaking the application messages into smaller chunks and adding a transport-layer header to each chunk.
- The transport layer then passes the segment to the network layer at the sending end system, where the segment is encapsulated within a network-layer packet (a datagram) and sent to the destination. Network routers act only on the network-layer fields of the datagram, they do not examine the fields of the transport-layer segment encapsulated with the datagram.
- On the receiving side, the network layer extracts the transport-layer segment from the datagram and passes the segment up to the transport layer. The transport layer then processes the received segment, making the data in the segment available to the receiving application.
3.1.1 Relationship Between Transport and Network Layers
- A transport-layer protocol provides logical communication between processes running on different hosts; a network-layer protocol provides logical communication between hosts. Within an end system, a transport protocol moves messages from application processes to the network layer and vice versa.
- A computer network may have multiple transport protocols, with each protocol offering a different service model to applications.
- The services that a transport protocol can provide are often constrained by the service model of the underlying network-layer protocol. If the network-layer protocol can’t provide delay or bandwidth guarantees for transport-layer segments sent between hosts, then the transport-layer protocol cannot provide delay or bandwidth guarantees for application messages sent between processes. But certain services can be offered by a transport protocol even when the underlying network protocol doesn’t offer the corresponding service at the network layer.
3.1.2 Overview of the Transport Layer in the Internet
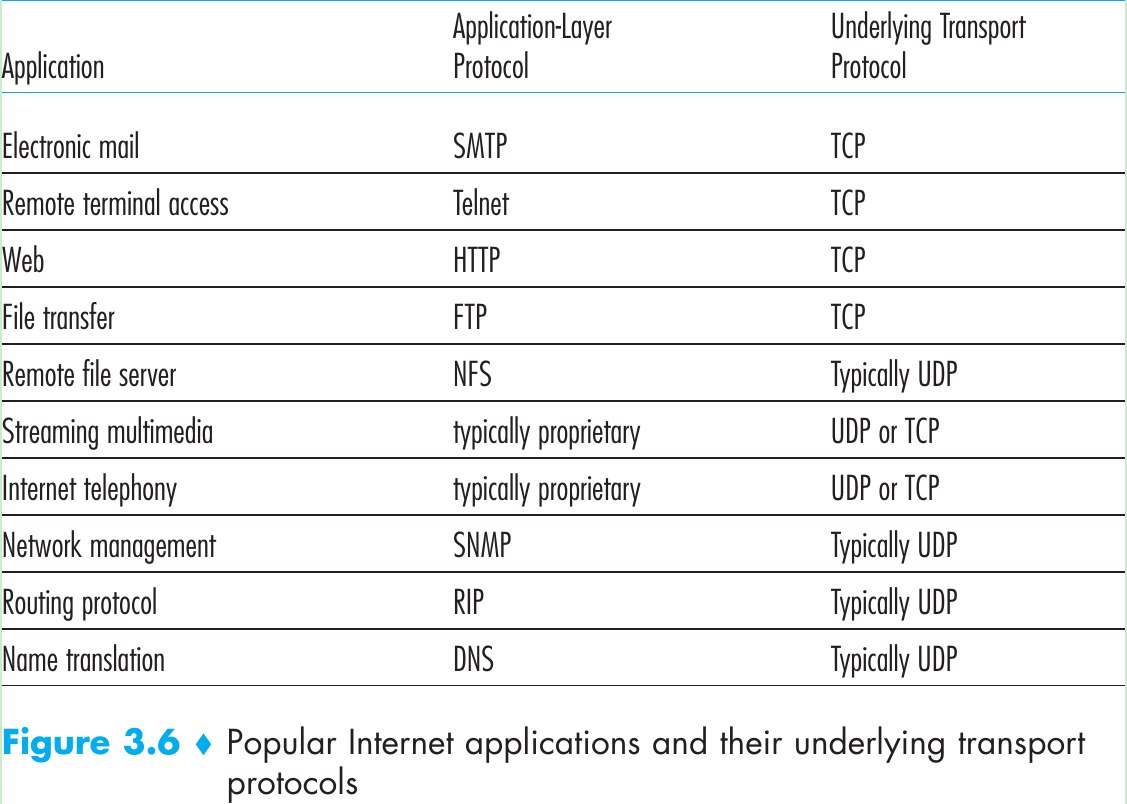
- A TCP/IP network, makes two distinct transport-layer protocols available to the application layer. One is UDP (User Datagram Protocol), which provides an unreliable, connectionless service to the invoking application. The other is TCP (Transmission Control Protocol), which provides a reliable, connection-oriented service to the invoking application.
- The Internet’s network-layer protocol has a name—IP, for Internet Protocol. IP provides logical communication between hosts. The IP service model does not guarantee orderly delivery of segments, and it does not guarantee the integrity of the data in the segments. So IP is said to be an unreliable service. Every host has at least one network-layer address, a so-called IP address.
- The most fundamental responsibility of UDP and TCP is to extend IP’s delivery service between two end systems to a delivery service between two processes running on the end systems. Extending host-to-host delivery to process-to-process delivery is called transport-layer multiplexing and demultiplexing.
- UDP and TCP provide integrity checking by including error-detection fields in their segments’ headers.
- These two minimal transport-layer services (process-to-process data delivery and error checking) are the only two services that UDP provides. Moreover, UDP is an unreliable service—it does not guarantee that data sent by one process will arrive intact to the destination process.
- TCP provides reliable data transfer by using flow control, sequence numbers, acknowledgments, and timers. TCP thus converts IP’s unreliable service between end systems into a reliable data transport service between processes.
- TCP also provides congestion control that prevents any one TCP connection from swamping the links and routers between communicating hosts with an excessive amount of traffic. TCP strives to give each connection traversing a congested link an equal share of the link bandwidth. This is done by regulating the rate at which the sending sides of TCP connections can send traffic into the network.
- UDP traffic is unregulated. An application using UDP transport can send at any rate it pleases, for as long as it pleases.
3.2 Multiplexing and Demultiplexing
- Transport-layer multiplexing and demultiplexing is extending the host-to-host delivery service provided by the network layer to a process-to-process delivery service for applications running on the hosts. A multiplexing/demultiplexing service is needed for all computer networks.
- At the destination host, the transport layer receives segments from the network layer just below. The transport layer must deliver the data in these segments to the appropriate application process running in the host.
- Suppose your computer have four network application processes running—two Telnet processes, one FTP process, and one HTTP process. When the transport layer in your computer receives data from the network layer below, it needs to direct the received data to one of these four processes.
- A process (as part of a network application) can have one or more sockets, doors through which data passes from the network to the process and through which data passes from the process to the network.
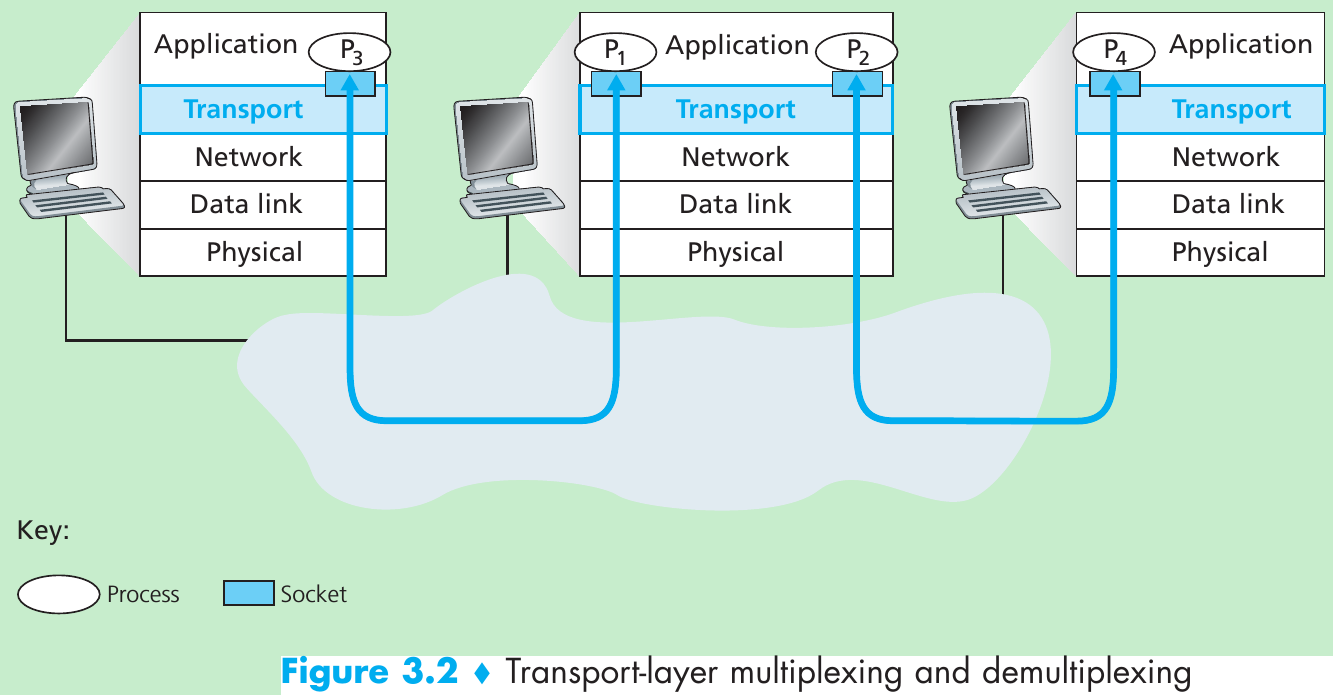
- Thus the transport layer in the receiving host does not deliver data directly to a process, but instead to an intermediary socket. Because at any given time there can be more than one socket in the receiving host, each socket has a unique identifier. The format of the identifier depends on whether the socket is a UDP or a TCP socket.
- Each transport-layer segment has a set of fields in the segment. At the receiving end, the transport layer examines these fields to identify the receiving socket and then directs the segment to that socket.
- The job of gathering data chunks at the source host from different sockets, encapsulating each data chunk with header information (that will later be used in demultiplexing) to create segments, and passing the segments to the network layer is called multiplexing.
The job of delivering the data at the end host in a transport-layer segment to the correct socket is called demultiplexing. - Multiplexing and demultiplexing are concerns whenever a single protocol at one layer (at the transport layer or elsewhere) is used by multiple protocols at the next higher layer.
- Transport-layer multiplexing requires
(1) sockets have unique identifiers;
(2) each segment have special fields that indicate the socket to which the segment is to be delivered.
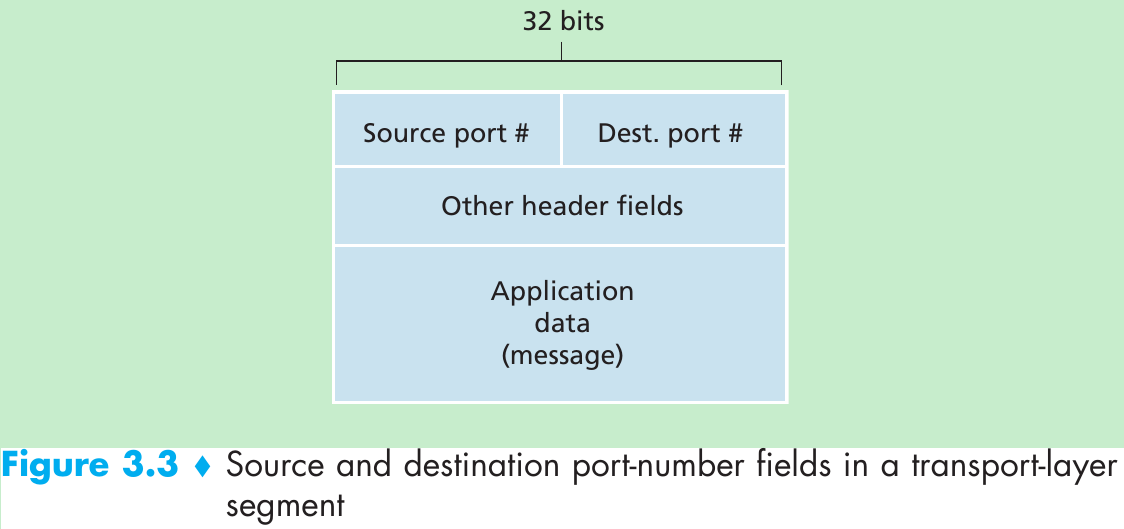
- These special fields are the source port number field and the destination port number field. Each port number is a 16-bit number, ranging from 0 to 65535. The port numbers ranging from 0 to 1023 are called well-known port numbers and are restricted, which means that they are reserved for use by well-known application protocols such as HTTP (port number 80) and FTP (port number 21).
- When we develop a new application, we must assign the application a port number. Each socket in the host could be assigned a port number, and when a segment arrives at the host, the transport layer examines the destination port number in the segment and directs the segment to the corresponding socket. The segment’s data then passes through the socket into the attached process.
- When a UDP socket is created, the transport layer automatically assigns a port number to the socket which is in the range 1024 to 65535 that is currently not being used by any other UDP port in the host.
- If the application developer writing the code were implementing the server side of a “well-known protocol,” then the developer would have to assign the corresponding well-known port number.
- Suppose a process in Host A, with UDP port 19157, wants to send a chunk of application data to a process with UDP port 46428 in Host B. The transport layer in Host A creates a transport-layer segment that includes the application data, the source port number (19157), the destination port number (46428), and two other values. The transport layer then passes the resulting segment to the network layer. The network layer encapsulates the segment in an IP datagram and deliver the segment to the receiving host.
- When the segment arrives at the receiving Host B, the transport layer at the receiving host examines the destination port number in the segment (46428) and delivers the segment to its socket identified by port 46428. Note that Host B could be running multiple processes, each with its own UDP socket and associated port number. As UDP segments arrive from the network, Host B directs (demultiplexes) each segment to the appropriate socket by examining the segment’s destination port number.
- A UDP socket is fully identified by a two-tuple consisting of a destination IP address and a destination port number. So if two UDP segments have different source IP addresses and/or source port numbers, but have the same destination IP address and destination port number, then the two segments will be directed to the same destination process via the same destination socket.
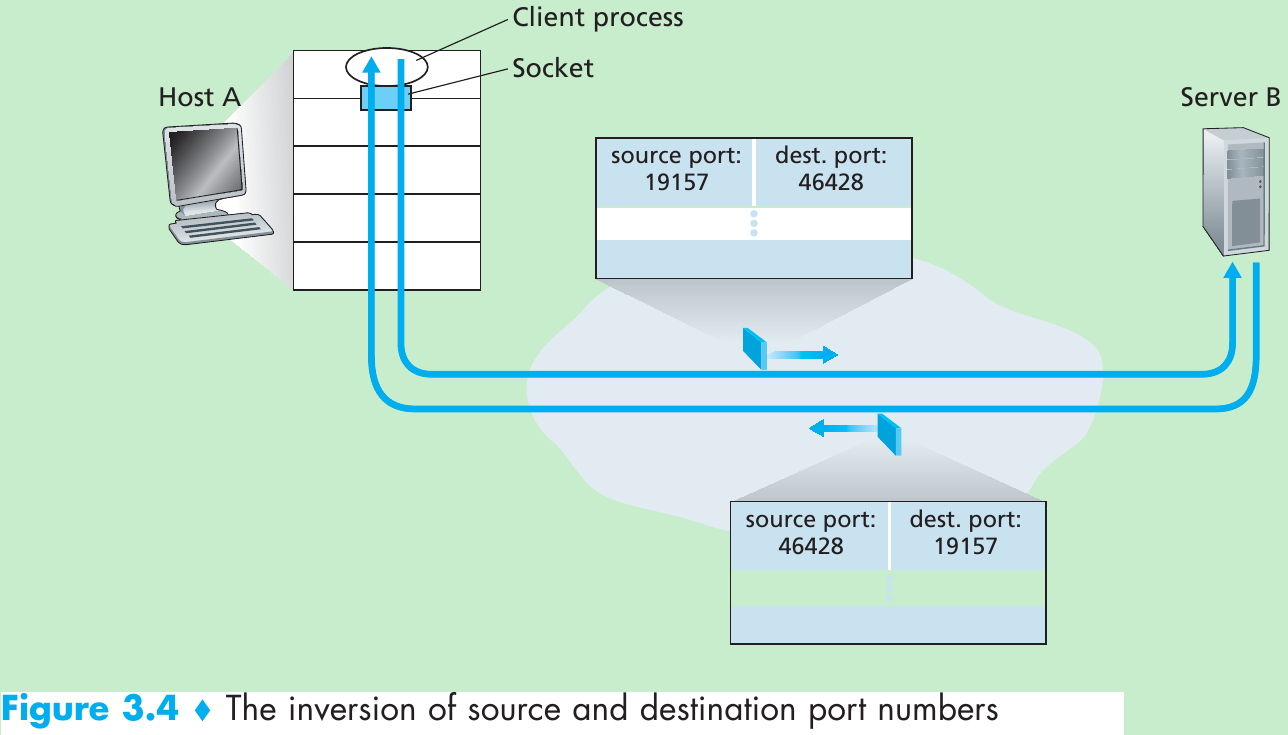
- In the A-to-B segment the source port number serves as part of a “return address”, when B wants to send a segment back to A, the destination port in the B-to-A segment will take its value from the source port value of the A-to-B segment.
- One difference between a TCP socket and a UDP socket is that a TCP socket is identified by a four-tuple: (source IP address, source port number, destination IP address, destination port number).
- When a TCP segment arrives from the network to a host, the host uses all four values to direct (demultiplex) the segment to the appropriate socket. In contrast with UDP, two arriving TCP segments with different source IP addresses or source port numbers will (with the exception of a TCP segment carrying the original connection-establishment request) be directed to two different sockets.
- The server host can support many simultaneous TCP connection sockets, with each socket attached to a process, and with each socket identified by its own four-tuple.
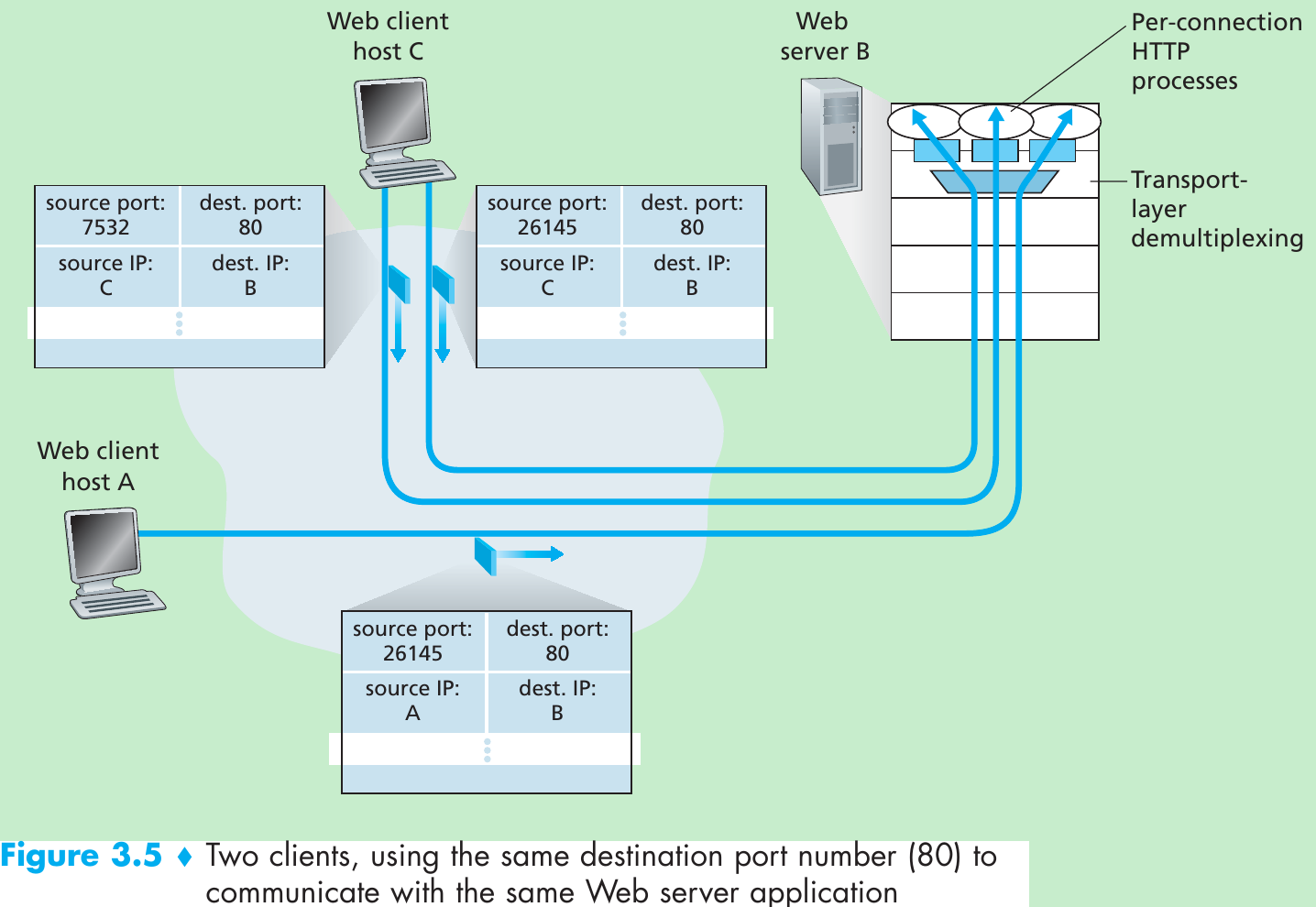
- Host C initiates two HTTP sessions to server B, and Host A initiates one HTTP session to B. Hosts A and C and server B each have their own unique IP address—A, C, and B, respectively. Host C assigns two different source port numbers (26145 and 7532) to its two HTTP connections.
- Because Host A is choosing source port numbers independently of C, it might also assign a source port of 26145 to its HTTP connection. But server B will still be able to correctly demultiplex the two connections having the same source port number, since the two connections have different source IP addresses.
- Figure 3.5 shows a web server that spawns a new process for each connection. Each of these processes has its own connection socket through which HTTP requests arrive and HTTP responses are sent. There is not always a one-to-one correspondence between connection sockets and processes. Today’s high-performing web servers often use only one process, and create a new thread with a new connection socket for each new client connection. For such a server, at any given time there may be many connection sockets (with different identifiers) attached to the same process.
- If the client and server are using persistent HTTP, then throughout the duration of the persistent connection the client and server exchange HTTP messages via the same server socket.
- If the client and server use non-persistent HTTP, then a new TCP connection is created and closed for every request/response, and hence a new socket is created and later closed for every request/response. This frequent creating and closing of sockets can severely impact the performance of a busy web server.
3.3 Connectionless Transport: UDP
- Aside from the multiplexing/demultiplexing function and error checking, UDP adds nothing to IP. UDP takes messages from the application process, attaches source and destination port number fields for the multiplexing/demultiplexing service, adds two other small fields, and passes the resulting segment to the network layer. The network layer encapsulates the transport-layer segment into an IP datagram and then deliver the segment to the receiving host.
- When the segment arrives at the receiving host, UDP uses the destination port number to deliver the segment’s data to the correct application process. With UDP there is no handshaking between sending and receiving transport-layer entities before sending a segment. So UDP is said to be connectionless.
- DNS is an application-layer protocol that typically uses UDP. When the DNS application in a host wants to make a query, it constructs a DNS query message and passes the message to UDP. Without performing any handshaking with the UDP entity running on the destination end system, the host-side UDP adds header fields to the message and passes the resulting segment to the network layer. The network layer encapsulates the UDP segment into a datagram and sends the datagram to a name server. The DNS application at the querying host then waits for a reply to its query. If it doesn’t receive a reply (possibly because the underlying network lost the query), either it tries sending the query to another name server, or it informs the invoking application that it can’t get a reply.
Many applications are better suited for UDP for the following reasons: - Finer application-level control over what data is sent, and when.
- Under UDP, as soon as an application process passes data to UDP, UDP will package the data inside a UDP segment and immediately pass the segment to the network layer.
- TCP has a congestion-control mechanism that throttles the transport-layer TCP sender when one or more links between the source and destination hosts become congested.
- TCP will continue to resend a segment until the receipt of the segment has been acknowledged by the destination, regardless of how long reliable delivery takes.
- Since real-time applications often require a minimum sending rate, don’t want to overly delay segment transmission, and can tolerate some data loss, TCP’s service model is not well matched to these applications’ needs. So these applications can use UDP and implement, as part of the application, any additional functionality that is needed beyond UDP’s no-frills segment-delivery service.
- No connection establishment.
TCP uses a three-way handshake before it starts to transfer data. UDP just blasts away without any formal preliminaries. Thus UDP does not introduce any delay to establish a connection. This is the principal reason why DNS runs over UDP rather than TCP: DNS would be much slower if it ran over TCP. HTTP uses TCP rather than UDP, since reliability is critical for web pages with text. But, the TCP connection-establishment delay in HTTP is an important contributor to the delays associated with downloading web documents. - No connection state.
TCP maintains connection state in the end systems which includes receive and send buffers, congestion-control parameters, and sequence and acknowledgment number parameters that are needed to implement TCP’s reliable data transfer service and to provide congestion control. UDP does not maintain connection state and does not track any of these parameters. So a server devoted to a particular application can typically support many more active clients when the application runs over UDP rather than TCP. - Small packet header overhead.
The TCP segment has 20 bytes of header overhead in every segment, whereas UDP has only 8 bytes of overhead.
- It is possible for an application to have reliable data transfer when using UDP if reliability is built into the application itself (for example, by adding acknowledgment and retransmission mechanisms). But this is a nontrivial task that would keep an application developer busy debugging for a long time. Nevertheless, by building reliability directly into the application, application processes can communicate reliably without being subjected to the transmission-rate constraints imposed by TCP’s congestion-control mechanism.
3.3.1 UDP Segment Structure
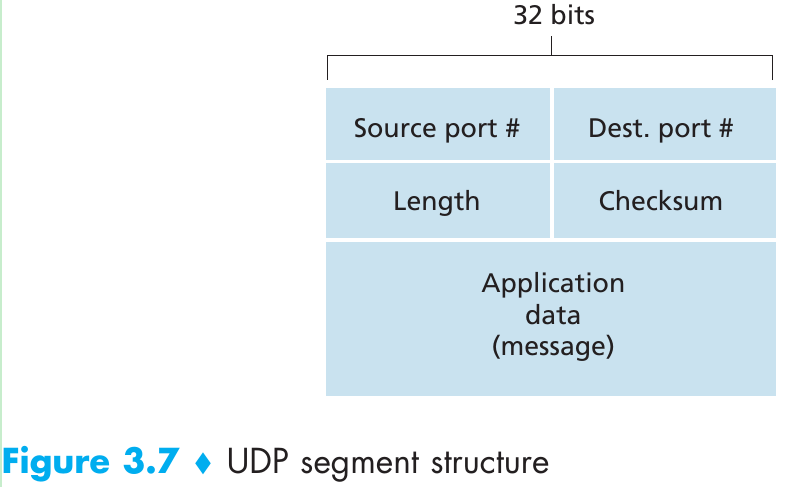
- The UDP header has four fields, each consisting of two bytes.
- The port numbers allow the destination host to pass the application data to the correct process running on the destination end system (that is, to perform the demultiplexing function).
- The length field specifies the number of bytes in the UDP segment (header + data). An explicit length value is needed since the size of the data field may differ from one UDP segment to the next.
- The checksum is used by the receiving host to check whether errors have been introduced into the segment and it is also calculated over a few of the fields in the IP header in addition to the UDP segment.
- The application data occupies the data field of the UDP segment. For example, for DNS, the data field contains either a query message or a response message.
3.3.2 UDP Checksum
- The checksum is used to determine whether bits within the UDP segment have been altered as it moved from source to destination.
- UDP at the sender side performs the 1s complement of the sum of all the 16-bit words in the segment, with any overflow encountered during the sum being wrapped around. This result is put in the checksum field of the UDP segment.
- Suppose that we have the following three 16-bit words:
0110011001100000
0101010101010101
1000111100001100
The sum of first two of these 16-bit words is
0110011001100000 + 0101010101010101 = 1011101110110101
Adding the third word to the above sum gives
1011101110110101 + 1000111100001100 = 0100101011000010
Note that this last addition had overflow, which was wrapped around. - The 1s complement is obtained by 0 -> 1, 1 -> 0. Thus the 1s complement of the sum 0100101011000010 is 1011010100111101, which becomes the checksum.
- At the receiver, all four 16-bit words are added, including the checksum. If no errors are introduced into the packet, then clearly the sum at the receiver will be 1111111111111111. If one of the bits is a 0, then we know that errors have been introduced into the packet.
- Why UDP provides a checksum in the first place, as many link-layer protocols (e.g.: Ethernet protocol) also provide error checking.
-
- The reason is that there is no guarantee that all the links between source and destination provide error checking; that is, one of the links may use a link-layer protocol that does not provide error checking.
-
- Furthermore, even if segments are correctly transferred across a link, it’s possible that bit errors could be introduced when a segment is stored in a router’s memory.
-
- Given that neither link-by-link reliability nor in-memory error detection is guaranteed, UDP must provide error detection at the transport layer, on an end-end basis, if the end-end data transfer service is to provide error detection. Because IP is supposed to run over just about any layer-2 protocol, it is useful for the transport layer to provide error checking as a safety measure.
- Although UDP provides error checking, it does not do anything to recover from an error. Some implementations of UDP simply discard the damaged segment; others pass the damaged segment to the application with a warning.
3.4 Principles of Reliable Data Transfer
- The service abstraction provided to the upper-layer entities is that of a reliable channel through which data can be transferred. With a reliable channel, no transferred data bits are corrupted or lost, and all are delivered in the order in which they were sent. It is the responsibility of a reliable data transfer protocol to implement this service abstraction.
- This task is made difficult by the fact that the layer below the reliable data transfer protocol may be unreliable. For example, TCP is a reliable data transfer protocol that is implemented on top of an unreliable (IP) end-to-end network layer.
- Assumption: packets will be in the order in which they were sent, with some packets possibly being lost; that is, the underlying channel will not reorder packets.
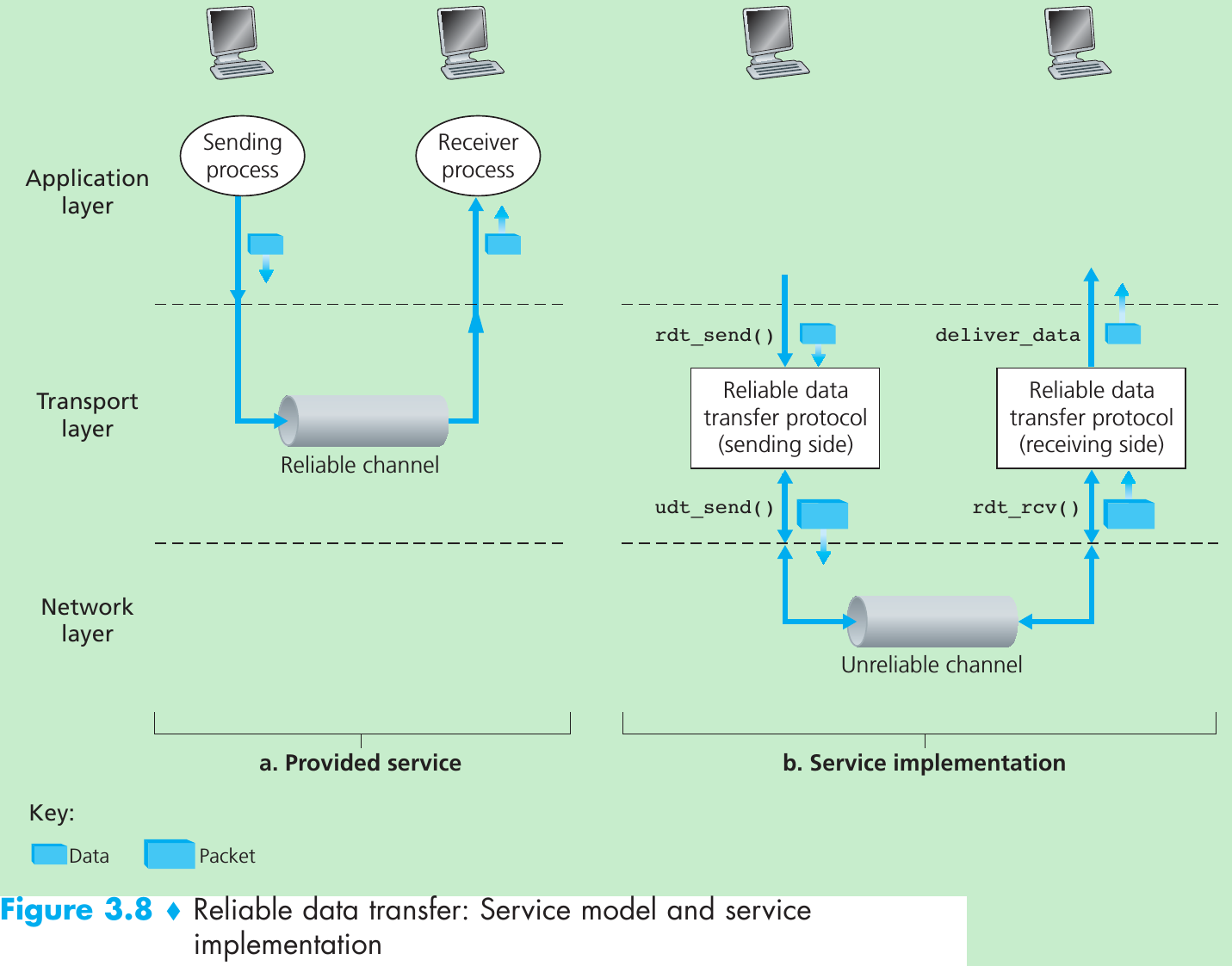
- Figure 3.8(b) illustrates the interfaces for our data transfer protocol. The sending side of the data transfer protocol will be invoked from above by a call to rdt_send(). It will pass the data to be delivered to the upper layer at the receiving side. (rdt: reliable data transfer protocol; rdt_send: the sending side of rdt is being called.)
- On the receiving side, rdt_rcv() will be called when a packet arrives from the receiving side of the channel. When the rdt protocol wants to deliver data to the upper layer, it will do so by calling deliver_data().
- In addition to exchanging packets containing the data to be transferred, the sending and receiving sides of rdt will also need to exchange control packets back and forth. Both the send and receive sides of rdt send p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









