









Python数据科学常用库——Pandas
一、数据格式Series
0x1 创建Series
import numpy as np
import pandas as pd
s1 = pd.Series([1,2,3,4]) # 通过Python list创建
s2 = pd.Series(np.arange(10)) # 通过numpy array创建
s3 = pd.Series({'1':1,'2':2}) # 通过字典创建
s4 = Series([1,2,3,4], index=['A','B','C','D']) # 指定索引
0x2 Series操作
s4['A'] = 1 # 通过索引访问
s4[s4>2] # 取值范围
s4.to_dict() # 转换为字典
二、数据格式Dataframe
0x1 创建Dataframe
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
df = pd.read_clipboard() # 从剪切板解析创建
df.columns # 返回表头元素
df.Ratings # 返回Ratings列的所有元素
0x2 Dataframe操作
df_new = DataFrame(df,cloumns=['A','B']) # 生成一个新的DataFrame,从df中选择某些列元素
df_new['2018'] = range(0,10) # 给某一列赋值
df_new['2018'] = np.arange(0,10)
df_new['2018'] = pd.Series(np.arange(0,10))
df_new['2018'] = pd.Series([100,200],index=[1,2]) # 给某一列指定索引赋值
三、深入理解Series和Dataframe
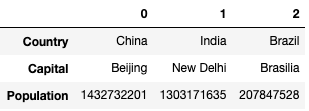
data = { 'Country': ['China', 'India', 'Brazil'], 'Capital': ['Beijing', 'New Delhi', 'Brasilia'], 'Population': ['1432732201', '1303171635', '207847528'] }
s1 = Series(data['Country'],index=['A','B','C']) # 转换数据为Series
df = DataFrame(data) # 转换数据为Dataframe
通过Series创建DataFrame
s1 = Series(data['Country'])
s2 = Series(data['Capital'])
s3 = Series(data['Population'])
df_new = DataFrame([s1,s2,s3])
df_new:

df_new = DataFrame([s1,s2,s3], index=['Country','Capital', 'Population'])
转置df_new.T

Series和DataFrame的关系

三、Dataframe的IO操作
通过df1 = pd.read_clipboard()和df1.to_clipboard()方法,可以将列表存入到Excel文件中。
0x1 CSV文件操作
df1.to_csv('df1.csv', index=False) # 写入文件
df2 = pd.read_csv('df1.csv') # 读取CSV
0x2 JSON文件操作
df1.to_json() # 转换为json
pd.read_json(df1.to_json()) # 读取json
0x3 HTML文件操作
df1.to_html('df1.html')
df1.read_html('df1.html')
0x4 转换为EXCEL
df1.to_excel('df1.xlsx')
四、Dataframe的高阶操作
imdb = pd.read_csv('a.csv')
imdb.shape # 返回数据大小
imdb.head() # 返回数据开头5行
imdb.tail() # 返回数据结尾5行
切片操作
imdb.iloc[10:20,0:2] # 切片操作,通过索引
imdb.iloc[2:4,:] # 切片操作,取2-3行数据
imdb.loc[15:17,:] # 通过label标签切片
imdb.loc[15:17,:'lable']
Reindex
s1 = Series([1,2,3,4], index=['A','B','C','D'])
s1.reindex(index=['A','B','C','D','E']) # 更改索引
s1.reindex(index=['A','B','C','D','E'], fill_value=10) # 将索引没有值的填充为10
s2 = Series(['A','B','C'], index=[1,5,10])
s2.reindex(index=range(15),method='ffill') # 将NaN的填充为前面的值
df1 = DataFrame(np.random.rand(25).reshape([5,5]), index=['A','B','D','E','F'], columns=['c1','c2','c3','c4','c5'])

df1.reindex(index=['A','B','C','D','E','F'],columns=['c1','c2','c3','c4','c5','c6'])

s1.reindex(index=['A','B']) # 截取A、B
df1.reindex(index=['A','B']) # 截取A、B两行
删除操作
s1.drop('A') # 删除索引为A的series
df1.drop('c1', axis=1) # 删除label为c1的列
df1.drop('A', axis=0) # 删除label为A的行
五、Mapping和Replace
# create a dataframe
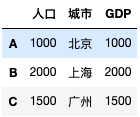
df1 = DataFrame({"城市":["北京","上海","广州"], "人口":[1000,2000,1500]}, index=['A','B','C'])

df1['GDP'] = Series([1000,2000,1500], index=['A','B','C']) # Series默认索引是123,必须要加index参数
//推荐用map的方式添加,不用考虑索引
gdp_map = {"北京":1000,"上海":2000,"广州":1500}
df1['GDP'] = df1['城市'].map(gdp_map)
s1 = Series(np.arange(10))
s1.replace([1,2,3], [10,20,30]) # 将索引为1 2 3的值改为10 20 20















 5486
5486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









