







Wen Zhou
可解释性表示模型可以利用人类可认知的说法进行的解释和呈现。机器学习模型本身是一个黑盒,我们虽然可以从中获得准确的预测,但是我们无法清楚地看到背后的逻辑,这就比如软件测试中的黑盒测试,用户可以输入,但是看不到程序中间的运行过程。
模型的解释方法是为了让我们更好地了解过程,如何从模型中提取到重要的和主要的模型解释是我们关注的问题。
可解释机器学习近年来的发展:可解释人工智能被列为数据和分析技术领域的前10个重要趋势之一。2018年,欧洲强调对科技是机器学习的追求,谷歌微软百度等人工智能内的top企业近年来也对可解释学习相关技术的研究。
图1 可解释机器学习模型运行图
如上图1,可解释机器学习模型认为模型是一样黑盒子,研究者无法看到他在具体场景中的运算原理以及过程机制。近年来知识图谱、自然语言处理、计算机视觉等应用于我们的生活,我们渐渐的对人工智能产生了依赖,无人驾驶、智能交通系统、航天航空等都在应用,但如果AI在学习过程中犯错,我们如何找到Ai的犯错点呢?
工业领域需要现有的可应用的模型的解释才可以落地到相关的领域应用
解释方法有助于知识的表现和发现,在知识图谱、医疗、交通等多个领域中可解释发挥着重要的应用。
这里简单举例:
1.一阶段的目标检测算法如果无法精准检测到目标物体,会导致该算法在落地后对落地的领域造成损失。
2.高校教师发现学生的期末考试成绩和学生是否带手机上课有重大的关系
3.力扣刷题发现只要在检测用例和时间复杂度、空间复杂度三者要求都符合的情况下,机器验证代码通过
研究AI的脑回路,即研究AI的本质
可解释分析是机器学习和数据挖掘的通用研究方法
和所有AI方向交叉融合: 数据挖掘、计算机视觉、自然语言处理、强化学习、知识图谱、联邦学习。
包括但不限于:大模型、弱监督、缺陷异常检测、细粒度分类、决策AI和强化学习、图神经网络、AI纠偏、A14Science、MachineTeaching、对抗样本、可信计算、联邦学习
目前,数据挖掘我们上面也对它的十大常用算法进行了介绍,对于研究者而言,我们无法看到算法在处理的过程中的它的内部运处理原理,通过可解释机器学习,研究者可探索到算法的运行原理和算法在处理数据过程中的关键处理,通过可解释机器学习,研究者可以更加清晰地对算法做到完整的理解,帮助研究者对算法进行改进,从而为产品的落地和产品的效益产生良好的效益。
可解释机器学习主流算法
CAM
CAM热力图可视化方法是一种常用于探索卷积神经网络的技术,通过CAM热力图可视化技术我们可以对深度学习进行可解释探索,深度学习网络是一个黑箱子,通过CAM我们可以探索到图像分类网网络这个黑盒子
CAM热力图的可视化分析主要原理如下:
CAM首先进行特征提取,但是CAM并没有使用池化层,池化层在深度学习模型中主要用于下采样,会导致提取到的特征缺少,而CAM他是要探索算法检测图像的时候的关注点,比如算法检测一只猫,而CAM探索的时候,它主要探索猫,对猫进行热力图显示,热力图成像主要集中于猫出现的像素位置。
CAM相关的网络结构如下:
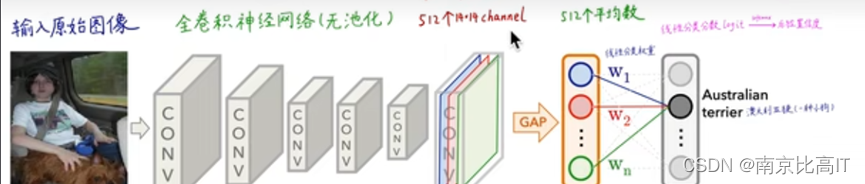
图2 CAM网络结构图
CAM的热力图算法很惊人,图文中GAP主要是未来防止梯度爆炸,得到全局平均化GAP,而softamax的计算来自于前面的通道计算得到,不同的颜色线性点来自于相对应的颜色的通道矩阵,使用1000个矩阵*1000个通道得到对应的热力图。

图3 CAM得到的热力图
观察上图,你会发现,目标分类器为什么可以识别到狗,通过CAM热力图算法,会发现目标分类器所感兴趣的点和所关注的特征点,从而完成相对应的识别,通过学习,是不是可以为我们打开我们研究的计算机视觉领域的黑盒子和探索到算法的不足点
GAP:全局平均池化,得到的特征相对于最大池化层降低了最大池化层的损失。
CAM具有以下优点:
对深度学习实现可解释性分析、显著性分析
可扩展性强,后续衍生出了各种基于CAM的算法
每张图片、每个类别,都可以生成CAM热力图
弱监督分类:可帮助图像分类模型解决定位问题
潜在的注意力机制的探索
使得Machine Teaching成为可能
那么我们可以使用它做什么呢?
首先,是不是可以进行算法的缺陷探索,比如使用它探索SSD、RCNN等算法的缺陷问题。
其次,是不是可以针对注意力机制进行探索,比如RCNN我们使用一种注意力机制,但我们可以做一个消融实验,我们再使用另一种注意力机制,然后我们对比实验,同时同时进行CAM热力图可视化分析得出关键的问题。
第三,分析每张图片或者一些检测效果不好的类别,进行CAM热力图可视化分析,对比目标分类器所关注的或者识别的关键特征,尝试使用相关类别进行优化。
GRAD-CAM[1]
GRAD-CAM[1]基于流入CNN的最后一个卷积层的梯度信息为每个神经元分配重要值,以便于进行特定的关注决策。下图为GRAD-CAM在小狗图像上的效果图,可以发现,他不仅做了常规的可解释性可视化,而且进行了基于遮挡的可解释性可视化,可见GRAD-CAM的模型表现效果是不错的。

图4 GRAD-CAM在小狗上的效果图
如下图,Grad-CAM不仅可以用于图像分类,同时还可以进行图像信息的解释性说明,以及可视化问题答案,也就是说,他不仅可以用于图像分类任务,还可以用于强化学习、自然语言处理、图像信息提取等众多的领域。
下图中,输入图像进行特征提取后,通过激活函数和全连接层计算出每一个像素点的权重,通过激活函数,得到可视化的热力图解释,Grad-CAM不需要使用GAP层,切可用于更多的领域,最后的得到的Grad-CAM的可解释性分析图是基于Guided Backprop和Grad-CAM矩阵信息相乘得到的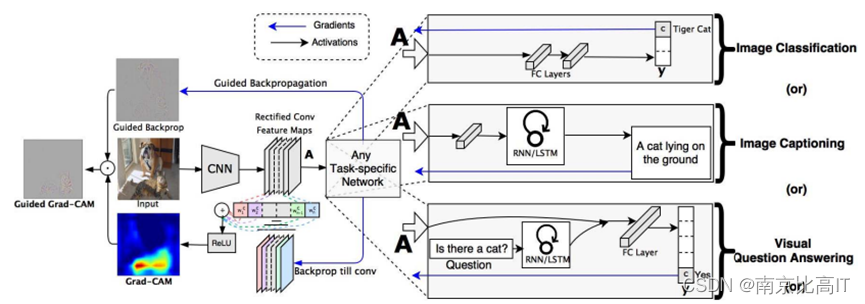
图5 GRAD-CAM算法运行图
下图公式为全局平均池化层之后得到的特征权重,这个公式中求梯度的计算可见这里为负,这里具有一个奥妙在于这个正负会产生不一样的结果,负号会使得我们的模型算法他关注你想要的我相反的特征,比如你想要探索猫,那现在梯度取了负号,算法所关注的会变成出了猫之外图像中的其他部分。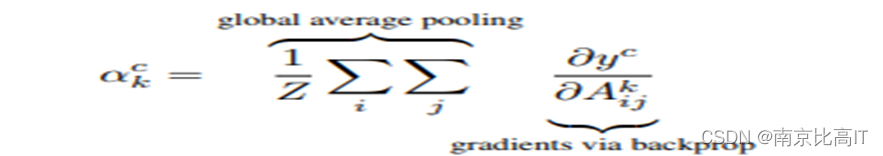
图6 全局平均池化层后的特征权重计算图
Grad-CAM尽管解决了CAM的部分缺点,但他依然存在缺点:
只关注了反向梯度下降,并没有关注前向计算
在每一个图像中,只能产生和关注一个对象,不能关注多个
对部分敏感位置的定位效果不太好,鲁棒性已经很不错但还有提高空间。
但是Grad-CAM的前景十分良好,除了Grad-CAM之外,还有Score-CAM,Layer CAM等卷积可解释性算法。
LIME[2]
LIME的产生背景
现今的数据挖掘领域中,机器学习模型被广泛使用。传统的机器学习模型更关注预测效果,追求更高预测精准度和更快的训练速度。然而,机器学习模型的“黑盒”属性导致了其内部工作原理难以被理解,输入与输出之间往往存在极其复杂的函数关系。当模型应用到银行业等金融领域时,透明度和可解释性是机器学习模型是否值得信任的重要考核标准。我们需要告诉业务人员如何营销,告诉风控人员如何识别风险点,而不仅仅告诉他们预测的结果。一个预测表现接近完美、却属于黑盒的人工智能模型,会容易产生误导的决策,还可能招致系统性风险,导致漏洞被攻击,因而变得不安全可靠。例如在银行消费者贷款领域,美国联邦政府颁布的平等信贷机会法(ECOA)明确要求各家银行在拒绝每个消费者申请信用卡时,必须明确说明拒绝的理据。因此,应用复杂的机器学习模型时,我们需要构造一个“解释器”,对模型的预测结果进行事后归因解析,而 LIME 便是一个很好的事后解释方法。
LIME介绍
LIME[2]全称 Local Interpretable Model-Agnostic Explanations,由 Marco Ribeiro, Sameer Singh 和 Carlos Guestrin 三个人在 2016 年《“Why Should I Trust You?” Explaining the Predictions of Any Classififier》这一文中提出来的,是一种事后解释方法,即在建立模型之后所做的解释,其名称也很好的反应了它的特点:
Local: 基于想要解释的预测值及其附近的样本,构建局部的线性模型或其他代理模型;
Interpretable: LIME 做出的解释易被人类理解。利用局部可解释的模型对黑盒模型的预测结果进行解释,构造局部样本特征和预测结果之间的关系;
Model-Agnostic: LIME 解释的算法与模型无关,无论是用 Random Forest、SVM 还是 XGBoost 等各种复杂的模型,得到的预测结果都能使用 LIME 方法来解释;
Explanations: LIME 是一种事后解释方法。
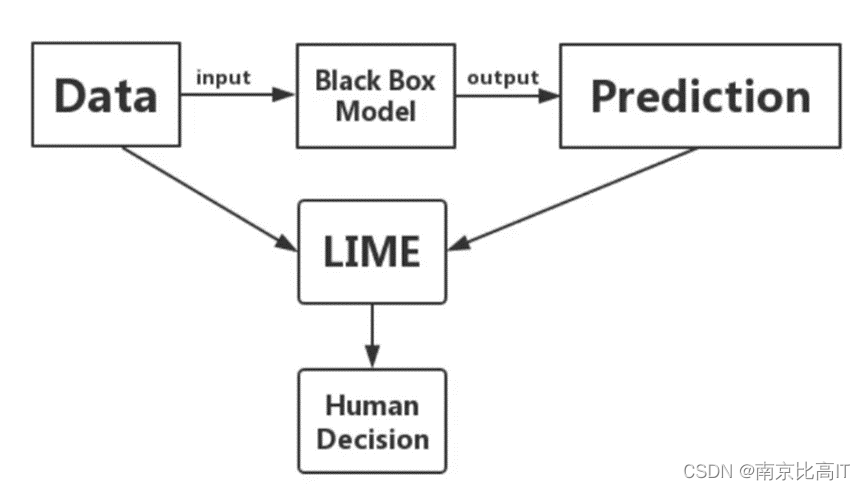
图7 LIME运行原理图
LIME 可处理不同类型的输入数据,如表格数据(Tabular Data)、图像数据(Image Data)或文本数据(Text Data)。对于表格数据,如用银行客户行为数据预测理财产品销售,训练完复杂模型后可以用 LIME 得到哪些特征影响理财产品销售;图像数据,如识别图片中的动物是否为猫,训练完复杂模型后可以用 LIME 得到图片中的动物被识别为猫是因为哪一个或几个像素块;文本数据,如识别短信是否为垃圾短信,训练完复杂模型后可以用 LIME 得到一条信息被判断为垃圾短信是因为哪一个或几个关键词。
算法总结
算法优点:
(1)LIME可以应用到多个场景中,不仅仅可以对卷积神经网络中的图像分类,而且还可以应用到自然语言处理(NLP)当中。而LIME算法它与模型无关,他的可用性强
(2)LIME算法可以给出一个相关的可信度量,可以作为模型可靠的评估指标
(3)LIME还可以对训练的模型的特征数据中未出现过特征数据进行解释
缺点:
算法在发生数据扰动时,样本服从高斯分布,忽略了特征之间的相关性。
LIME算法速度慢,LIME在完成采样完成后,采样出来的图片都要经过原模型预测的结果,所需的时间复杂度比较高
可解释机器学习在数据挖掘中的应用
上面我们介绍了可解释机器学习的主要算法,下面我们来对可解释机器学习在数据挖掘中的应用来进行探究:
数据挖掘的目的主要是从数据中心挖掘出有价值的知识。目前,互联网每天产生大量的数据,而其中许多数据是无效的数据,但每天产生的数据中存在非常有价值的知识,工业界和学术界为了发现这些知识,研究者基于商务智能相关的技术完成知识的发现,为商业和研究带来一定的效益影响。
基于可解释机器学习算法,对数据挖掘算法进行可解释分析,研究者可以发现算法内部对他们研究对象的处理的相关过程和关键点,从而发现所选择的算法在他们的实际应用中的不足和可改进点。
现实中,许多的商业问题在基于数据挖掘完成相关的产品增益时,存在技术的落地的困难,研究者所使用的数据挖掘技术可能不能落地,或者落地时存在的困难比较大。而可解释机器学习可以通过对数据挖掘所选择的模型进行探索,来得到模型对实际问题的解释,从而在一定程度上,可以帮助研究者完成设计的数据挖掘模型的落地和改进。
所以,可解释机器学习可以应用于数据挖掘中的模型解释、模型的原理探究、模型对数据的关注点探究,以及在以及落地的模型上的解释。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











