







文章目录
一、机器翻译
1.1 基于规则
1950年代由于冷战,研发了最早的基于规则的机器翻译系统:俄语2英语
1.2 基于概率(statistical)统计(SMT)
1990s-2010s: 基于概率统计的机器翻译系统。
例如我们需要将法语的句子x翻译为英语句子y, 任务描述如下
a
r
g
m
a
x
y
P
(
y
∣
x
)
argmax_yP(y|x)
argmaxyP(y∣x)
由于源语言x序列确定,使用贝叶斯公式将该规则拆分为两个独立的部分,拆分工作便于模型训练效果提升:
a
r
g
m
a
x
y
P
(
x
∣
y
)
P
(
y
)
P
(
x
)
=
a
r
g
m
a
x
y
P
(
x
∣
y
)
P
(
y
)
argmax_y\frac{P(x|y)P(y)}{P(x)} = argmax_y P(x|y)P(y)
argmaxyP(x)P(x∣y)P(y)=argmaxyP(x∣y)P(y)
其中
P
(
x
∣
y
)
P(x|y)
P(x∣y)为从双语对照数据学习到的翻译模型,
P
(
y
)
P(y)
P(y)为从目标语言学习到的语言模型,决定目标语言流畅度。
1.2.1 P(x|y)的学习
- 需要大量源语言-目标语言数据对
- 任务进一步拆分,考虑学习P(x, a|y), a为alignment,即语言对齐作为一个指标单独考虑
- alignment:两种语言句子词素之间的对应关系,有一对多、多对一、多对多、顺序混乱等多种复杂的可能
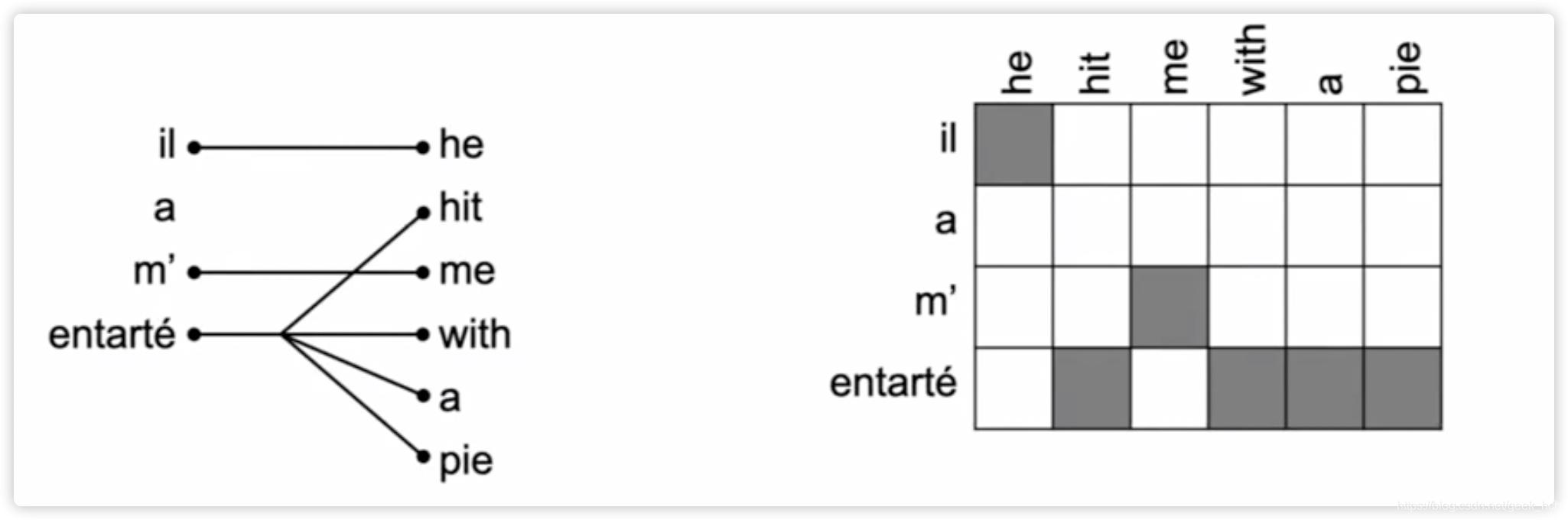
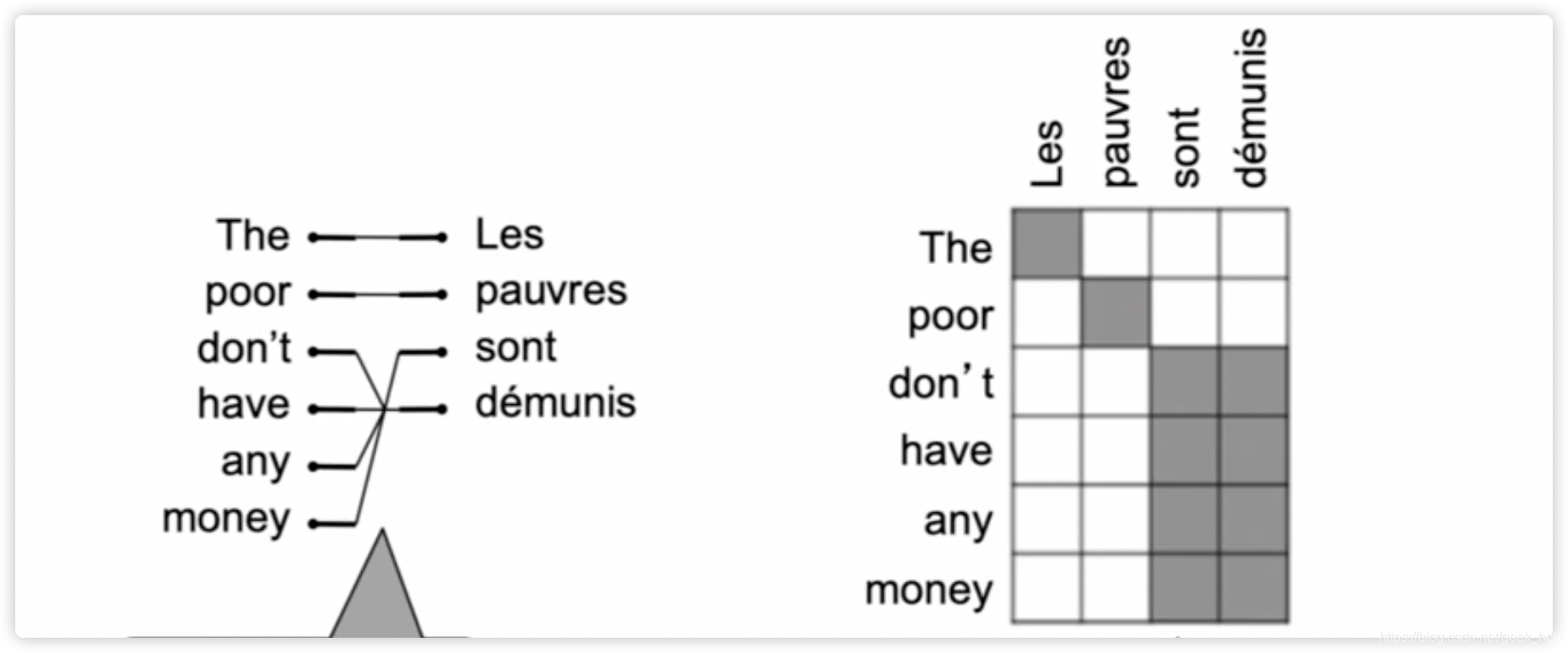
- P ( x , a ∣ y ) P(x,a|y) P(x,a∣y)代表了多个目标任务:(a)某个位置的特定词的对齐 (b)某个词的译文…
- 使用启发式搜索最佳译文,优良的SMT还有非常多的细节,十分复杂,例如复杂的特征工程、借助同义词短语表等。(课程介绍也比较模糊)
1.3 神经网络机器翻译(NMT)
1.3.1 seq2seq结构
用来输入一段序列生成另一段序列的网络架构称为seq2seq, 一般有两个RNN。先来看这张图,信息量很丰富。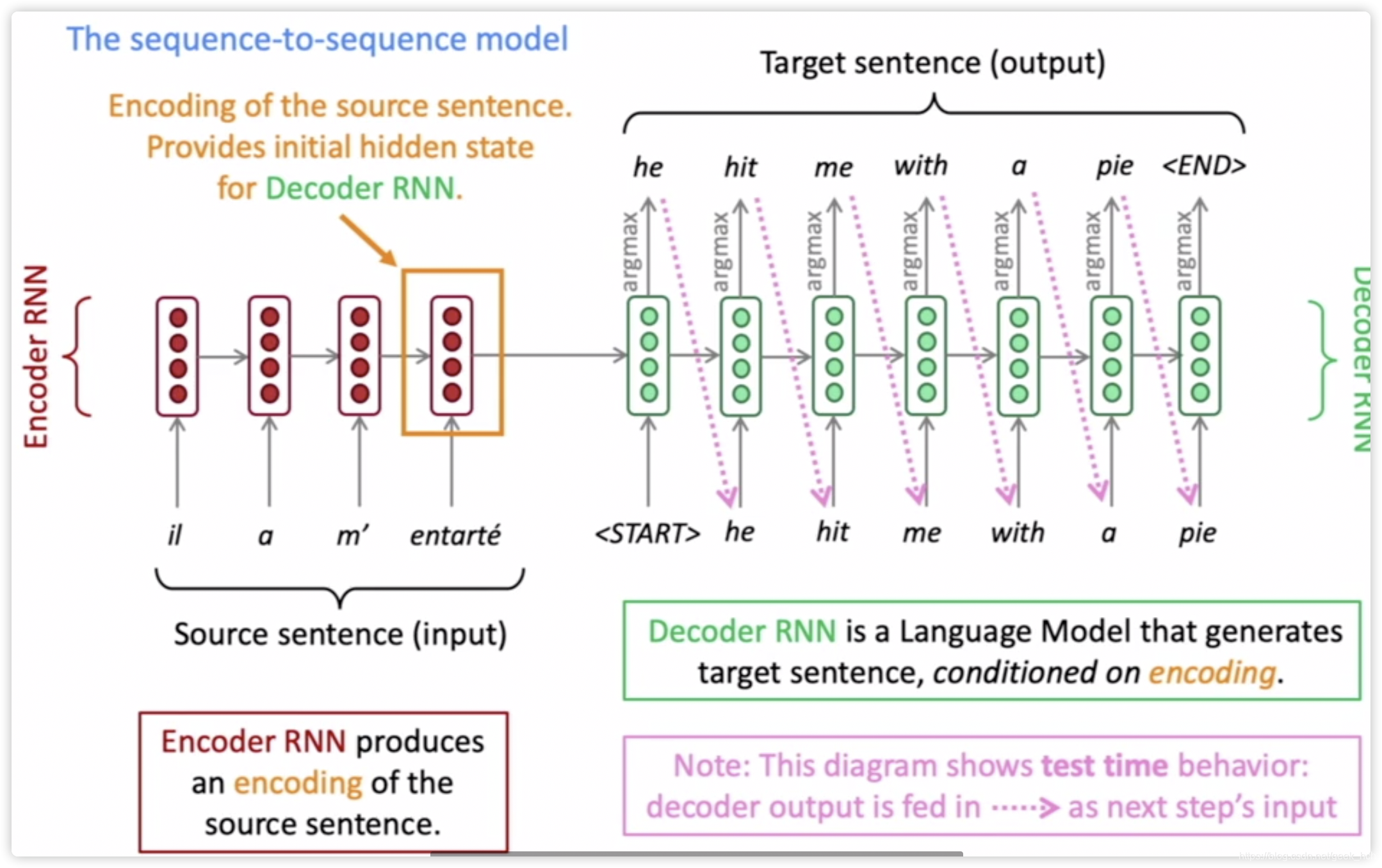
总结一下上面图中的信息:
- 两个RNN分别处理源语言与目标语言,当然也需要两个Embedding
- 源语言和目标语言分别对应的是encoder、decoder
- encoder负责对源语言编码,并将编码结果提供给decoder作为其初始状态。
- decoder是一个语言模型,负责带条件的语言生成。
seq2seq除了能用来翻译,还能干很多事:
- 摘要
- 对话
- 文档解析
- 代码生成
- …
1.3.2 seq2seq模型训练
seq2seq的decoder是一个条件语言模型,预测
P
(
y
∣
x
)
P(y|x)
P(y∣x),其中x为源语言句子。
P
(
y
∣
x
)
=
P
(
y
1
∣
x
)
P
(
y
2
∣
y
1
,
x
)
P
(
y
3
∣
y
1
,
y
2
,
x
)
…
P
(
y
T
∣
y
1
,
…
,
y
T
−
1
,
x
)
(1.3.2)
P ( y | x ) = P \left( y _ { 1 } | x \right) P \left( y _ { 2 } | y _ { 1 } , x \right) P \left( y _ { 3 } | y _ { 1 } , y _ { 2 } , x \right) \ldots P \left( y _ { T } | y _ { 1 } , \ldots , y _ { T - 1 } , x \right)\\ \tag{1.3.2}
P(y∣x)=P(y1∣x)P(y2∣y1,x)P(y3∣y1,y2,x)…P(yT∣y1,…,yT−1,x)(1.3.2)
训练原理如下:
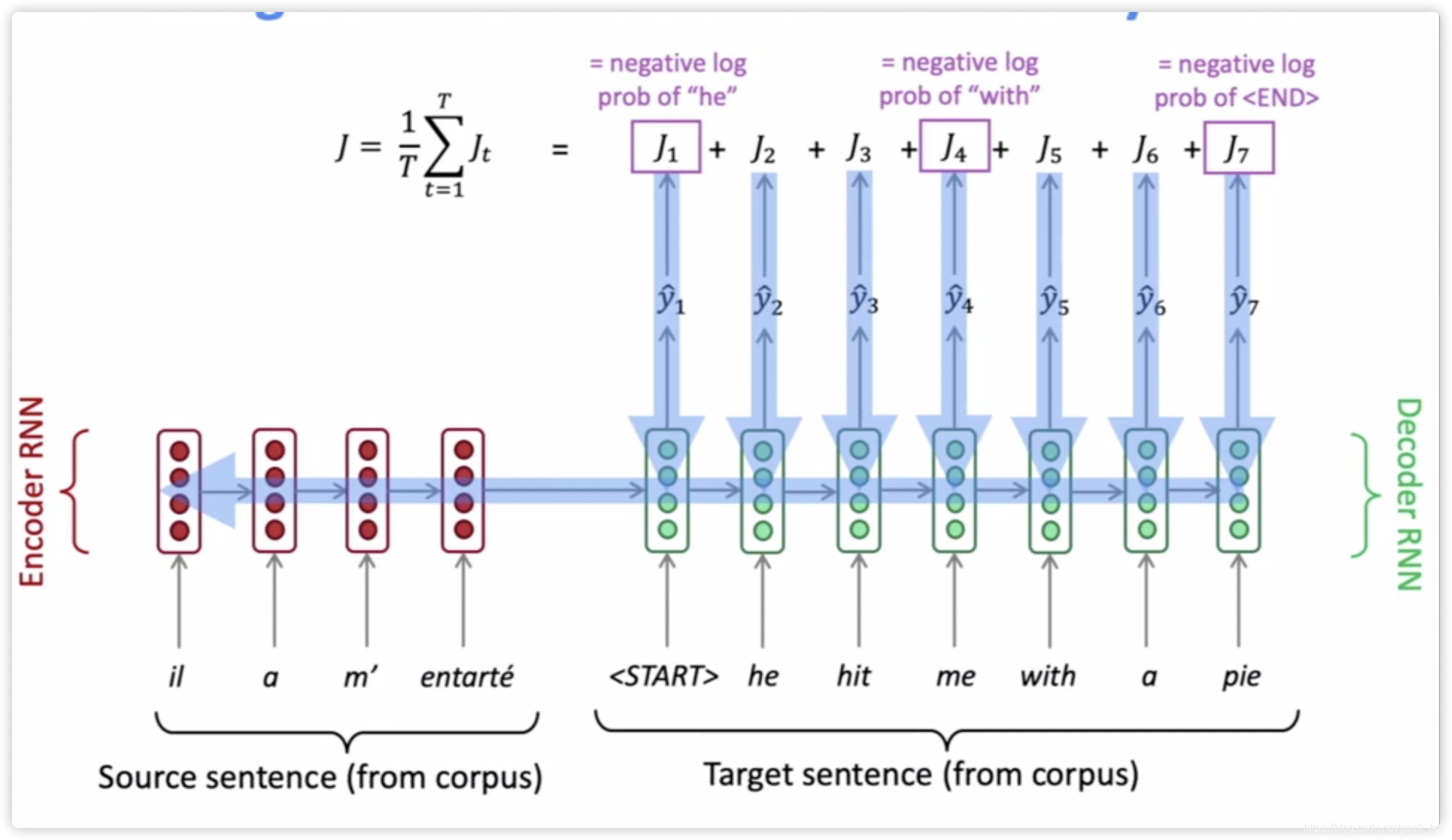
- 训练阶段,time-steps的数目不固定,一般来说是每个batch中最长序列的长度(也可以固定序列为一个较大值,使用padding填充)
- decoder不会因为提前预测到<end>导致loss计算出问题,因为在预测阶段,预测到表示这句话结束,而训练阶段,如果使用那就是在固定长度下计算loss,这当然ok, 而使用变长序列的话,在decoder的hidden中传递的是向量,即使该向量对应的是符号,也仍然可以往后传递,loss计算以训练集样本y的长度来确定。
1.3.3 贪心解码
贪心是指每一步都寻找当前最接近的答案。这里decoder计算是这样的,利用上一步的argmax的词向量作为下一个的输入,而不是直接用
h
t
−
1
h_{t-1}
ht−1。这么做的缺点是,在每个词上先进行了argmax, 这并不一定是整个句子的argmax。
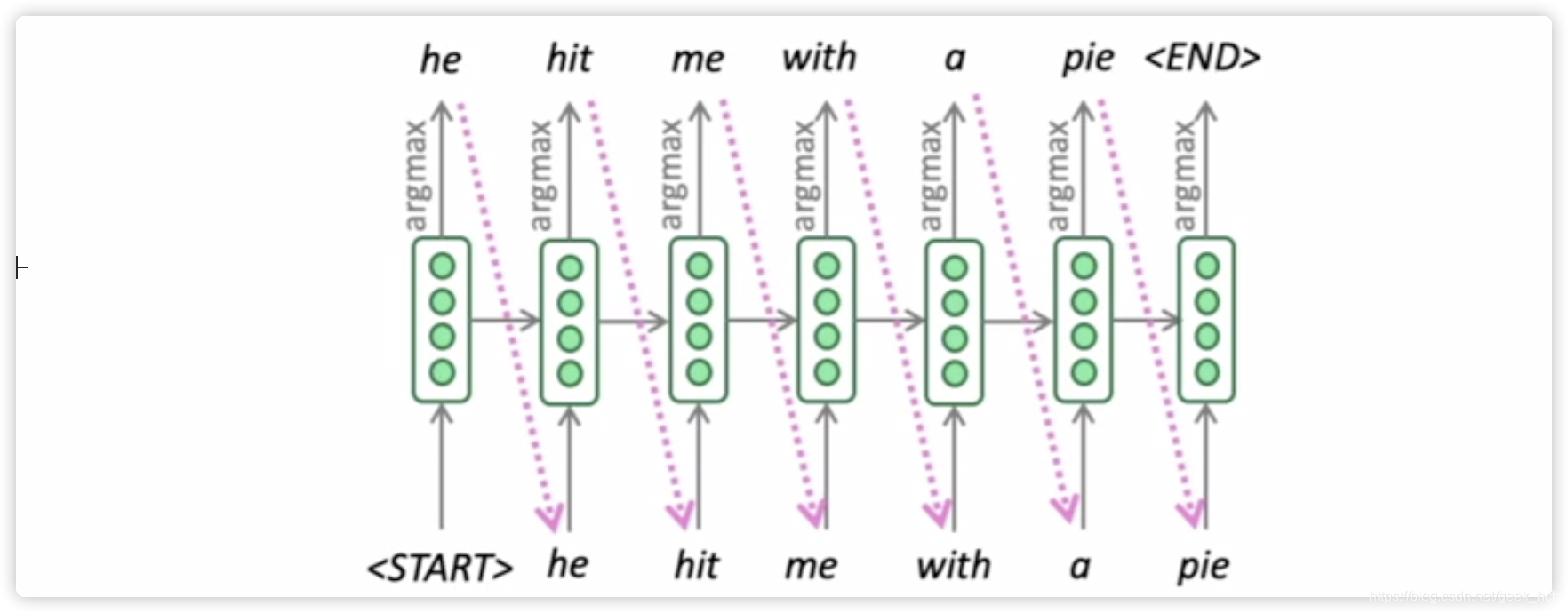
由于decoder贪心解码的缺点是由于没有回退撤销,我们对它进行改进
1.3.4 穷举(exhaustive)搜索解码
根据公式1.3.2, 如果每一步都考虑所有可能序列的概率,那就是 O ( T V ) O(T^{V}) O(TV)复杂度,复杂度太高了。
1.3.5 启发式搜索方法:Beam Search
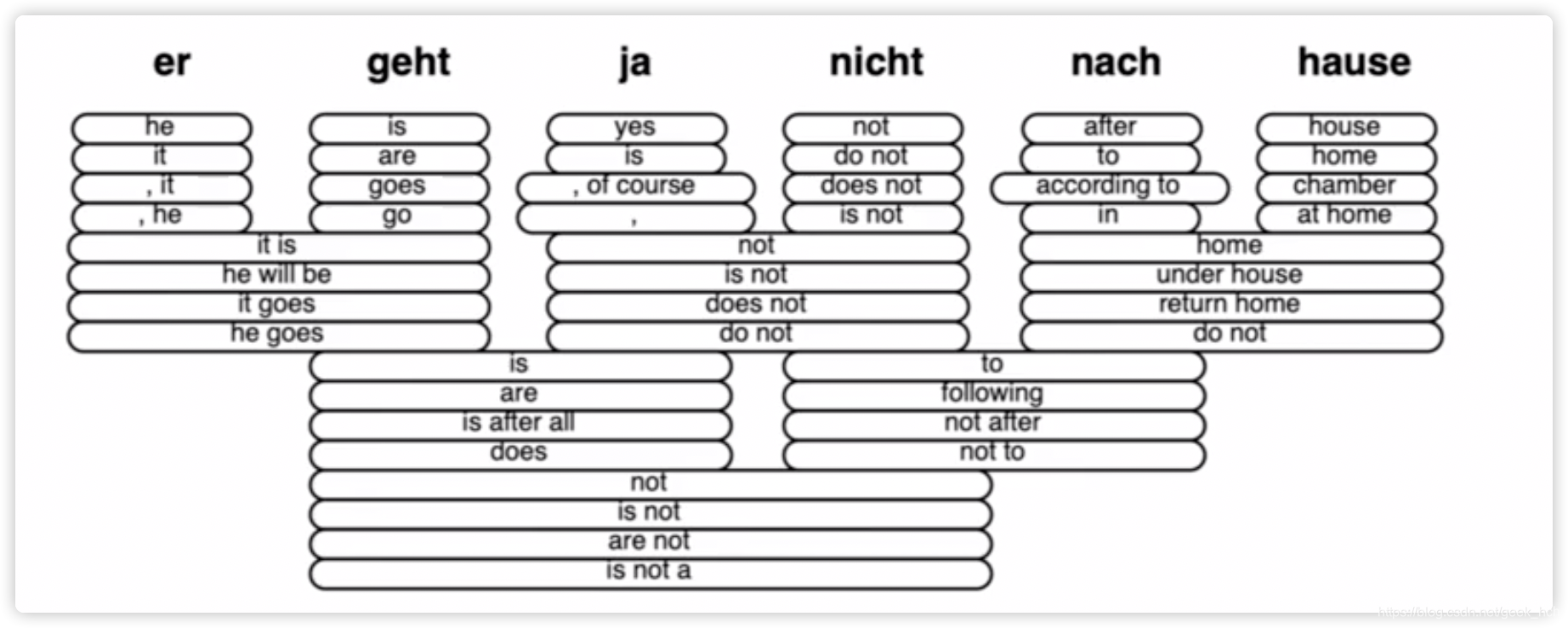
beam search是以上两种办法的折中,即在第t步保留前k(一般为4-5)个高概率的可能序列。以k=2为例的一个搜索过程如图:
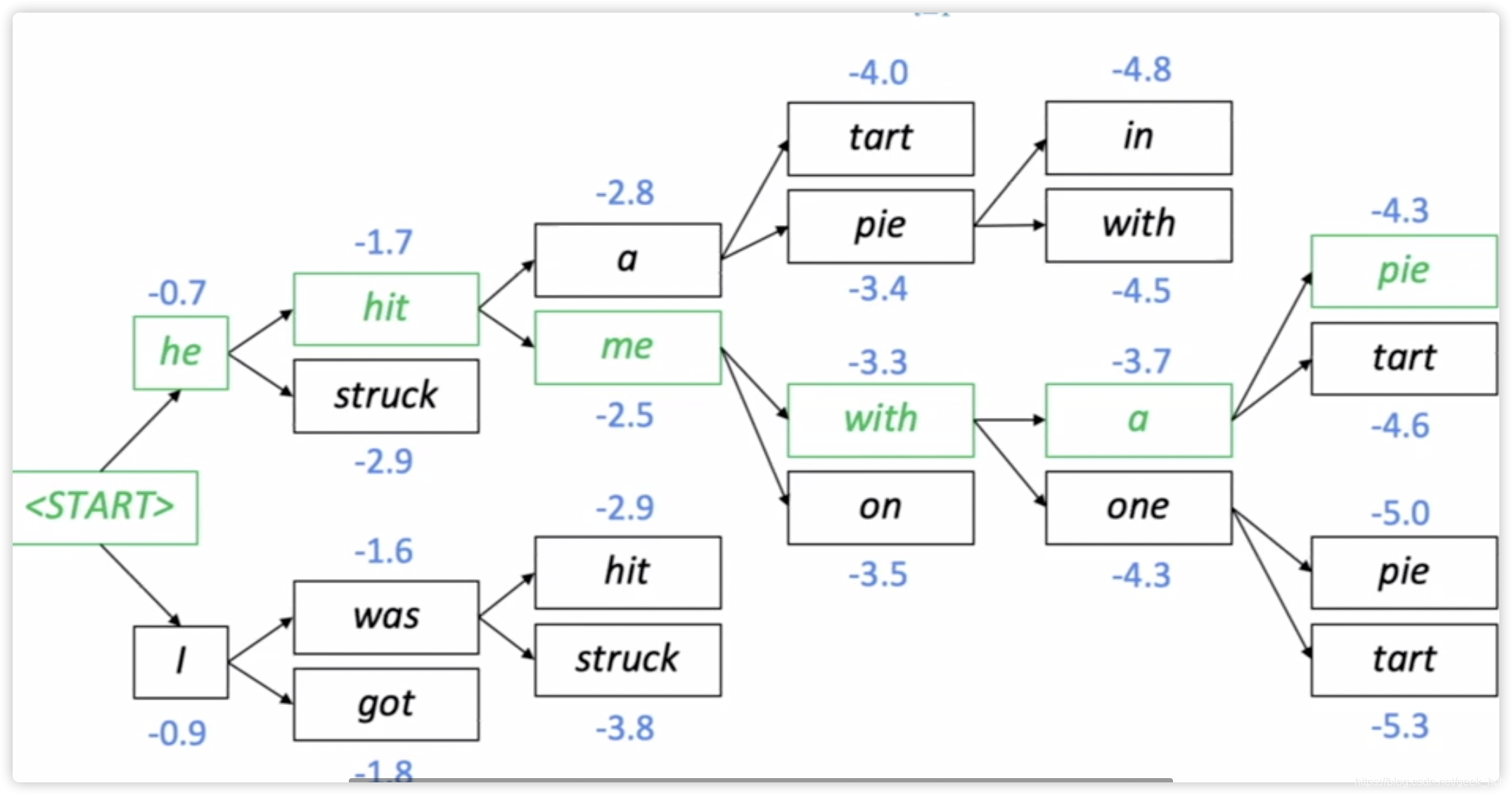
终止条件:由于在测试阶段,表示结束,而使用beam search会导致一些不通长度的预测序列。终止规则如下:1. 设置非固定最大长度T。 2. 设置当有n个搜索结果达到时。
为了平衡不通长度结果的评分,使用如下评分函数:
s
c
o
r
e
=
1
t
∑
i
=
1
t
log
P
L
M
(
y
i
∣
y
1
,
…
,
y
i
−
1
,
x
)
score = \frac { 1 } { t } \sum _ { i = 1 } ^ { t } \log P _ { \mathrm { LM } } \left( y _ { i } | y _ { 1 } , \ldots , y _ { i - 1 } , x \right)
score=t1i=1∑tlogPLM(yi∣y1,…,yi−1,x)
1.3.5 启发式搜索方法:sampling采样解码
暂时跳过
1.3.6 NMT优势与缺点
优势:
- 翻译更流畅、更好的利用上下文、更少的人力投入,端到端,一个框架多种语言
缺点:
- 不可解释、不好debug,不可预测
- 难以控制,比如一些很明显的语言短语映射规则,不能直接规定
1.3.7 模型验证
BLEU(bilingual evalution understudy): 比较机器翻译结果和人类翻译结果如下相似度指标:
- n-gram准确率
- 对太短的机器翻译结果增加惩罚
BLEU缺点:
- 一种语言可以有多种翻译,一个好的翻译模型可能获得较低分数
1.3.8 NMT发展史及现存问题
- 2014年提出seq2seq, 2016年google将SMT换为NMT
- 几百人历时数十年研发的SMT, 比不过几个人几个月训练的NMT
待解决问题:
- 词汇表中没有的词的处理
- 训练集与测试集领域不匹配时,表现较差
- 在长文本中维持context
- 某些语言缺少训练数据
- 不可解释性的系统奇怪举止:
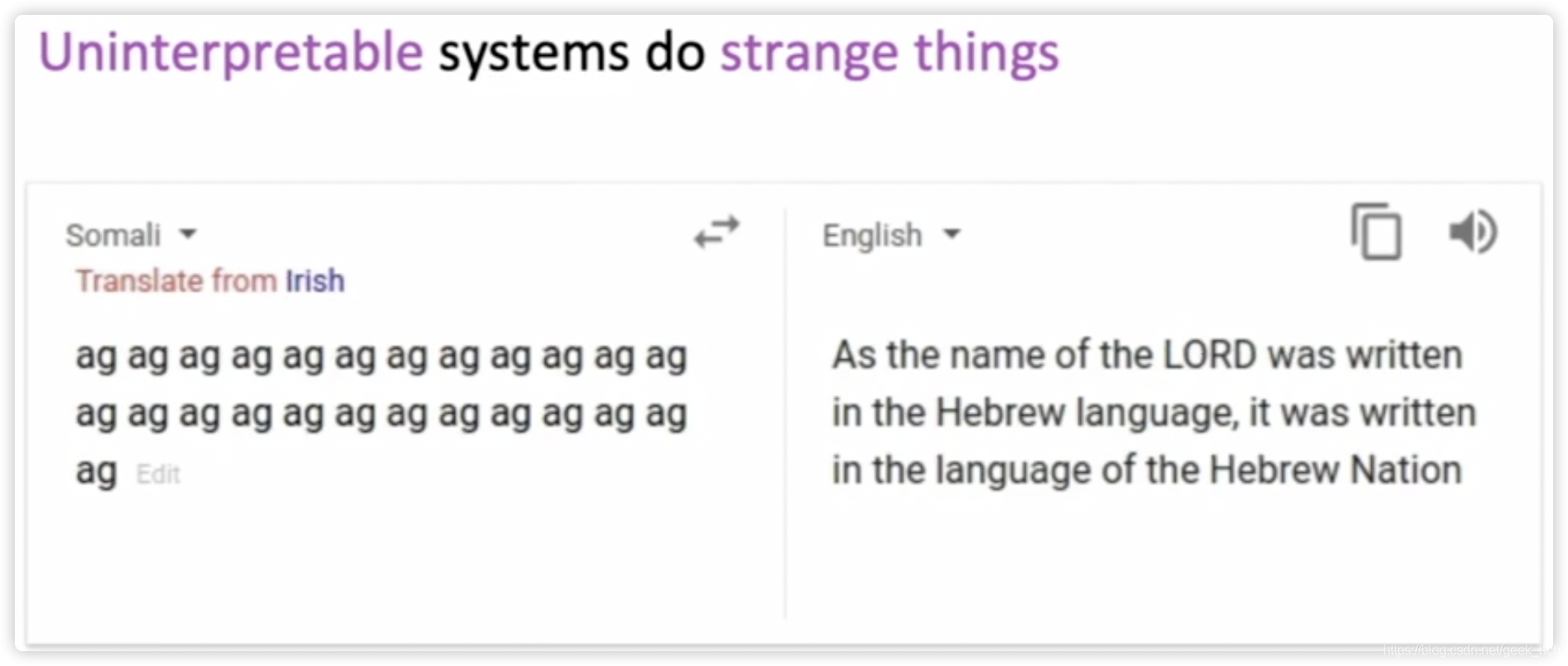
二、Attention
2.1 Attention结构
2.1.1 预备知识
- RNN结构、前向反向传播
- seq2seq
2.1.2 朴素seq2seq的缺点
- 原始的seq2seq, encoder从一开始的每一个time-step的信息都可能会丢失,无法有效传播到decoder的对应位置。
- encoder只有最后一个状态传到decoder,大量信息损失
2.1.3 dot-product Attention计算方式
如下图,在seq2seq的基础上:
- 有encoder的hidden向量 h 1 , … , h N ∈ R h \boldsymbol h_{1}, \ldots, \boldsymbol h_{N} \in \mathbb{R}^{h} h1,…,hN∈Rh
- 对于decoder每个step有hidden向量 s t s_t st
- 通过点击计算注意力分数: e t = [ s t T h 1 , … , s t T h N ] ∈ R N \boldsymbol{e}^{t}=\left[\boldsymbol{s}_{t}^{T} \boldsymbol{h}_{1}, \ldots, \boldsymbol{s}_{t}^{T} \boldsymbol{h}_{N}\right] \in \mathbb{R}^{N} et=[stTh1,…,stThN]∈RN
- 使用softmax将分数转换为注意力权重: α t = s o f t m a x ( e t ) ∈ R N \boldsymbol \alpha^t = softmax(\boldsymbol e^t)\in \mathbb{R}^N αt=softmax(et)∈RN(在attention论文中提出还要乘以缩放因子 1 h \frac{1}{\sqrt{h}} h1,避免因维度过大导致分数太大,使得softmax函数梯度太小)
- 对encoder的hidden向量加权求和: a t = ∑ i = 1 N α i t h i ∈ R 2 h \boldsymbol a^t=\sum_{i=1}^N \alpha_i^t \boldsymbol h_i \in \mathbb{R}^{2h} at=∑i=1Nαithi∈R2h
- 将 s t \boldsymbol s_t st与 a t \boldsymbol a_t at拼接作为decoder输出。
- 在decoder的设计中,有时候会将前一个time-step的attention作为当前这一步的输入之一。
decoder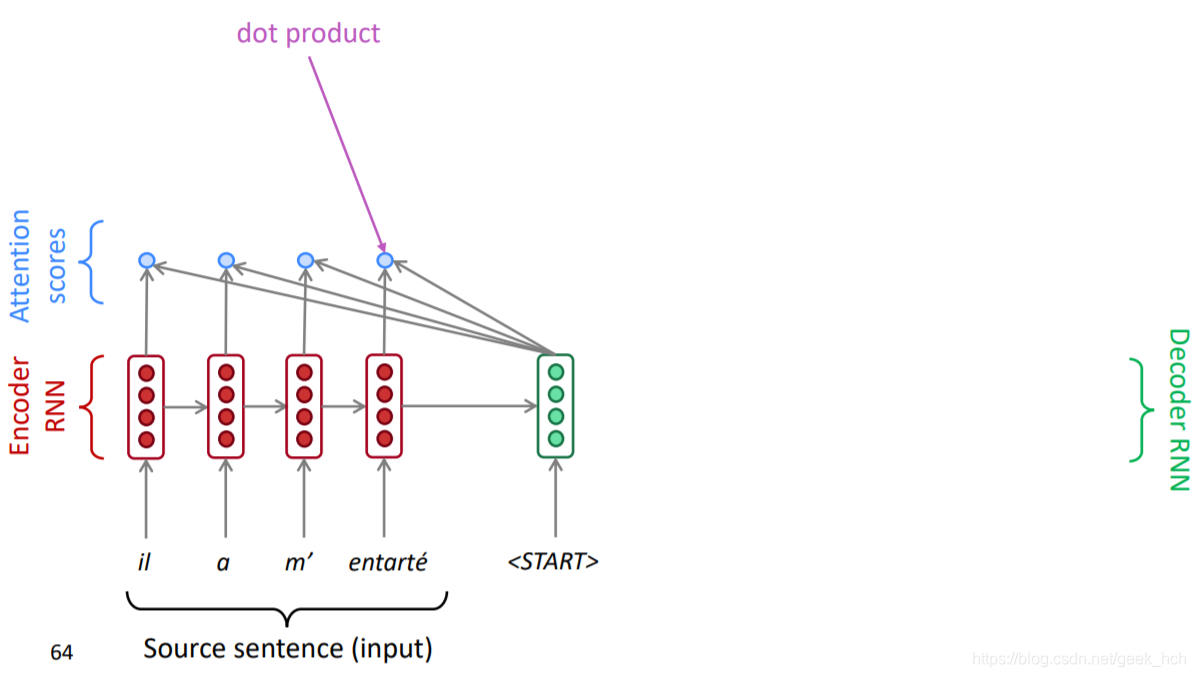
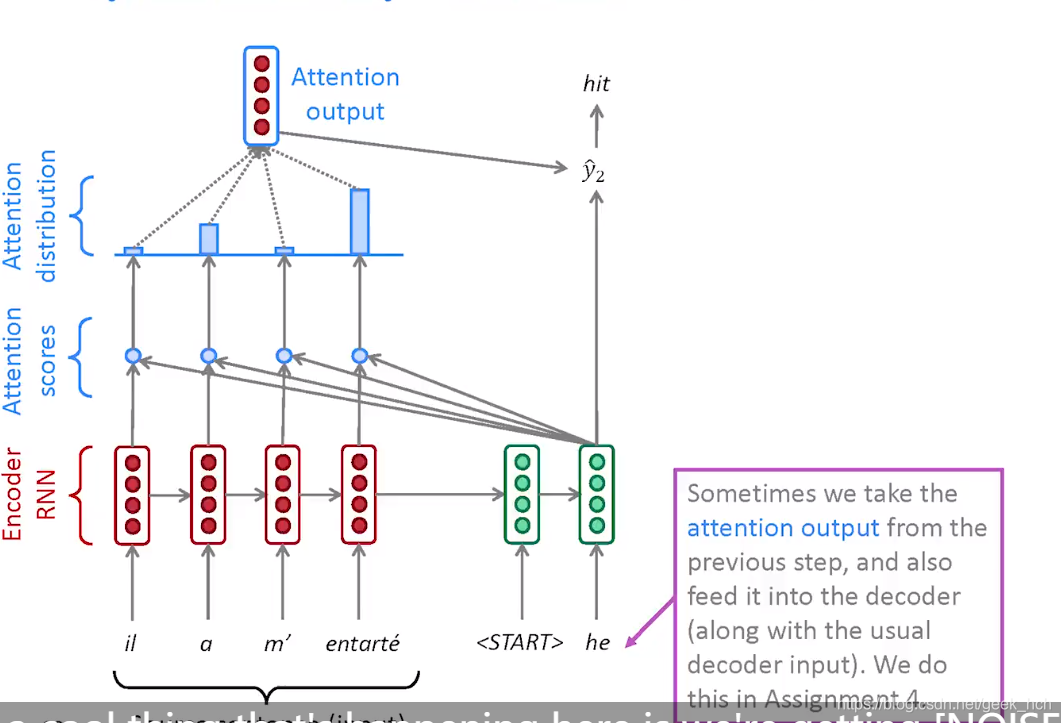
扩展: Attention论文中对该结构的解释用到了Q(query), K(key), V(value),其中Q对应这里的decoder的hidden向量, K和V对应encoder的hidden向量。直观理解就是将每一个decoder的时间不作为一个查询,通过encoder计算得到输出向量,这个向量包含了整个encoder的加权信息。
其他Attention
点积attention是计算代价最小的一种,它要求 s \boldsymbol{s} s和 h \boldsymbol{h} h维度相同,如果维度不同怎么办呢?有了前面的基础,应该能想到:
-
multiplicative Attention
e i = s T W h i ∈ R \boldsymbol{e_i} = \boldsymbol{s}^T\boldsymbol{W}\boldsymbol{h_i} \in \mathbb R ei=sTWhi∈R -
addictive attention, 这里 v \boldsymbol{v} v是模型参数,它的维度是一个超参数。
e i = v T tanh ( W 1 h i + W 2 s ) ∈ R \boldsymbol{e}_{i}=\boldsymbol{v}^{T} \tanh \left(\boldsymbol{W}_{1} \boldsymbol{h}_{i}+\boldsymbol{W}_{2} \boldsymbol{s}\right) \in \mathbb{R} ei=vTtanh(W1hi+W2s)∈R
这两种Attention都引入了新的模型参数,学习能力比dot-product更强(但个人觉得attention的瓶颈是加权求和会损失信息,因此引入更多参数的意义似乎不大)














 3188
3188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









