







计算图
定义:使用计算图来表示任意函数,其中图的节点表示我们要执行的每一步计算。
好处:使用计算图来表示一个函数,就能使用反向传播技术递归地调用链式法则来计算一下计算图中每个变量的梯度。当涉及到非常复杂的函数时,这种方法非常有用。
例子
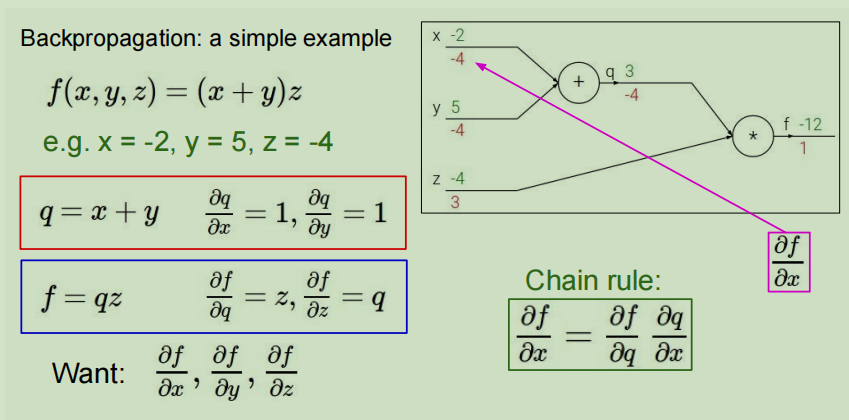
对于函数 f ( x , y , z ) = ( x + y ) z f(x,y,z) = (x+y)z f(x,y,z)=(x+y)z,其中x=-2,y=5,z=-4
- 用计算图表示整个函数
- 向前传播计算中间变量的梯度
- 从后往前,根据链式法则和向前传播得到的中间梯度计算梯度
链式法则,比如计算 ∂ f ∂ y = ∂ f ∂ q ∂ q ∂ y \dfrac{\partial f}{\partial y} = \dfrac{\partial f}{\partial q}\dfrac{\partial q}{\partial y} ∂y∂f=∂q∂f∂y∂q,由于f和y没有直接的关系,但是可以利用链式法则,通过q得到结果。
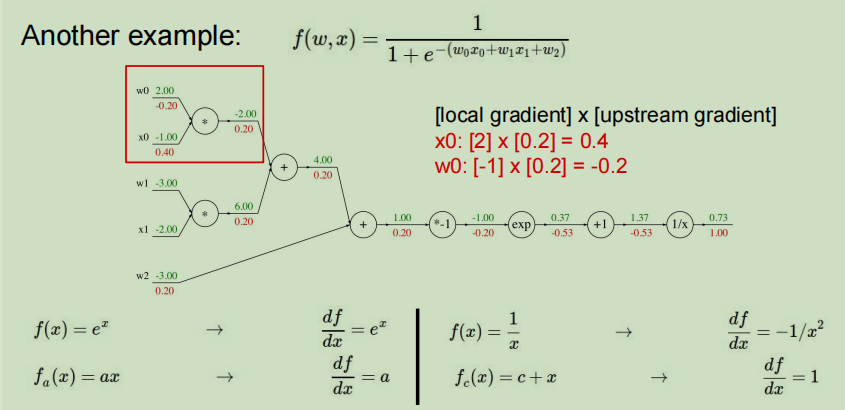
图中绿色的值是传入的参数值和计算图向前计算得到的值,红色值是利用计算图反向计算时得到的梯度值
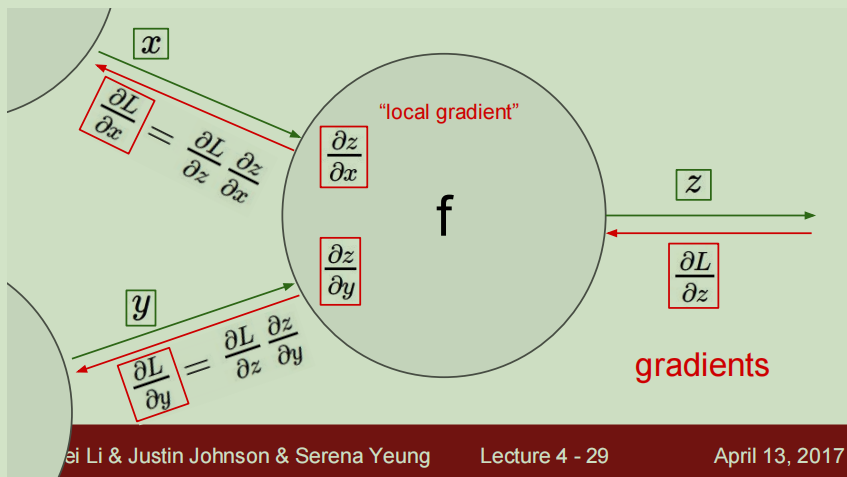
节点
对于一个节点,计算本地梯度并存储跟踪下来,在反向传播过程中接收从上游传过来的梯度值,然后直接利用这个值乘以本地梯度就可以得到连接点的梯度值,就可以将连接点的结果传入前面的节点,那么在下一个节点进行传播时,不用考虑除了直接相连的节点之外的任何东西。
例如这个图中,x和y是前面的节点传入该节点的值,z是节点的输出值,进行反向传播时,从输出方向传入上游的梯度值,我们只需要将在向前传播过程中计算好的梯度值(即本地梯度)和从上游传过来的梯度值利用链式法则相乘即可得到我们想要的结果,再将这个结果传入到前面的直接相连的节点中去。
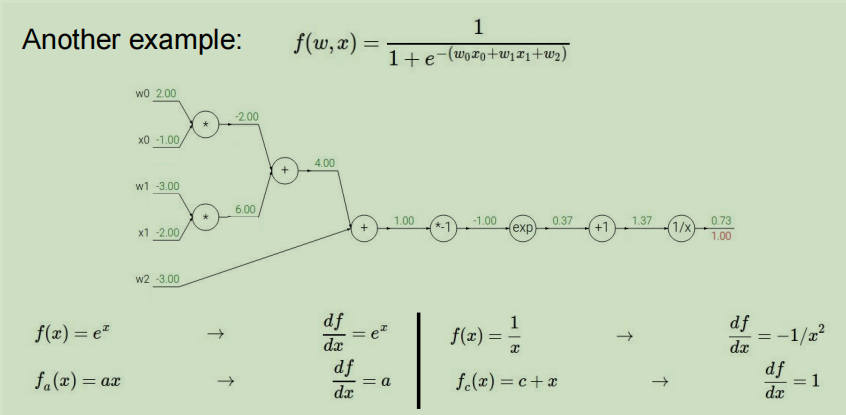
详细的计算过程例子
第一步:画出计算图并向前传播计算,写下中间的一些微分方程式
第二步:从末端开始进行反向传播
对于节点1/x
其中df/df等于1,然后进行节点1/x的计算,上游传过来的梯度值为1,该节点的本地梯度利用向前传播时记录下来的微积分公式和参数值即可求得,本地梯度为 d f d x = − 1 x 2 \dfrac{df}{dx}=\dfrac{-1}{x^2} dxdf=x2−1,x的值为1.37,那么计算出本地梯度值为-0.53,再与上游的值1利用链式法则相乘即可得到最终值为-0.53。
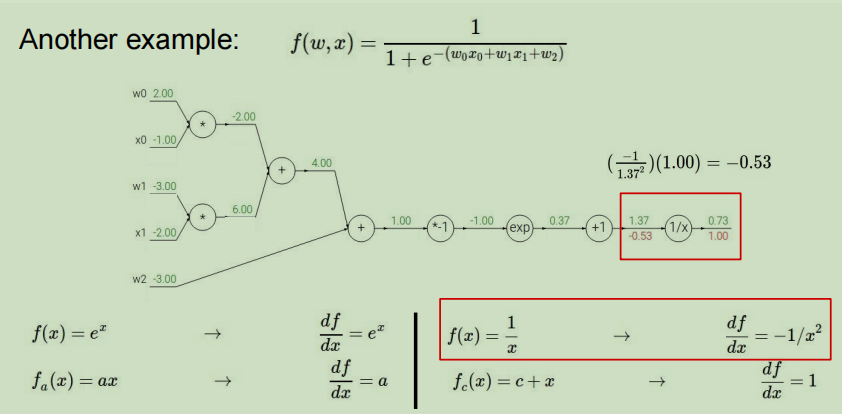
之后的节点执行相同的操作即可
节点+1:
- 上游值:-0.53
- 本地梯度表达式: f ( x ) = x + c → d f d x = 1 f(x) = x+c \rightarrow \dfrac{df}{dx}=1 f(x)=x+c→dxdf=1
- 本地梯度值为:1
- 利用链式法则求得最终值为:-0.53
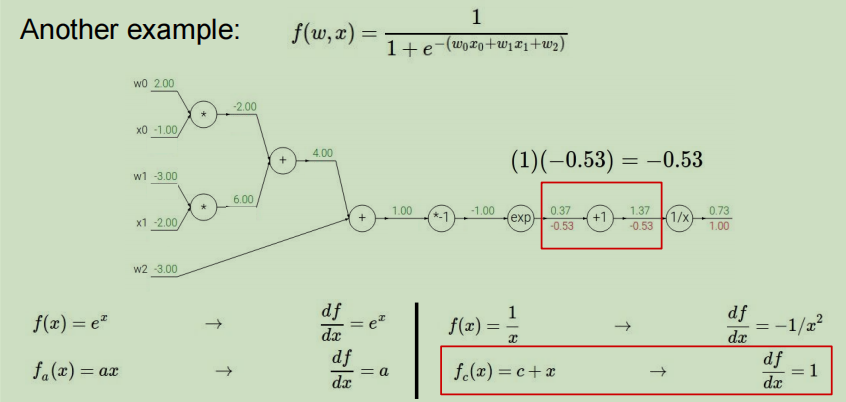
节点exp:
- 上游值:-0.53
- 本地梯度表达式: f ( x ) = e x → d f d x = e x f(x) = e^x\rightarrow \dfrac{df}{dx}=e^x f(x)=ex→dxdf=ex
- 本地梯度值为: e − 1 e^{-1} e−1
- 利用链式法则求得最终值为: ( e − 1 ) ( − 0.53 ) = − 0.20 (e^{-1})(-0.53) = -0.20 (e−1)(−0.53)=−0.20
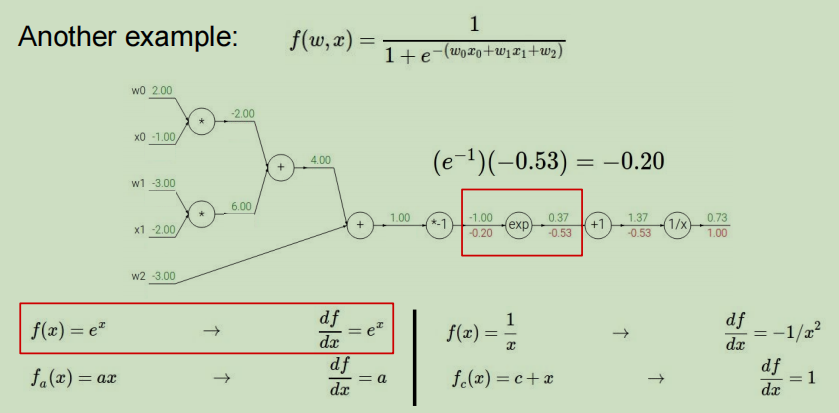
节点*-1:
- 上游值:-0.20
- 本地梯度表达式: f ( x ) = a x → d f d x = a f(x) = ax\rightarrow \dfrac{df}{dx}=a f(x)=ax→dxdf=a
- 本地梯度值为: − 1 -1 −1
- 利用链式法则求得最终值为:-1*(-0.2) = 0.20
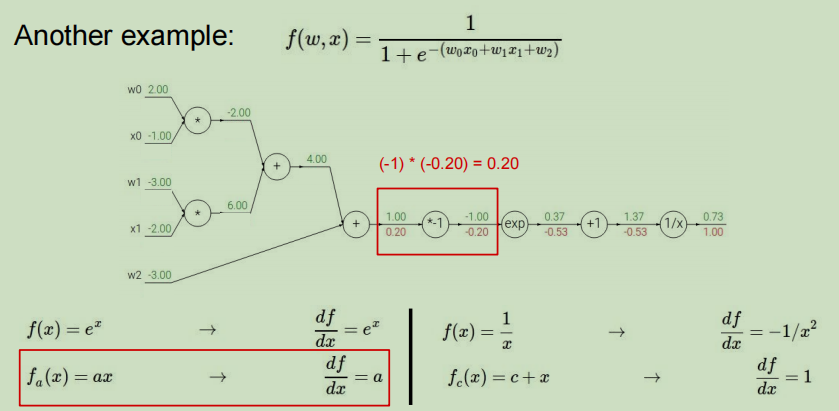
节点+:
- 上游值:0.20
- 本地梯度表达式: f ( x ) = x + y → ∂ f ∂ x = 1 f(x)=x+y \rightarrow \dfrac{\partial f}{\partial x}=1 f(x)=x+y→∂x∂f=1
- 本地梯度值:1
- 利用链式法则求得最终值为:0.20
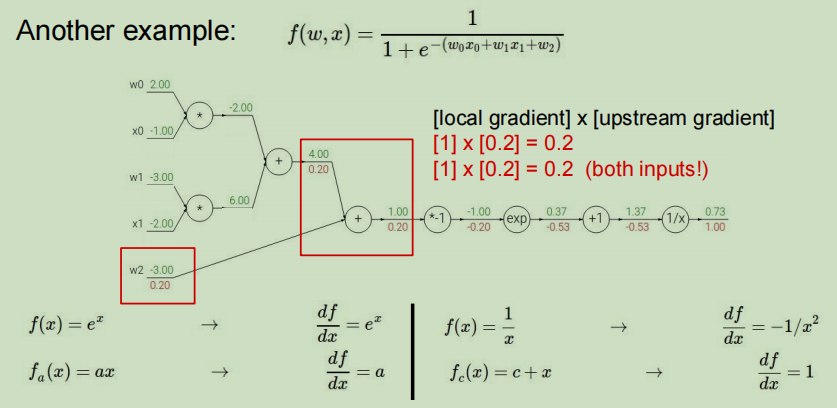
节点*:
- 上游值:0.20
- 本地梯度表达式: f ( x ) = x y → ∂ f ∂ x = y f(x)=xy \rightarrow \dfrac{\partial f}{\partial x}=y f(x)=xy→∂x∂f=y
- 本地梯度值:对于w0,本地梯度值为x0(-1),对于x0,本地梯度值为w0(2)
- 利用链式法则求得最终值为:w0为-0.20,x0为0.40
我们可以将计算图中几个简单地节点用一个大的节点替换掉。
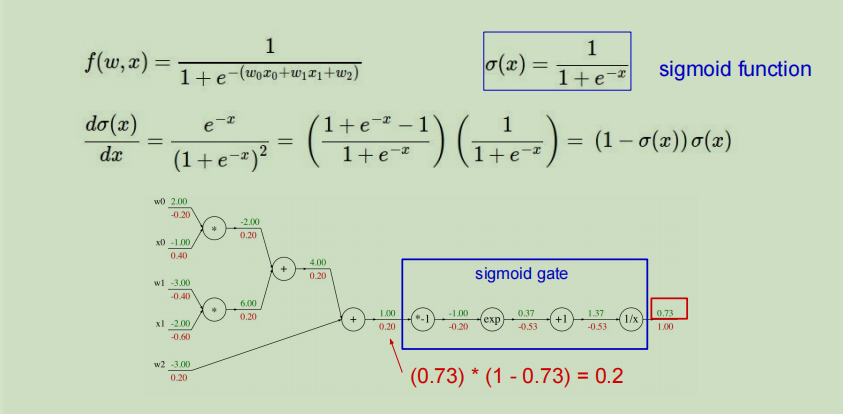
你可以去聚合你想要的任何节点去组成稍微复杂一点的节点,只要你能写出他的本地梯度,这是一个权衡问题,一个是数学计算的计算图有多么简单,另一个是每个梯度计算时有多简单。
特殊的节点
- 加法节点:本地梯度都为1
- max节点:本地梯度一个为1,一个为0
- 乘法节点:本地梯度相当于交换了x和y的值
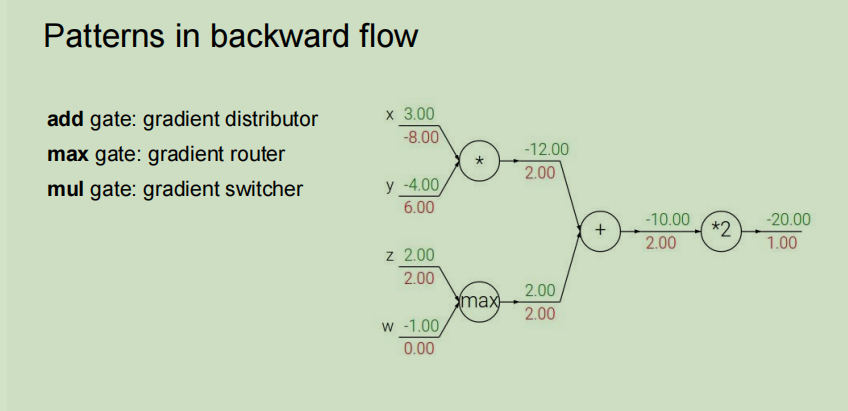
一个结点有多个后继节点,在反向传播时,根据链式法则进行累加即可。 ∂ f ∂ x = ∑ i ∂ f ∂ q i ∂ q i ∂ x \dfrac{\partial f}{\partial x}=\sum_i\dfrac{\partial f}{\partial q_i}\dfrac{ {\partial q_i} }{\partial x} ∂x∂f=∑i∂qi∂f∂x∂qi
高纬向量
雅克比矩阵
高等数学3和线性代数的一些知识
雅克比矩阵是函数的一阶偏导数以一定方式排列成的矩阵,其行列式称为雅克比行列式。雅克比矩阵每一行都是偏导数,矩阵中的每一个元素都是输出向量的每个元素对输入向量每个元素分别求偏导的结果
J = ∂ ( F , G ) ∂ ( u , v ) = ∣ ∂ F ∂ u ∂ F ∂ v ∂ G ∂ u ∂ G ∂ v ∣ J = \dfrac {\partial(F,G)} {\partial(u,v)}=\begin{vmatrix} \dfrac{\partial F} {\partial u} & \dfrac{\partial F} {\partial v} \\ \dfrac{\partial G} {\partial u} & \dfrac{\partial G} {\partial v} \\ \end{vmatrix} J=∂(u,v)∂(F,G)=∣∣∣∣∣∣∣∂u∂F∂u∂G∂v∂F∂v∂G∣∣∣∣∣∣∣
其实计算流程还是一模一样的,只是刚才的梯度变成了雅克比矩阵,就是包含了变量中每个元素导数的矩阵,比如z在每个x元素方向上的梯度。
维度的问题
对于一个4096维向量输入和一个4096维向量输出,所需要的雅克比矩阵的大小为4096*4096,实际中我们进行小批量处理,那么就意味着这个矩阵将会更大,比如一次进行100个样本的处理,那么雅克比矩阵就会变成409600 * 409600。如果这样的话,将会计算很慢,甚至说不可计算。
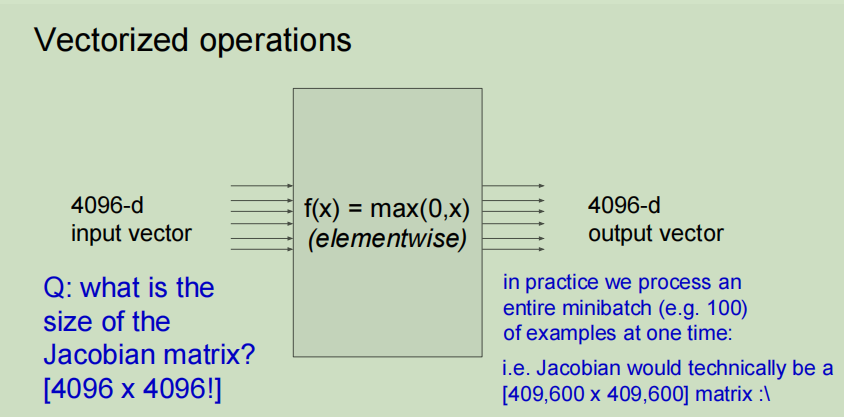
由于输入的第一个元素之和输出的第一个元素有关系,所以实际上我们算出的雅克比矩阵是一个对角矩阵,所以不需要把整个矩阵都算出来。
向量的梯度总是和向量保持着一样的大小
计算过程
W是2 * 2,x是2维的向量
第一步:写出计算图且向前传播计算
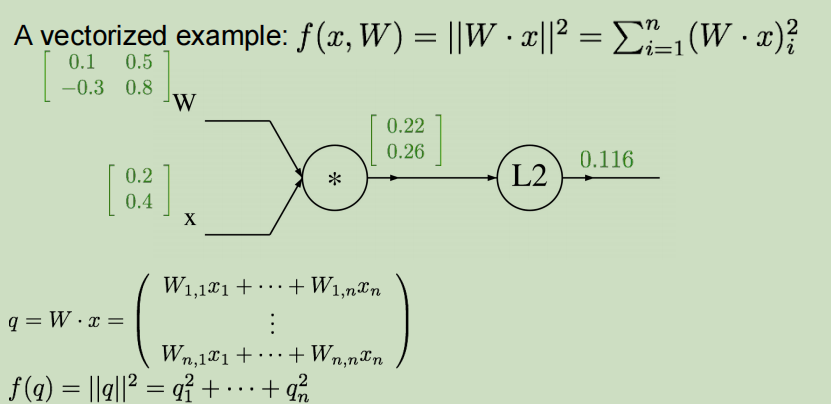
第二步:进行反向传播
节点L2:
- 上游值:1
- 本地梯度:q是一个二维的向量,对于每一维的qi, ∂ f ∂ q i = 2 q i , 即 ∇ f = 2 q \dfrac{\partial f}{\partial q_i}= 2q_i,即 \nabla f = 2q ∂qi∂f=2qi,即∇f=2q
- 本地梯度值: ∣ 0.22 0.26 ∣ \begin{vmatrix} 0.22 \\ 0.26 \\ \end{vmatrix} ∣∣∣∣0.220.26∣∣∣∣
- 利用链式法则求得最终梯度值: ∣ 0.44 0.52 ∣ \begin{vmatrix} 0.44 \\ 0.52 \\ \end{vmatrix} ∣∣∣∣0.440.52∣∣∣∣
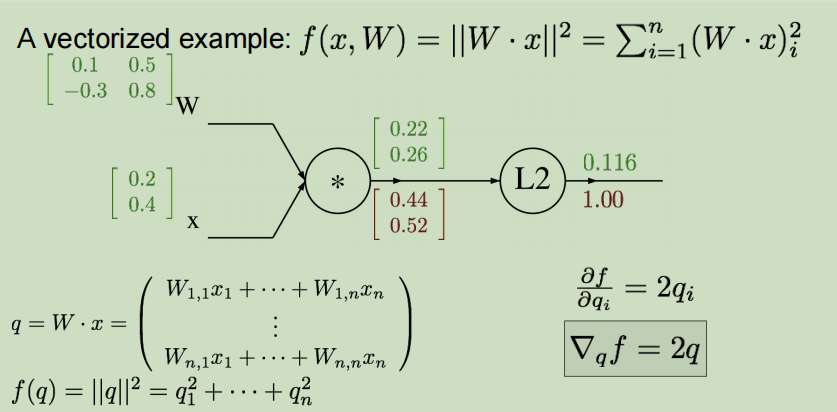
节点*:
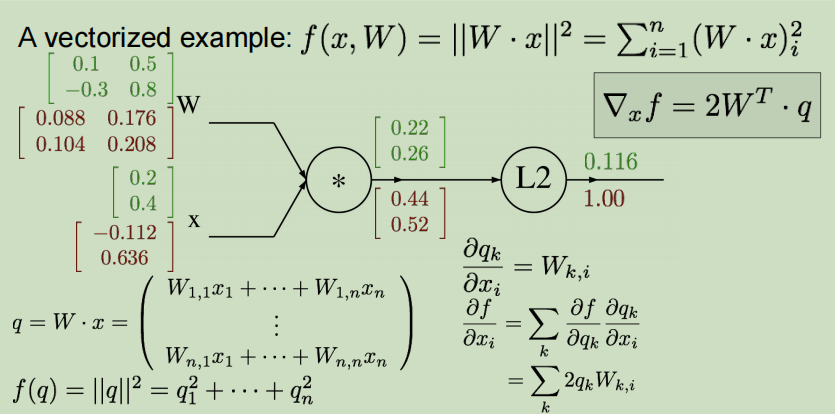
比如对于q的第一个元素q1,他和W的第一个元素W1,1有什么关系呢?q的第一个元素为 W 1 , 1 x 1 + W 1 , 2 x 2 W_{1,1}x_1+W_{1,2}x2 W1,1x1+W1,2x2,很容易看出,q1对于W1,1的导数为x1。推广到一般的情况,就有 ∂ q k ∂ W i , j = 1 k = i x j \dfrac{\partial q_k}{\partial W_{i,j}} = 1_{k=i}x_j ∂Wi,j∂qk=1k=ixj。利用这个公式对W中的每一个元素都进行计算,可以得到关于W的梯度,一定是和W形状相同的。
注意:就是变量梯度的向量大小和变量向量大小一致,在实际中这是非常有用的完整性检查,每个梯度的元素量化了每个元素对最终输出影响的贡献
- 上游值: ∣ 0.44 0.52 ∣ \begin{vmatrix} 0.44 \\ 0.52 \\ \end{vmatrix} ∣∣∣∣0.440.52∣∣∣∣
- 本地梯度: ∂ q k ∂ W i , j = 1 k = i x j \dfrac{\partial q_k}{\partial W_{i,j}} = 1_{k=i}x_j ∂Wi,j∂qk=1k=ixj,对于W中的每一个元素都使用这个公式计算既可得到本地梯度值 ∣ 0.2 0.4 0.2 0.4 ∣ \begin{vmatrix} 0.2 & 0.4\\ 0.2 & 0.4\\ \end{vmatrix} ∣∣∣∣0.20.20.40.4∣∣∣∣
- 最终梯度值:对每个元素进行单独操作,第一行的元素乘以上游值第一行…这样依次下去就能算出最终的值
其实对于函数 f ( q ) = ∣ ∣ q ∣ ∣ 2 = q 1 2 + . . . + q n 2 f(q)=||q||^2=q_1^2+...+q_n^2 f(q)=∣∣q∣∣2=q12+...+qn2,我们也可以利用链式法则可以求出f对于W的偏导数,见下图的推导。图中的q是向前传播的中间变量值。

同理,如此计算出x的梯度即可

















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









