






最近在写一篇论文时用到了topic modeling的方法,为了更具创新性,就打算实现基于topic modeling的automatic topic labeling。也就是,给topic models的结果自动总结出意思,而不需要人工揣摩。这一类的文章已经有很多,下面就对这些文章进行一下总结。
-(1) Automatic Labeling of Topic Models ——2011
这篇文章提出了自动给LDA学习的话题添加标签的方法。标签候选集(label candidate set)从top-ranking的topic terms,含有这些terms和sub-phrases的Wikipedia titles中获得。本篇文章是Lau et al. (2010)的最佳topic term选择的后续。在之前的那篇文章中,作者用了reranking的框架基于每个term单独表现主题的强弱,生成了top-10的topic terms的排序。比如说,stock market investor fund trading 这个话题实例,term trading 被认为是一个比term stock更能代表整个话题意义的一个词。尽管我们可以用best term来作为一个topic的label,但是topics最好是多个terms表现出来的总体的idea或者concept,或者那些不在top 10的terms (比如,colors是topic red green blue cyan.... 的好标签)。
这篇文章中,作者首先用English Wikipedia生成了topic label candidates,然后对这些candidates进行排序,进而选出最佳的topic labels。
- Candidate 生成
假设: Wikipedia article包含大量的topics或者concepts
任务: 找到相关的Wikipedia articles,并用每个article的title作为一个topic label candidate.
Step1: 用top 10 的topic terms在Wikipedia中进行搜索,采用:a. Wikipedia的原始搜索API,和b. site-restricted的谷歌搜索。从这两种搜索引擎上返回的top 8的文章titles组成了primary candidates的初始集合(initial set)。
Step2: 用OpenNLP chunker来解析primary candidates,并提取所有的noun chunks。对于每一个noun chunk,生成所有的组成n-grams (包括full chunk),从中删掉title本身。比如,Wikipedia文章title为单独的noun chunk:United States Constitution ,我们可以生成bigrams United States 和States Constitution ;也可以生成unigrams United, States 和Constitution 。这样,基于noun chunk n-gram, 平均每个topic可以有30-40个secondary lables 。
为了移除outlier labels,作者采用RACO lexical association method (Grieser et. al. 2011)。RACO (Related Article Conceptual Overlap)采用Wikipedia的link structure和category membership来识别文章之间联系的强度。这种识别基于category的重叠程度。与一篇文章相关的category集定义为这篇文章所有外部链接的category membership的并集。两篇文章(a和b)的category重叠是这两篇文章category集合的交集,可以规范为如下表示:
其中 O(a) 文章a的外部链接集合, C(p) 文章 p 的category集合。之后,用Dice’s coefficient来正则化得到相似性度量。每个secondary label的最终得分为每个primary label candidate 的平均RACO score。所有得分大于等于0.1的secondary label 被加到label candidate set。
Step3:
排在原始topic model marginals中Top 5的topic terms被加到candidate集合中,这样可以保证label candidates不为空集,即便Wikipidia搜索失败,并允许用本身的topic terms来作为topic的标签(这在Lau et al. 2010中作为topic label candidates的基本来源)。
- Candidate 排序
在获得topic label candidates集合后,下一步就是对这些candidates进行排序找到每个topic的最佳label。
特征提取:
一个好的label应该与topic terms有很强的关系。为了学习label candidate与topic term的关系,作者采用了几个lexical association measures: pointwise mutual information (PMI), Student’s
除了association measures之外,还有candidate的两个lexical特性:terms的原始数量和top 10的topic terms的相关terms。
非监督性排序和监督性排序
任何提出的特征都可以用作选择label candidate的非监督性模型的基础。同时,通过训练我们已经label好的topic,可以将它们结合进监督性模型。对于监督性方法,作者使用一个support vector regression (SVR)模型。
-数据集
BLOGS: 120,000 Sprinn3r blog dataset (2008.08 - 2008.10)
BOOKS: 1,000 English language books from the Internet Archive American Libraries collection
NEWS: 29,000 New York Times news articles (1999.07 - 1999.09)
PUBMED: 77,000 PubMed biomedical abstracts (2010.06)
-实验
对上述四个文档集合采用经典的topic modeling方法。预处理:tokenised,lemmatised,去除stop words,创建了一个每个term至少出现10次以上的vocabulary。对于处理后的数据,我们对每一个文档创建了bag-of-words表示,并得到T=100个topics。
为了使实验结果更合理,作者首先采用Newman et al. (2010b)的方法计算每个topic的平均PMI-score,并过滤掉所有低于0.4的topic。此外过滤掉top 10的term少于5个在Wikipedia是默认名词的topic。人工检查舍弃的topic发现,它们主要是很难label的垃圾topic或者语义混合的topic,对文档或者term聚类的作用有限。
-(2) Automatic Labeling of Multinomial Topic Models——2009
本文提出了一个概率方法来自动地客观地给多分布的主题模型添加标签。文章将加标签问题看做是包含最小化Kullback-Leibler 离散和最大化标签与主题模型间互信息(mutual information)的优化问题。
对一个话题来说什么是好的标签(label)?
- 一个好的标签应该能被用户理解;
- 可以抓住话题的意思
- 与其它话题区分开
对于话题标签来说,有很多选择,比如说单个词(single terms),词组(phrases)或者句子(sentences)。但是从下表中可以看出,single terms通常太宽泛,用户很难理解术语的综合意义。sentence比较特定,难以准确地描述话题的总体意义。介于这两种极端之间,phrase对用户来说足够合理和具体,并且可以体现话题的总体意思。事实上,人们人工label的时候也会偏爱phrase。这篇文章提出了一个概率方法自动给topic添加有意义的phrase标签。
-问题定义
Definition 1 (Topic Model) A topic model
θ
in a text collection
C
is a probability distribution of words
Definition 2 (Topic Label) A topic label, or a “label“,
l
, for a topic model
Definition 3 (Relevance Score) The relevance score of a label to a topic model,
s(l,θ)
, measure the semantic similarity between the label and the topic model. Given that
l1
and
l2
are both meaningful candidate labels,
l1
is a better label for
θ
than
l2
if
s(l1,θ)>s(l2,θ)
.
有了上面的这些定义,
TopicModelLabeling
的问题可以定义为:
给定从文本集中提取的topic model
θ
,single topic model labeling 问题是:
- 识别一组candidate labels L=l1,..., ;
- 设计相关性评分函数 s(li,θ) 。
有了
L
和
在一些场景下,我们有一组很好的可以接受的candidate labels (比如,生物话题的Gene Ontology entries)。但是,在大多数情况下,我们没有这样的candidate set。因此,解决topic labeling问题的工作流程是:
- 从reference collection里面提取一组candidate labels;
- 找到一个好的相关性评分函数;
- 使用分数来给每个topic model的candidate label排序;
- 选取分数最高的几个来label相关的话题。
-Probabilistic Topic Labeling
一个话题的好的label应该:1)易于理解的(understandable);2)语义相关的(semantically relevant);3)很好地覆盖到整个话题(covering the whole topic well);4)区分各个话题(discriminative across topics)。
Generate Candidate Label
有两种基本的方法:- Chunking/shallow Parsing:一个chunker通常在有(词性标记) part of speech tags的文本上操作,根据一些语法用标记(tags)来确定是否切块(chunking),或者通过有标签的训练集来学习。优点是:生成的词组是符合语法规则的并且有意义。缺点是:分块的准确度很大程度上依赖于文本集的领域。
- Ngram Testing:另外一种方法是基于统计测试从word ngrams中提取有意义的词组。它的基本观点是如果一个ngram趋向于同其它的一起出现,那么这个ngram很可能是一个n-word的phrase。有许多方法来测试一个ngram是否有意义。一些方法基于统计测试如互信息,一些基于hypothesis testing techniques( χ2 Test和Student’s T-Test)。优点是不需要训练集,适用于任何自主领域/话题的文本集。缺点是排在前面的ngram有时候并没有意义,通常bigram比较有效。
Semantic Relevance Scoring
- The Zero-order Relevance
一种可能是定义candidate phrase l=u0u1⋯um ( ui 是一个单词)的semantic relevance score如下:
Score=logp(l|θ)p(l)=∑0≤i≤mlogp(ui|θ)p(ui) ,
其中,我们假定 ui 之间是互相独立的。
- The Zero-order Relevance
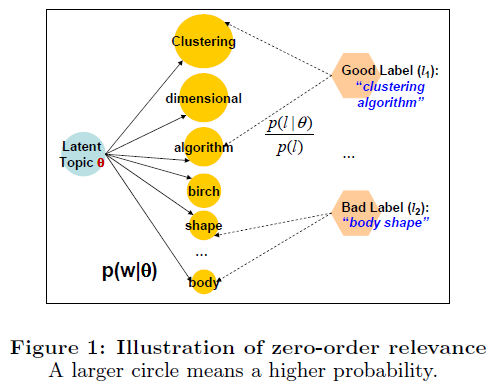
此方法的基本思想如上图。 p(w|θ) 越大表示这个词组越重要,那么就是一个好标签。 p(ui) 是为了调整支持短词组的偏好,可以从一些background collection中估计,或者简单地设成均匀分布。
尽管这个方法简单并且易于理解,但是标签的语义信息被忽略了,而且整个话题分布的信息没有被充分利用。
-
- The First-order Relevance
为了能考虑到一个话题的整体分布,需要考虑到上下文信息。假定还存在一个有标签 l 决定的多项式分布p(w|l) ,用Kullback-Leibler (KL) divergence D(θ||l) 来衡量 p(w|l) 和 p(w|θ) 的相似度。如果 l 是话题θ 的一个好标签,divergence则为0.基本思想如图:
- The First-order Relevance
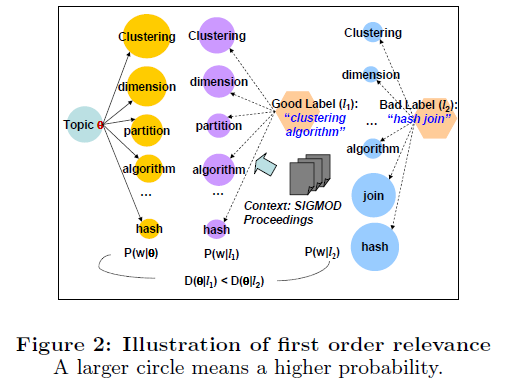
估计
p(w|l)
的一种方法是包含一个context collection
C
,用估计
-
Relevance Scoring Function
label l 与主题模型θ 之间的相关性评分函数为 p(w|θ) 和 p(w|l) 之间的负KL离散。基于给定的文本情境 C ,评分函数可写为:
Score(l,θ)=−D(θ||l)=−∑wp(w|θ)logp(w|θ)p(w|l)=∑wp(w|θ)PMI(w,l|C)−D(θ||C)+Bias(l,C)
PMI(w,l|C) 可以通过要被label的主题模型单独计算。这个相关函数为first-order relevance of a label to a topic。Intuitive Interpretation
PMI(w,l|C) 通常被用来衡量语义关联度。如下图所示,为一个加权图,每个点是一个topic model里面的一个term (权重为 p(w|θ) )或者是一个candidate label。lable和topical term间边的权重是点互信息(pointwise mutual information) PMI(w,l|C) 。所以,每个点的权重表示一个term对一个topic的重要程度,每个边的权重表示label和term的语义关联度。
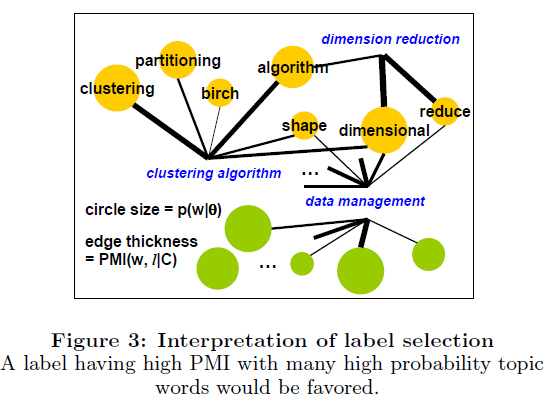
评分函数 Eθ(PMI(w,l|C)) 把这些与重要的topical words有较强的语义关联的label排在前面。直觉上,这样选出的lables能很好地覆盖整个topic model。
High Coverage Labels
当选定多个labels时,我们当然想新的label能cover topic的不同方面,而不是选择被已有的labels覆盖的信息。这里,作者用Maximal Marginal Relevance (MMR) criterion来衡量lables的覆盖情况。MMR经常在IR领域使用,用来得到高相关性,低冗余度的结果。
l^=argmaxl∈L−S P(λScore(l,θ)−(1−λ)maxl′∈S Sim(l′,l))
其中, S 是已经选定的label集,Sim(l′,l)=−D(l′||l)=−∑wp(w|l′)logp(w|l′)p(w|l) , λ 是由实验决定的参数。Discriminative Labels
原则上,一个好的label应该与目标topic model有较高的语义相关性,与其他的topic models有较低的相关性。改进后的评分函数:
Score′(l,θi)=Score(l,θi)−μScore(l,θ1,⋯,i−1,i+1,⋯,k) ,
其中 θ1,⋯,i−1,i+1,⋯,k (简短地标记为 θ−i )是由除了 θi 之外其它的topics所含的语义, μ 控制区分程度。最终:
Score′(l,θi)≈(1+μk−1)Eθi(PMI(w,l|C))−μk−1∑j=1,⋯,kEθj(PMI(w,l|C))))
最终的 Score′(l,θ) 对label排序,从而使不同的topic models的label不同。















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









