







日常的应用中,我们会很经常遇到一个问题:
如何应用强大的model(比如ResNet)去训练我们自己的数据?
考虑到这样的几个事实:
- 通常我们自己的数据集都不会大(<1w)
- 从头开始训练耗时
解决方法就是fine-tuning.
方式
参考CS231的资料,有三种方式
- ConvNet as fixed feature extractor.
其实这里有两种做法:
(1) 使用最后一个fc layer之前的fc layer获得的特征,学习个线性分类器(比如SVM)
(2) 重新训练最后一个fc layer- Fine-tuning the ConvNet.
固定前几层的参数,只对最后几层进行fine-tuning- Pretrained models.
这个其实和第二种是一个意思,不过比较极端,使用整个pre-trained的model作为初始化,然后fine-tuning整个网络而不是某些层
选择
考虑两个问题:
- 你的数据集大小
- 你的数据集和ImageNet(假设在ImageNet上训练的)的相似性
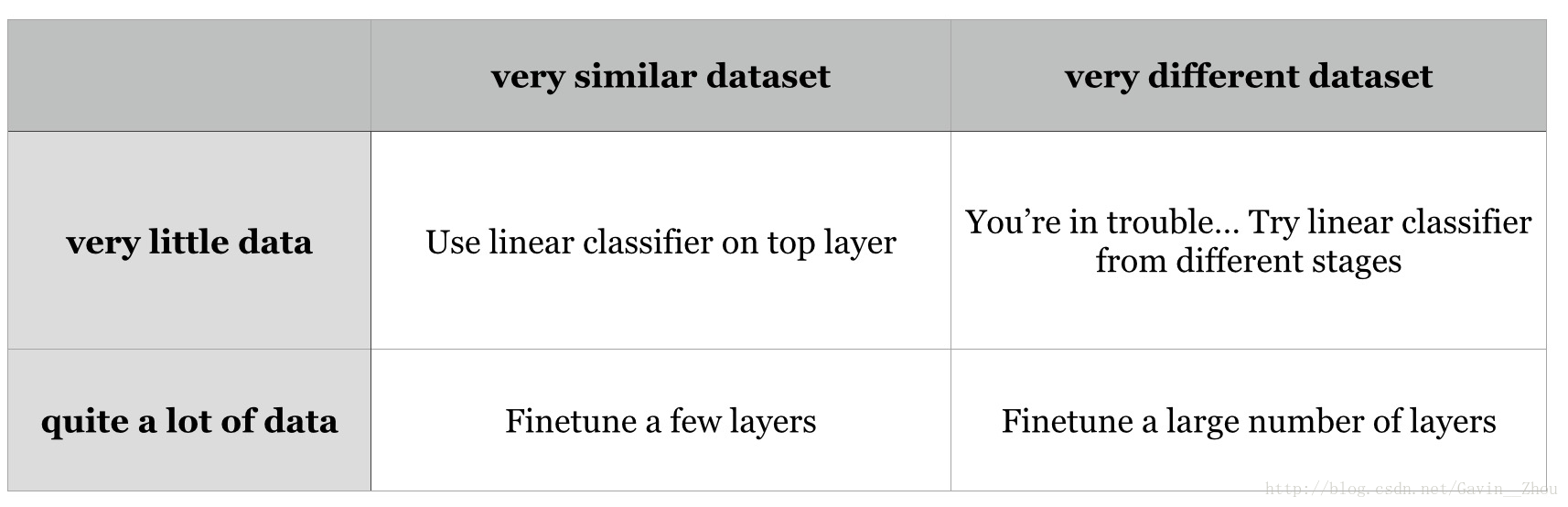
分为四种情况,解决方法基于的原则就是:
NN中的低层特征是比较generic的,比如说线、边缘的信息,高层特征是Dataset Specific的,基于此,如果你的数据集和ImageNet差异比较大,这个时候你应该尽可能的少用pre-trained model的高层特征.
数据集小(比如<5000),相似度高
这是最常见的情况,可以仅重新训练最后一层(fc layer)
数据集大(比如>10000),相似度高
fine-tuning后几层,保持前面几层不变或者干脆直接使用pre-trained model作为初始化,fine-tuning整个网络
数据集小,相似度低
小数据集没有办法进行多层或者整个网络的fine-tuning,建议保持前几层不动,fine-tuning后几层(效果可能也不会很好)
数据集大,相似度低
虽然相似度低,但是数据集大,可以和2一样处理
从上面我们可以看出,数据集大有优势,否则最好是数据集和原始的相似度比较高;如果出现数据集小同时相似度低的情况,这个时候去fine-tuning后几层未必会有比较好的效果.
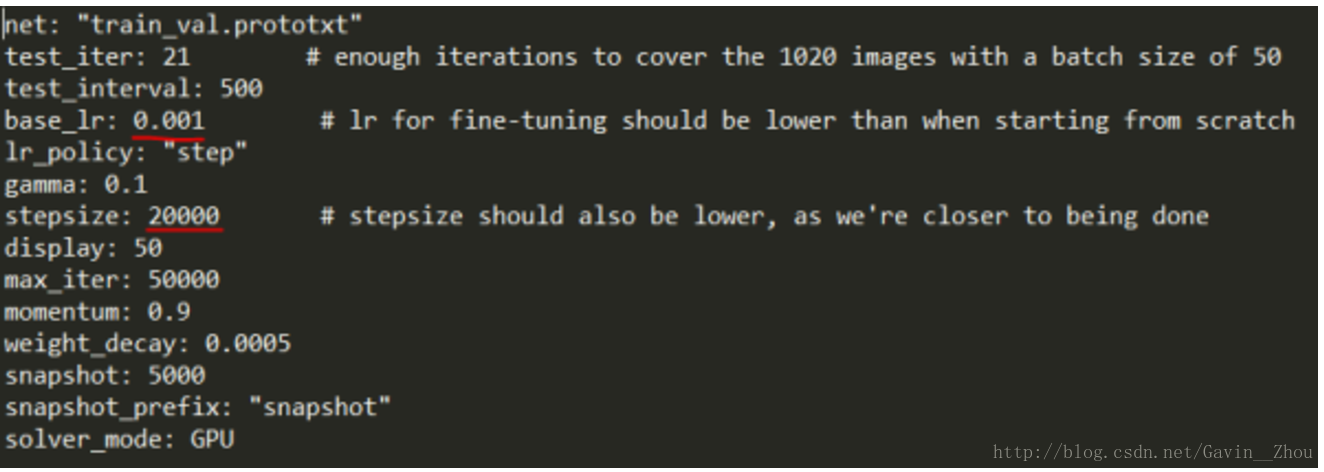
Caffe中如何进行fine-tuning
Caffe做fine-tuning相对tensorflow很简单,只需要简单修改下配置文件就行了.
此处假设你的数据集比较小,同时相似度比较高,仅需重新训练最后一层(fc)的情况.
(1) 降低solver中lr和stepsize
这个很明显,因为相似度比较高我们可以期望原始获得的feature和需要的是很接近的,此时需要降低学习率(lr)和迭代次数(stepsize).
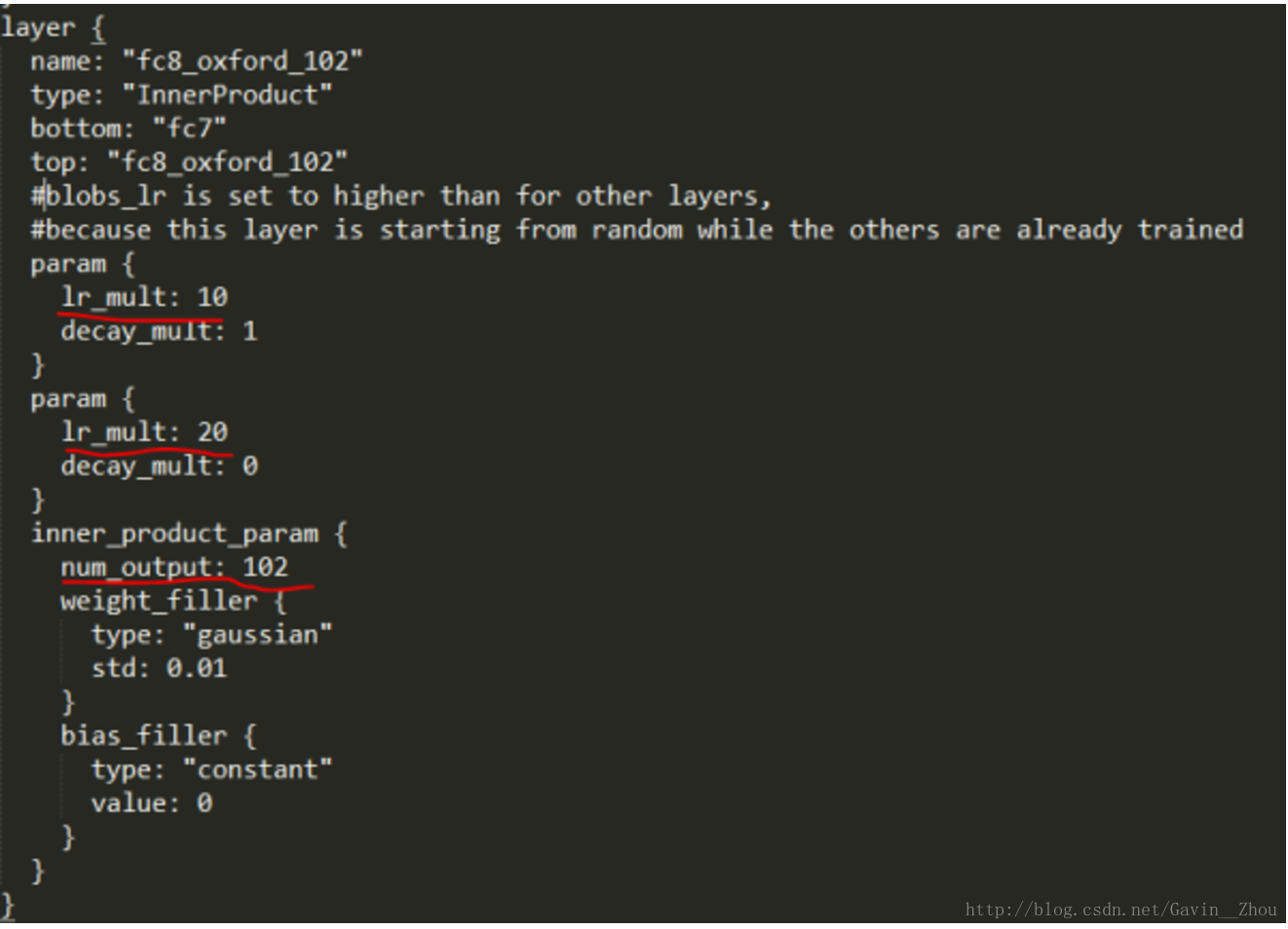
(2) 修改最后一层fc的名字,设置好lr_mult
应为需要训练最后一层,我们把之前的层的学习率设置的很低(比如0.001),或者你干脆设置为0,最后一层设置一定的学习率(比如0.01),所以需要乘以10.
(3) 训练
其实就已经改好了,是不是很简单,按照之前标准化的训练测试就好了
知乎上fine-tuning的介绍上有更加详细的介绍,可以移步去看.
参考
(1) NodYoung的博客















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









