









基本概念
查找的关键在于排序
评价排序算法的标准
- 执行时间:算法执行中关键字比较次数和记录移动次数来衡量
- 所需的辅助空间:若某排序算法所需的辅助空间不依赖问题的规模n,即空间复杂度是O(1),就称其为就地排序,否则就是非就地排序。
- 算法的稳定性:若记录序列中有两个或两个以上关键字相等的记录,Ki=Kj,且在排序前Ri先于Rj排序后的记录序列仍然是Ri先于Rj,称排序方法是稳定的,否则是不稳定的

- 内部排序:所有的记录都能存放在内存中进行排序
- 外部排序:所有的记录不可能存放在内存中,排序过程中必须在内外之间进行数据交换
直接插入排序
插入排序
思想:将待排序的记录Ri插入到已排好序的记录表R1、R2...Ri-1中,得到一个新的,记录数加1的有序表,直到所有的记录都插入完为止。

#include <iostream>
using namespace std;
#define Max_SIZE 100
typedef int keyType;
typedef int infoType;
typedef struct RecType
{
keyType key;
infoType othierinfo;
}RecType;
typedef struct Sqlist
{
RecType R[Max_SIZE];
int length;
}Sqlist;
void InsertSort(Sqlist &L)
{ //前半部分为排好序的,遍历一个进行一次插入排序
int i,j;
for(i = 2;i<=L.length;i++)
{//如果遍历到的确实比前半部分最后一个大,插到尾部即可
if(L.R[i].key<L.R[i-1].key)
{
L.R[0] = L.R[i];//把R[0]作为哨兵,记录要执行此次插入的数据
L.R[i] = L.R[i-1];//把i位置的数据换成i-1的数据,即已经使得前部分的数量+1
//i-1位置的数据现在被记录到了第i个位置,本身存在无意义,可以理解为空出一个位置,看这个位置能不能插
for(j=i-2;L.R[0].key<L.R[j].key;--j)
{ //这个循环是为了把要插入的空位置找到合适的地方
//j+1=i-1
L.R[j+1]=L.R[j];
}
//这个循环结束后肯定能找到合适的位置
L.R[j+1]=L.R[0];
}
}
}最好情况下,记录无需移动(本身就排好序了)关键字比较次数m=n-1
最差情况下(逆序)关键字比较次数m=n^2/2,记录移动次数也是n^2/2
时间复杂度O(n^2),直接插入是一个稳定的排序方法
折半插入排序
与直接插入排序类似,一个序列也将分成排号序的与未排序的两部分,区别在寻找合适位置时,用到折半查找

#include <iostream>
using namespace std;
#define Max_SIZE 100
typedef int keyType;
typedef int infoType;
typedef struct RecType
{
keyType key;
infoType othierinfo;
}RecType;
typedef struct Sqlist
{
RecType R[Max_SIZE];
int length;
}Sqlist;
void BInsertSort(Sqlist &L)
{ int i,low,high,mid,j;
for(i=2;i<=L.length;i++)
{//这个循环是整体的大循环,遍历每一个数据成员
L.R[0] = L.R[i];//设置哨兵,让R[0]储存R[i]的数据,R[i]视为空数据点
low = 1;//初始化low
high = i-1;//初始化high,指向要进行折半查找的数据成员的上一个,排好序的尾部
while (low<=high)
{ //二分查找
mid = (low+high)/2;//c++向下取整
if(L.R[0].key<L.R[mid].key) high = mid-1;
else low = mid+1;
}
for(j=i-1;j>=high+1;--j) {L.R[j+1] = L.R[j];}//移动空节点到high+1
L.R[high + 1] = L.R[0];
}
}插入第i个记录时,需要 向下取整(log2(i-1))+1此关键字比较才能确定它应插入的位置
时间复杂度:n^2
折半插入排序是一个稳定的排序方法
希尔排序
- 先取一个正整数d1(di<n)作为第一个增量,将全部n个记录分成di组,把所有相隔di的记录放在一组中,即对于每个k(k=1,2,··· di),R[k],R[di+k],R[2d,+k]...分在同一组中,在各组内进行直接插入排序。这样一次分组和排序过程称为一趟希尔排序;
- 取新的增量d2<d1,重复1的分组和排序操作;直至所取的增量di=1为止即所有记录放进一个组中排序为止。
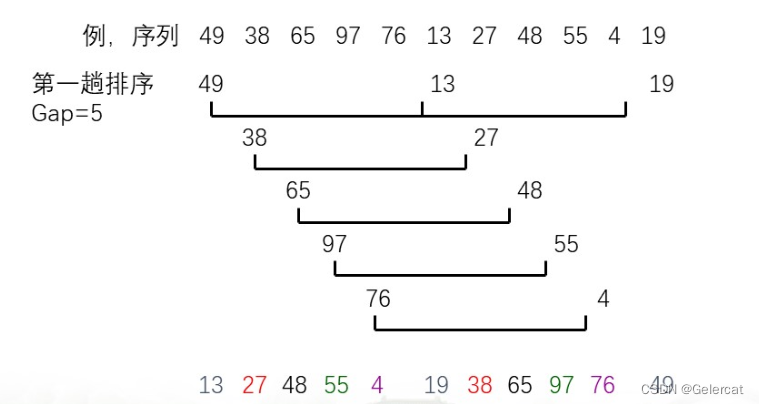
//一趟希尔排序的算法,类似于直接插入排序
void ShellInsert(Sqlist &L,int Gap)
{
int i,j;
for(i=Gap+1;i<=L.length;++i)
if(L.R[i].key<L.R[i-Gap].key)
//此处判定条件是每组的第1和第2个元素进行比较,如果进行过组间的插入排序
//其顺序肯定是正确的,不会触发此处判断,保证了每组只进行一次插入排序
{
L.R[0] = L.R[i];
for(j=i-Gap;j>0&&(L.R[0].key<L.R[j].key);j-=Gap)
L.R[j+Gap]=L.R[j];
L.R[j+Gap] = L.R[0];
}
}
//每次调用即可,dlta里放Gap即可
void ShellSort(Sqlist &L,int dlta[],int t)
{
int k;
for(k=0;k<t;++k)
ShellInsert(L,dlta[k]);
} 
不稳定排序
交换排序
冒泡排序

每一趟排序都能把最大(小)的数找出并放在最后一位,所以称作“冒泡”
#include <iostream>
using namespace std;
#define Max_SIZE 100
typedef int keyType;
typedef int infoType;
typedef struct RecType
{
keyType key;
infoType othierinfo;
}RecType;
typedef struct Sqlist
{
RecType R[Max_SIZE];
int length;
}Sqlist;
void BollenSort(Sqlist &L)
{
int i,j;
RecType temp;
for(i=1;i<L.length;++i)//下标注意,这里我的数据域是从1开始,所以不是通常的length-1
{
for(j=1;j<L.length-i-1;j++)
{
if(L.R[j].key>L.R[j+1].key)
{
temp = L.R[j];
L.R[j] = L.R[j+1];
L.R[j+1] = temp;
}
}
}
}最好情况:正序,只进行n-1次关键字的比较,且不移动数据
最差情况:逆序,进行n-1趟排序
时间复杂度:n^2
是一种稳定的排序方法
快速排序
通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,再分别对这两部分记录进行下一趟排序,以此达到整个序列有序
设待排序的记录序列是R[s...t],在记录序列中任取一个记录(一般取R[s])作为参照(基准、枢轴),以R[s].key为基准重新排列其余所有的记录,所有关键字比基准小的放在R[s]之前,所有关键字比基准大的放在R[s]之后。
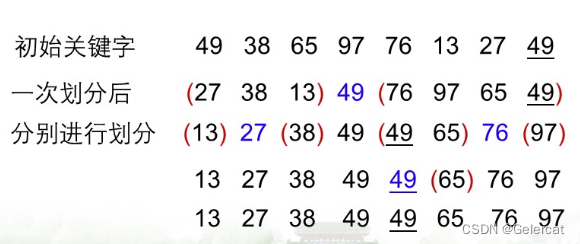
从序列两端交替扫描各个记录,将从后往前第一个关键字小于基准关键字的记录依次放置到序列的前面,将从前往后第一个关键字大于基准关键字的记录从序列的最后端起,依次放置到序列的后面,直到扫描完所有的记录
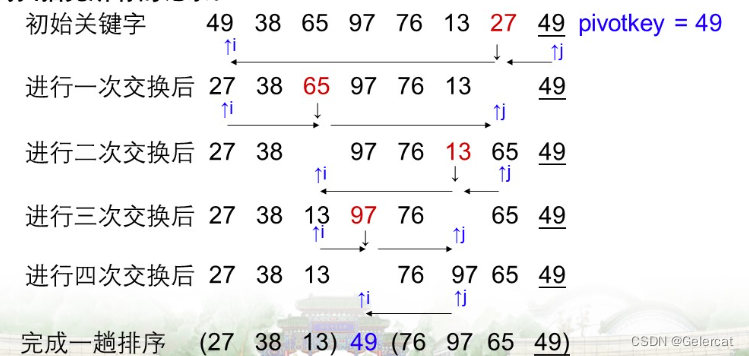
#include <iostream>
using namespace std;
#define Max_SIZE 100
typedef int keyType;
typedef int infoType;
typedef struct RecType
{
keyType key;
infoType othierinfo;
}RecType;
typedef struct Sqlist
{
RecType R[Max_SIZE];
int length;
}Sqlist;
//快速排序
int Partition(Sqlist &L,int low,int high)
{
int pivotkey;
L.R[0] = L.R[low];//设置哨兵节点,R[0]保存此次排序作为pivot的R[low]的数据,
//R[low]空出来,
pivotkey = L.R[low].key;//记录以下pivot.key
while(low<high)//由于是交替遍历,low和high总是在不断从两端逼近的
//因此条件是
{
//从high端扫描数据,直到遇到第一个key比pivotkey小的数据点
while(low<high&&L.R[high].key>=pivotkey){--high;}
L.R[low] = L.R[high];//把这个数据点插入到空出来的R[low]上,同时R[high]空出来
//从low端扫描数据,直到遇到第一个key比pivotkey大的数据点
while(low<high&&L.R[low].key<=pivotkey){++low;}
L.R[high] = L.R[low];//把这个数据点插入到空出来的R[high]上,同时R[low]空出来
}
//结束交替扫描后空出来的总是R[low],此时high=low,就是最终pivot的位置
L.R[low]=L.R[0];
//数据插回去
return low;//返回一下这次结束时的节点,便于递归调用
}
void QSort(Sqlist &L,int low,int high)//需要调用时,传入数据的起点和终点
{
int pivotloc;
if(low<high)//最终,每次递归的low和high都将逐渐靠近,直到low=high
{
pivotloc = Partition(L,low,high);
QSort(L,low,pivotloc-1);//往左边走的递归low永远是第一次传的
QSort(L,pivotloc+1,high);//往右边走的递归high永远是第一次传的
}
}时间复杂度:O(nlog2n)
不稳定的排序方法
选择排序
选择排序(Selection Sort)的基本思想是:每次从当前待排序的记录中选取关键字最小的记录表,然后与待排序的记录序列中的第一个记录进行交换,直到整个记录序列有序为止。
简单选择排序
简单选择排序又称直接选择排序,基本操作如下
第1趟:从1~n个记录中选择关键字最小的记录,并和第1个记录交换
第2趟:从2~n个记录中选择关键字最小的记录,并和第2个记录交换
...
第n-1趟:从第n-1~n个记录中选择关键字最小的记录,并和第n-1个记录交换
#include <iostream>
using namespace std;
#define Max_SIZE 100
typedef int keyType;
typedef int infoType;
typedef struct RecType
{
keyType key;
infoType othierinfo;
}RecType;
typedef struct Sqlist
{
RecType R[Max_SIZE];
int length;
}Sqlist;
//选择排序
void selectSort(Sqlist &L)
{
int i,j,k;
RecType temp;
for(i = 1;i<L.length;++i)
{
j = i;//用j记录i~n组内最小的位置
for(k = i+1;k<=L.length;++k)
if(L.R[k].key<L.R[i].key)
j = k;
if(i!=j)//如果相等的话,说明后面的没有比第i个小的,已经是顺序了,无需交换
{
temp = L.R[i];
L.R[i] = L.R[j];
L.R[j] = temp;
}
}
}时间复杂度:O(n^2)
空间复杂度:O(1)
树形选择排序
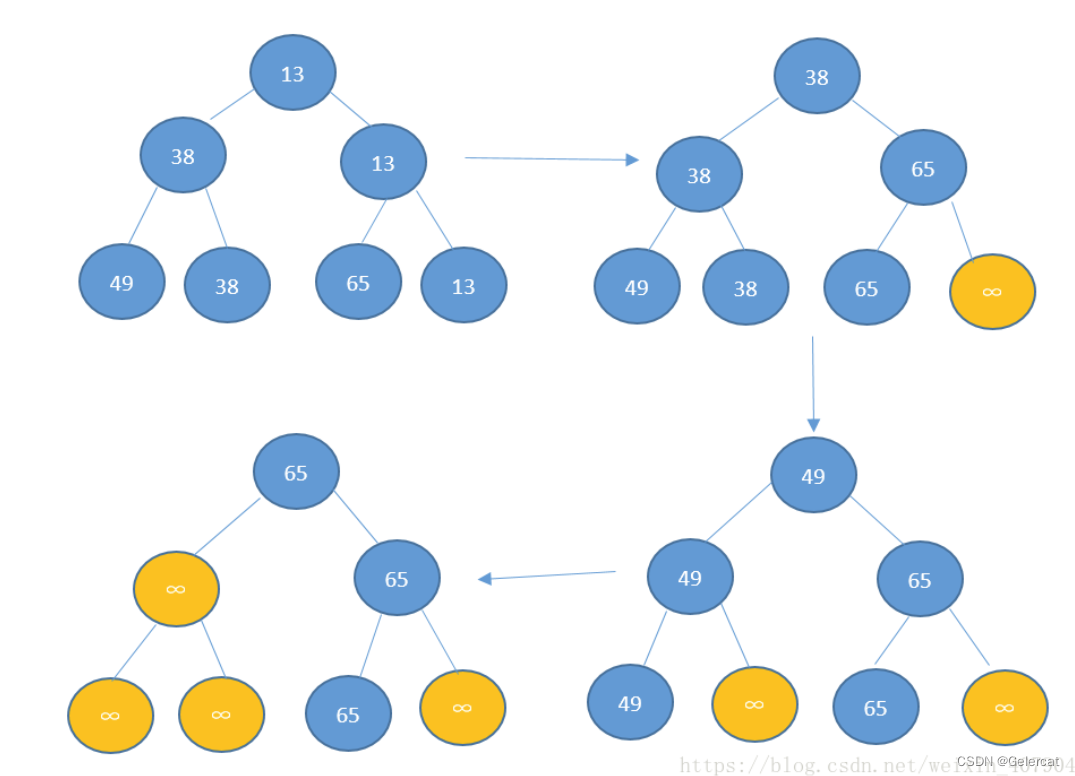
堆排序

将R[1...n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系,在当前无序区中选择关键字最大(最小)的记录
- 堆是一棵采用顺序存储结构的完全二叉树,K1是根节点
- 堆的根节点是关键字序列中最小(大)值,分别称为小(大)根堆
- 从根节点到每一叶子结点路径上的元素组成的序列都是按元素值(关键字值),大根堆时非递增,小根堆时非递减的
- 堆中任一子树也是堆
关于堆的构建和排序:【算法】排序算法之堆排序 - 知乎 (zhihu.com)
平均时间复杂度:O(nlogn)
最佳时间复杂度:O(nlogn)
最差时间复杂度:O(nlogn)
稳定性:不稳定
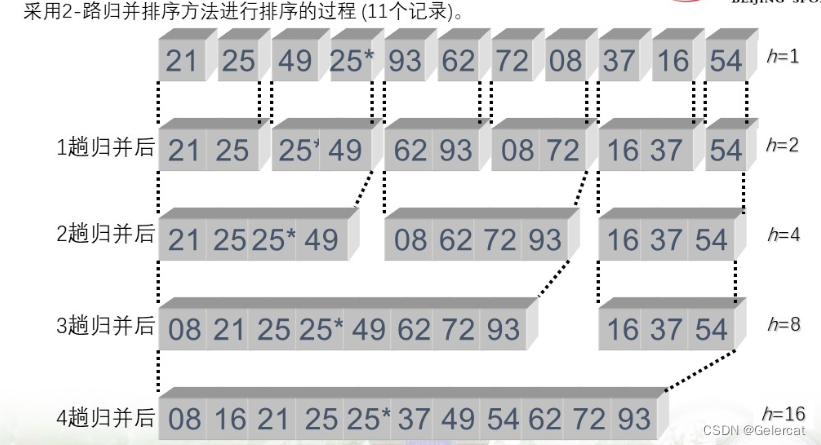
归并排序
将两个或两个以上的有序序列合并成一个有序序列,若采用线性表易于实现,其时间复杂度为O(m+n)
#include <iostream>
using namespace std;
#define Max_SIZE 100
typedef int keyType;
typedef int infoType;
typedef struct RecType
{
keyType key;
infoType othierinfo;
}RecType;
typedef struct Sqlist
{
RecType R[Max_SIZE];
int length;
}Sqlist;
// TR:目标序列,SR:数据序列 i:要进行归并排序的起始位置,
// m:第一端的末尾也是第二段的起点,n:第二段的末尾,也是要进行操作的最后一个位置
void Merge(RecType SR[],RecType (&TR)[Max_SIZE],int loc1,int loc2,int loc3)
{//将有序的SR[loc1...loc2]、SR[loc2+1...loc3]归并为有序的序列TR[loc1...loc3]
int i = loc1;//第一段指针
int j = loc2+1;//第二段指针
int k = loc1;//新序列的位置指针
for(i,j;i<loc2&&j<=loc3;++k)
{
if(SR[i].key<SR[j].key)
TR[k] = SR[i++];
else
TR[k] = SR[j++];
}
if(i<=loc2)
for(i,k;k<=loc3;k++,i++)
{
TR[k] = SR[i];
}
if(j<=loc3)
for(j,k;k<=loc3;k++,j++)
{
TR[k] = SR[j];
}
}
void MSort(RecType SR[],RecType (&TR1)[Max_SIZE],int s,int t)
{ //将SR[s...t]归并为TR1[s...t]
int m;
if(s == t)
TR1[s] = SR[s];
else
m = (s+t)/2;//c++中int相比总是向下取整
MSort(SR,TR1,s,m);//递归
MSort(SR,TR1,m+1,t);//递归
Merge(SR,TR1,s,m,t);
}
void MergeSort(Sqlist &L)
{
MSort(L.R,L.R,1,L.length);
}n个待排序记录的归并次数是log2n,而一趟归并排序的时间复杂度是O(n),则整个归并排序的时间复杂度无论是最好还是最坏情况均是O(nlog2n)。空间复杂度为O(n)
归并排序是稳定的
基数排序
基数排序(Radix Sorting) 又称为桶排序或数字排序:按待排序记录的关键字的组成成分(或“位”)进行排序。
基数排序和前面的各种内部排序方法完全不同,不需要进行关键字的比较和记录的移动。借助于多关键字排序思想实现单逻辑关键字的排序。
基数排序是通过“分配”和“收集”过程来实现排序,是一种借助于多关键字排序的思想对单关键字排序的方法。



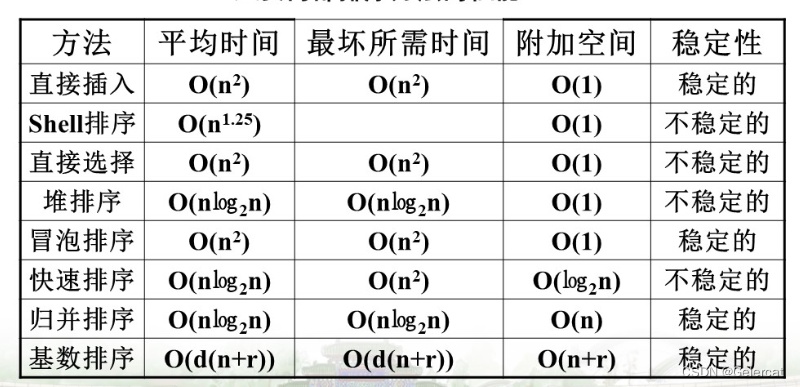
总结
各排序算法评价

代码汇总(可运行)
#include <iostream>
using namespace std;
#define Max_SIZE 100
typedef int keyType;
typedef int infoType;
typedef struct RecType
{
keyType key;
infoType othierinfo;
}RecType;
typedef struct Sqlist
{
RecType R[Max_SIZE];
int length;
}Sqlist;
void InsertSort(Sqlist &L)
{ //前半部分为排好序的,遍历一个进行一次插入排序
int i,j;
for(i = 2;i<=L.length;i++)
{//如果遍历到的确实比前半部分最后一个大,插到尾部即可
if(L.R[i].key<L.R[i-1].key)
{
L.R[0] = L.R[i];//把R[0]作为哨兵,记录要执行此次插入的数据
L.R[i] = L.R[i-1];//把i位置的数据换成i-1的数据,即已经使得前部分的数量+1
//i-1位置的数据现在被记录到了第i个位置,本身存在无意义,可以理解为空出一个位置,看这个位置能不能插
for(j=i-2;L.R[0].key<L.R[j].key;--j)
{ //这个循环是为了把要插入的空位置找到合适的地方
//j+1=i-1
L.R[j+1]=L.R[j];
}
//这个循环结束后肯定能找到合适的位置
L.R[j+1]=L.R[0];
}
}
}
void BInsertSort(Sqlist &L)
{ int i,low,high,mid,j;
for(i=2;i<=L.length;i++)
{//这个循环是整体的大循环,遍历每一个数据成员
L.R[0] = L.R[i];//设置哨兵,让R[0]储存R[i]的数据,R[i]视为空数据点
low = 1;//初始化low
high = i-1;//初始化high,指向要进行折半查找的数据成员的上一个,排好序的尾部
while (low<=high)
{ //二分查找
mid = (low+high)/2;//c++向下取整
if(L.R[0].key<L.R[mid].key) high = mid-1;
else low = mid+1;
}
for(j=i-1;j>=high+1;--j) {L.R[j+1] = L.R[j];}//移动空节点到high+1
L.R[high + 1] = L.R[0];
}
}
//一趟希尔排序的算法,类似于直接插入排序
void ShellInsert(Sqlist &L,int Gap)
{
int i,j;
for(i=Gap+1;i<=L.length;++i)
if(L.R[i].key<L.R[i-Gap].key)
//此处判定条件是每组的第1和第2个元素进行比较,如果进行过组间的插入排序
//其顺序肯定是正确的,不会触发此处判断,保证了每组只进行一次插入排序
{
L.R[0] = L.R[i];
for(j=i-Gap;j>0&&(L.R[0].key<L.R[j].key);j-=Gap)
L.R[j+Gap]=L.R[j];
L.R[j+Gap] = L.R[0];
}
}
//每次调用即可,dlta里放Gap即可
void ShellSort(Sqlist &L,int dlta[],int t)
{
int k;
for(k=0;k<t;++k)
ShellInsert(L,dlta[k]);
}
//冒泡排序,从小到大
void BollenSort(Sqlist &L)
{
int i,j;
RecType temp;
for(i=1;i<L.length;++i)//下标注意,这里我的数据域是从1开始,所以不是通常的length-1
{
for(j=1;j<L.length-i-1;j++)
{
if(L.R[j].key>L.R[j+1].key)
{
temp = L.R[j];
L.R[j] = L.R[j+1];
L.R[j+1] = temp;
}
}
}
}
//快速排序
int Partition(Sqlist &L,int low,int high)
{
int pivotkey;
L.R[0] = L.R[low];//设置哨兵节点,R[0]保存此次排序作为pivot的R[low]的数据,
//R[low]空出来,
pivotkey = L.R[low].key;//记录以下pivot.key
while(low<high)//由于是交替遍历,low和high总是在不断从两端逼近的
//因此条件是
{
//从high端扫描数据,直到遇到第一个key比pivotkey小的数据点
while(low<high&&L.R[high].key>=pivotkey){--high;}
L.R[low] = L.R[high];//把这个数据点插入到空出来的R[low]上,同时R[high]空出来
//从low端扫描数据,直到遇到第一个key比pivotkey大的数据点
while(low<high&&L.R[low].key<=pivotkey){++low;}
L.R[high] = L.R[low];//把这个数据点插入到空出来的R[high]上,同时R[low]空出来
}
//结束交替扫描后空出来的总是R[low],此时high=low,就是最终pivot的位置
L.R[low]=L.R[0];
//数据插回去
return low;//返回一下这次结束时的节点,便于递归调用
}
void QSort(Sqlist &L,int low,int high)//需要调用时,传入数据的起点和终点
{
int pivotloc;
if(low<high)//最终,每次递归的low和high都将逐渐靠近,直到low=high
{
pivotloc = Partition(L,low,high);
QSort(L,low,pivotloc-1);//往左边走的递归low永远是第一次传的
QSort(L,pivotloc+1,high);//往右边走的递归high永远是第一次传的
}
}
//选择排序
void selectSort(Sqlist &L)
{
int i,j,k;
RecType temp;
for(i = 1;i<L.length;++i)
{
j = i;//用j记录i~n组内最小的位置
for(k = i+1;k<=L.length;++k)
if(L.R[k].key<L.R[i].key)
j = k;
if(i!=j)//如果相等的话,说明后面的没有比第i个小的,已经是顺序了,无需交换
{
temp = L.R[i];
L.R[i] = L.R[j];
L.R[j] = temp;
}
}
}
// TR:目标序列,SR:数据序列 i:要进行归并排序的起始位置,
// m:第一端的末尾也是第二段的起点,n:第二段的末尾,也是要进行操作的最后一个位置
void Merge(RecType SR[],RecType (&TR)[Max_SIZE],int loc1,int loc2,int loc3)
{//将有序的SR[loc1...loc2]、SR[loc2+1...loc3]归并为有序的序列TR[loc1...loc3]
int i = loc1;//第一段指针
int j = loc2+1;//第二段指针
int k = loc1;//新序列的位置指针
for(i,j;i<loc2&&j<=loc3;++k)
{
if(SR[i].key<SR[j].key)
TR[k] = SR[i++];
else
TR[k] = SR[j++];
}
if(i<=loc2)
for(i,k;k<=loc3;k++,i++)
{
TR[k] = SR[i];
}
if(j<=loc3)
for(j,k;k<=loc3;k++,j++)
{
TR[k] = SR[j];
}
}
void MSort(RecType SR[],RecType (&TR1)[Max_SIZE],int s,int t)
{ //将SR[s...t]归并为TR1[s...t]
int m;
if(s == t)
TR1[s] = SR[s];
else
m = (s+t)/2;//c++中int相比总是向下取整
MSort(SR,TR1,s,m);//递归
MSort(SR,TR1,m+1,t);//递归
Merge(SR,TR1,s,m,t);
}
void MergeSort(Sqlist &L)
{
MSort(L.R,L.R,1,L.length);
}
void showSqlist(Sqlist& L)
{
cout << "Sqlist size:" << L.length << endl;
for (int i = 1; i < L.length+1; ++i)
{
cout << L.R[i].key << " ";
}
cout << endl;
for (int i = 1; i < L.length+1; ++i)
{
cout << L.R[i].othierinfo << " ";
}
cout << endl;
}
int main()
{
Sqlist testlist = { { {886,1},{3,1},{5,1},{4,1},{7,1},{2,1},{1,1},{9,1} },7};
showSqlist(testlist);
//int dltaa[3] = {5,3,1};
//ShellSort(testlist,dltaa,3);
BollenSort(testlist);
showSqlist(testlist);
};














 1781
1781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









