







机器学习算法是利用计算方法直接从数据中学习信息
可以被模型、公式直接描述的模型不是机器学习
ML的类型
1 非监督学习(聚类)、2 监督学习(分类、回归)、3 强化学习
非监督学习
1) 硬聚类算法
2)软聚类算法,给一个概率
监督学习
模型训练需要:
1 已知的输入(特征)
2 已知的输出(标签)
监督学习的类别
1 回归(预测一个温度) 线性回归
2 分类(做一个决策,是否患病、是否垃圾邮件)决策树、支持向量机(SVM),相对于深度学习运算量小、类神经网络(深度学习的前身)、贝叶斯
模型的选择:
1 数据的类型和大小
2 想要从数据中获得什么?
3 具体的应用场景
选择策略:可以将所有模型都跑一遍,计算错误率,然后再决定选择
ML面临的挑战
1 data的类别和大小不同:从不同商家搜集的资料可能格式不一样
2 需要对data进行预处理
3 花时间找到最拟合数据的模型
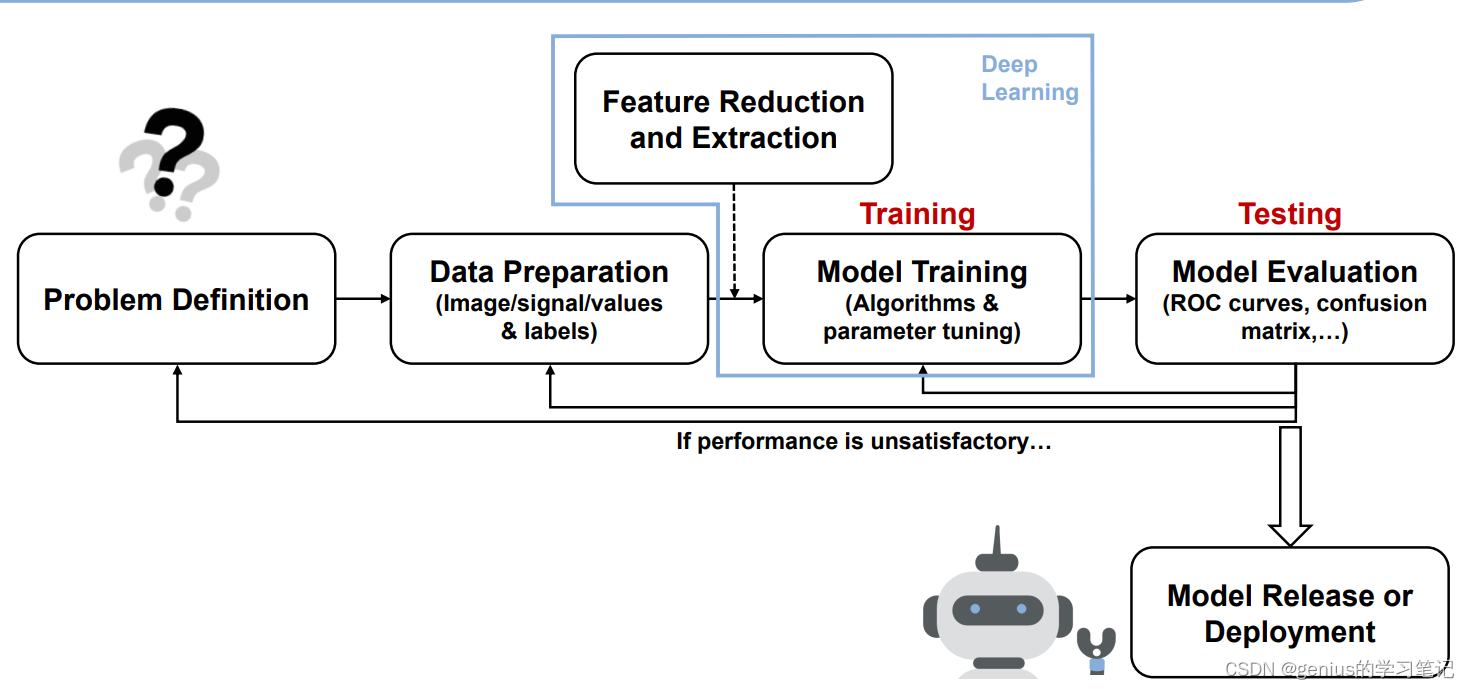
资料的定义->数据的掌握->模型的选择
流程















 3471
3471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









