









文章目录
1. addictive attention
1.1 说明
- 目标:为了解决注意力中query(查询)和键(keys)长度不一致问题,其实本质上就是加了几个全连接层,这样就可以将不同的长度转换到同一个长度h上;当查询和键是不同长度的矢量时,我们可以使用加性注意力作为评分函数;这里的隐藏层数h是一个超参数
a ( q , k ) = W v T tanh ( W q q + W k K ) ∈ R (1) a(q,k)=W^T_v\tanh(W_qq+W_kK)\in R\tag1 a(q,k)=WvTtanh(Wqq+WkK)∈R(1)
(1) W q ∈ R h × q W_q\in R^{h \times q} Wq∈Rh×q;完成将q长度转换成长度h
(2) W k ∈ R h × k W_k\in R^{h \times k} Wk∈Rh×k;完成将k长度转换成长度h
(3) W v ∈ R v W_v \in R^{v} Wv∈Rv;完成将v长度转换成1得到权重分数
1.2 代码
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: addictive_attention
# @Create time: 2022/2/20 13:21
import torch
from torch import nn
from d2l import torch as d2l
class AdditiveAttention(nn.Module):
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.w_k = nn.Linear(key_size, num_hiddens, bias=False)
self.w_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys= self.w_q(queries), self.w_k(keys)
# 因为queries=(2,10,8);keys=(2,1,8);它们两个中间维度不一致,无法直接相加
# 所以我们需要把queries->(2,1,1,8);keys->(2,1,10,8)
# 这样我们就可以通过广播机制来相加得到features->(2,1,10,8)
# [bs,q,1,h]+[bs,1,k,h]=[bs,q,k,h]
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# [bs,q,k,h]->[bs,q,k,1]->scores=[bs,q,k]
scores = self.w_v(features).squeeze(-1)
self.attention_weights = d2l.masked_softmax(scores, valid_lens)
# [bs,q,k]*[bs,k,d]->bmm->[bs,q,d]
return torch.bmm(self.dropout(self.attention_weights), values)
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.tensor([2, 6])
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8, dropout=0.1)
attention.eval()
y = attention(queries, keys, values, valid_lens)
print(f"y={y}")
- 结果:
y=tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=<BmmBackward0>)
1.3 小结
(1)当查询和键值长度不一致的时候,我们需要用到加性注意力
(2)当矩阵A为(b,w,n),矩阵B为(b,m,n)时候,无法进行直接相加,我们需要矩阵变换如下
- A:(b,w,n) -> (b,w,1,n)
- B:(b,m,n) -> (b,1,m,n)
- C: C=A+B=(b,w,m,n);主要依据为pytorch的广播机制
2. dot_production_attention
2.1 说明
缩放点积注意力主要的前提是q和k是由相同的长度d,这样我们就可以在注意力机制中取消掉学习的参数;使得注意力权重的计算简单化。
a
(
q
,
k
)
=
q
T
k
/
d
(2)
a(q,k)=q^Tk/\sqrt{d}\tag2
a(q,k)=qTk/d(2)
基于n个查询和m个键-值对计算注意力,其中查询和键的长度为d,值的长度为v,查询
Q
∈
R
n
×
d
Q\in R^{n \times d}
Q∈Rn×d,键
K
∈
R
n
×
d
K \in R^{n \times d}
K∈Rn×d,值
V
∈
R
n
×
v
V \in R^{n \times v}
V∈Rn×v
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
∈
R
n
×
v
(3)
softmax(\frac{QK^T}{\sqrt{d}})V \in R^{n \times v} \tag3
softmax(dQKT)V∈Rn×v(3)
2.2 代码
import math
import torch
from torch import nn
from d2l import torch as d2l
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens=None):
# queries = (2,1,2);keys=(2,10,2);values=(2,10,4)
# d = 2
d = queries.shape[-1]
# queries=(2,1,2) keys=(2,2,10) -> scores=(2,1,10)
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
self.attetion_weights = d2l.masked_softmax(scores, valid_lens)
# self.attetion_weights = (2,1,10) * value=(2,10,4)
# return (2,1,4)
return torch.bmm(self.dropout(self.attetion_weights), values)
# keys =(bs,k,d_k)=(2,10,2)
# values =(bs,v,d_v) =(2,10,4)
keys = torch.ones((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.tensor([2, 6])
# queries =(bs,q,d_q)=(2,1,2)
queries = torch.normal(0, 1, (2, 1, 2))
attention = DotProductAttention(dropout=0.5)
attention.eval()
y = attention(queries, keys, values, valid_lens)
print(f"y={y}")
3. 基于注意力的seq2seq
- 作用:在原来的seq2seq新增了注意力。
- 原来的seq2seq流程:
编码器的最后状态传入到解码器中;

- 基于注意力的seq2seq流程
新增注意力机制:
k,v为编码器的所有的隐状态,组成(k,v)对; q为第"t-1"时刻的解码器的隐状态。 q t − 1 q_{t-1} qt−1

- 区别:加入了新的注意力机制,我们在翻译的时候,可以进行对应位置的翻译;而不是只看最后一个隐状态。
- 代码:
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: new_bahdanau_attention
# @Create time: 2022/2/23 10:42
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
# @save
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
print(output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape)
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
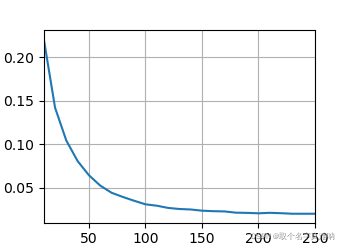
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
attention_weights = torch.cat([step[0][0][0] for step in dec_attention_weight_seq], 0).reshape((
1, 1, -1, num_steps))
# 加上一个包含序列结束词元
d2l.show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),
xlabel='Key positions', ylabel='Query positions')
plt.show()
loss 0.020, 2402.3 tokens/sec on cuda:0
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est riche ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









