







概述
>(green!)「 该节的内容都与Java变量有关,都非常重要。下面提供思维导图,为大致的知识网络」
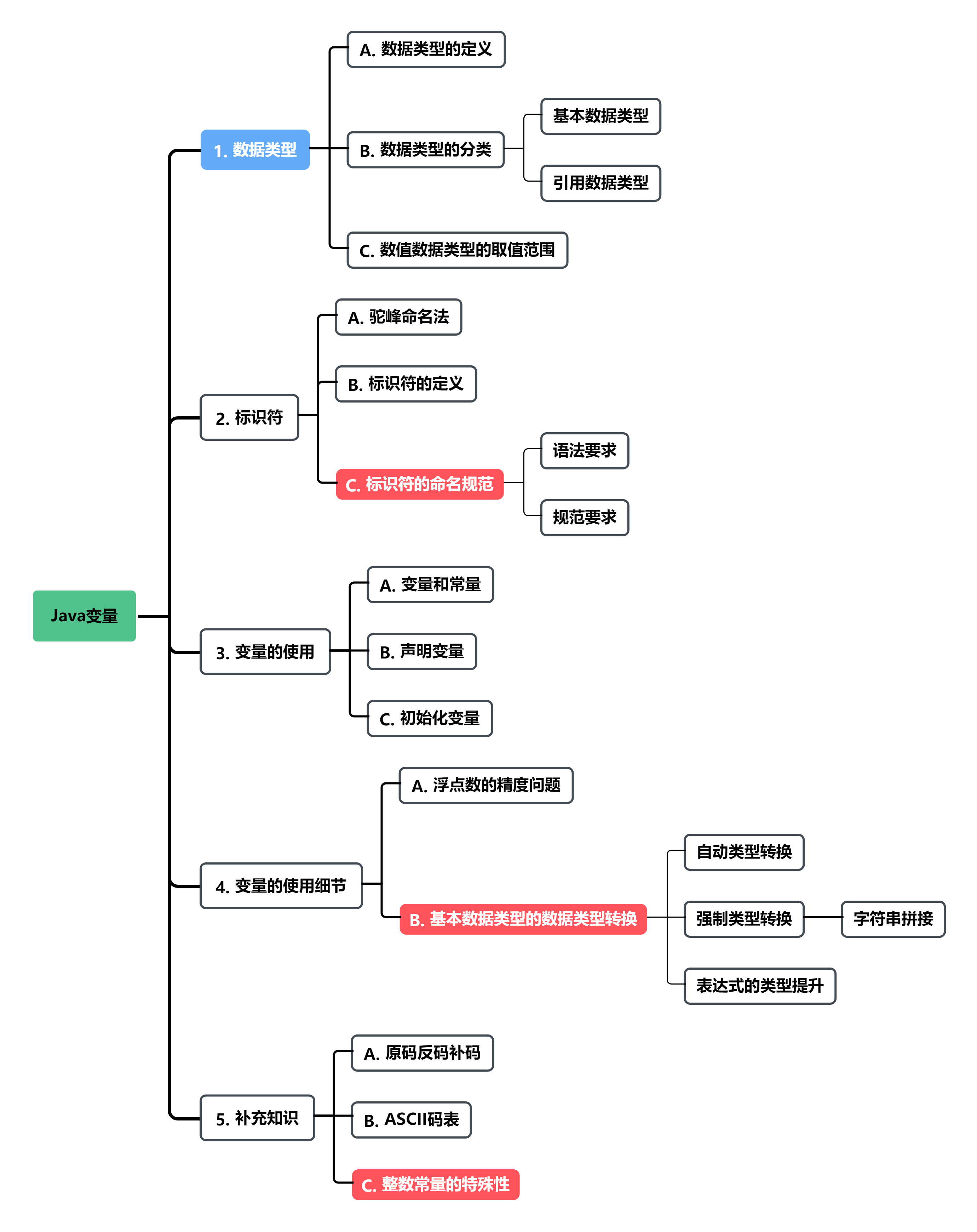
思维导图可以帮助组织知识体系,但是我给出的思维导图细节部分并没有给出,大家可以在复习时自行补全。
数据类型
>(green!)在早年计算机圈中非常流行一句话,叫做程序 = 数据结构 + 算法。
[-] 关于上面这句话
这句话来源于同名书籍,即来自瑞士计算机学家 尼古拉斯·沃斯(Nicklaus Wirth),在1967年的著作 《Algorithms Data Structures=Programs》。程序,我们在上一节中已经讲过了,程序是为了实现现实中的某个需求而诞生的指令集合。明白这一点后,这句话的理解就不困难了。通俗来说,算法相当于逻辑,相当于需求如何实现的过程;而数据结构即数据的表示方式,说白了就是数据如何进行存储,那么最终组成程序就是用逻辑来处理数据,实现相应的功能。坦白来说,或者说一句比较"自大"的话,这句话在现在看来有点像废话,就跟说"文章 = 文字 + 标点"一样没有营养。但不要忘记了我们是生活在21世纪的人类,计算机早就已经深入每一个的生活,而早在上个世纪60年代的计算机"上古"时期,这一句总结对于计算机学科是多么醍醐灌顶。尼古拉斯也因此,获得了计算机界最高荣誉——图灵奖。
额外想提一下的是,现在互联网信息发达了,有些人懂得一些知识了,忘记了自己只是站在巨人肩膀上的"复读机"的本质了,变得不懂得尊重,喜欢抬杠,比如上面我的"自大"言论。希望大家在学习过程中,可以怀着疑惑的心,可以提出不一样的观点,但如果是为了证明"我比伟人还了不起",就完全没有必要了。这不由让我想起,高中物理选修3-3热力学中给出的,关于历史上试图制造永动机的人的评价:

这段评价中肯且大气,多么牛逼!人类虽然早期是很弱小的生物,但一代代的试错、积累和传承经验,一步步走向更强,从茹毛饮血到使用火和工具,到现在使用科技,我们始终都在进步,这才是人类和动物的最大区别。在程序界,还有句经典名言:“不要重复复造轮子”,意为如果已经存在被证明为可以的东西,就不要再自己浪费时间精力创造,直接使用就可以了。
扯远了,现在回到Java的学习上来,毫无疑问:程序的运行显然是离不开数据的,那么数据在Java当中到底如何表示呢?
>(red!)**与几乎所有的程序设计语言一样,Java也是使用变量来存储数据。**这里需要掌握两个重要的概念:
- 变量:程序运行过程中,值可能会发生改变的量(注重变化的可能性而不是确定性)。
- 常量:程序运行过程中,值一定不会发生改变的量。
这里我们先来看一下变量的相关概念,有关常量会在后续说明。
#长风|say#(blue)变量从定义到使用的过程,实际上就是我们编写程序的过程。**这是本节的重点!**而明确数据类型的概念,是变量定义的第一步。既然是讲概念,免不了很枯燥,也没多少代码,需要静下心来认真学习。
什么是数据类型?
>(green!)[-] 数据类型的定义
什么是数据类型?数据类型可以看成是变量的分类,不同数据类型的变量不同类,我们可以从两个角度理解数据类型:
数据最终是要存储在内存中的(从内存角度理解)
- 数据类型可以看成是对内存空间的一个抽象表达方式,一种数据类型对应一种内存空间。
- 该种数据类型的内存空间只能存储该种数据类型的变量,而不能是别的类型变量。
数据被存储后,是需要被使用的(从数据的使用角度理解)
数据类型, 表示的是一组数据的集合,和基于该数据集合的一组合法操作。
也就是说,数据类型不仅表示一组数据的集合,更重要的是它还限制了这组数据能够执行的操作。
在这里,我更倾向于用第二条来解释数据类型,它更形象具体,可以认为它是数据类型的定义。
举两个例子来说明:
- int是Java当中的基本数据类型之一,它表示固定取值范围内的整数取值以及这些整数能够进行的操作,比如能够进行加减乘除,但没有求长度,求宽度之类的操作。
- String是Java当中最常用的引用数据类型,它表示字符串类型的取值,以及这些字符串可以进行的操作,比如可以进行字符串“+”拼接,可以求长度,但没有减法、乘法等操作。
总之,数据类型的意义在于:告诉Java的编译器,定义了何种类型的变量。因为只有明确了数据类型,JVM才知道需要多大内存空间存储它,怎么来存储它。
>(red!)除了数据类型的定义外,和数据类型相关很紧密的一个定义就是强类型语言。
>(orange!)[-] 关于强类型语言
强类型语言:强类型语言是一种强制类型定义的编程语言。在这种编程语言中,**任何变量都必须有数据类型,并且一个变量一旦确定数据类型,如果不经过类型转换,则它永远就是该数据类型了。**强类型语言对于变量的数据类型限制得相对严格,变量不能轻易改变数据类型,所以强类型语言编写的程序不会因为数据类型的随意转换而出错,相对更安全。典型的强类型语言有:Java、C#、Python、C++等,目前流行的绝大多数编程语言都是强类型语言。
注:既然有强类型语言,就有弱类型语言。在弱类型的编程语言中,变量的数据类型是不定的,可以随时改变。弱类型编程语言的代码会更加灵活多变,但也更容易出错。比较典型的弱类型语言就是PHP。
相比较于灵活性,主流的编程语言还是更看重安全性,多数编程语言都是强类型语言。
Java是典型的强类型语言,这就意味着Java当中的每个变量都必须有它的数据类型,并且数据类型不会轻易改变。
数据类型的分类
>(green!)明白了数据类型的概念后,我们再来看一下数据类型的分类:
从大的分类角度来说,Java实际上只有两种数据类型:
- 基本数据类型
- 引用数据类型
接下来按照不同的分类,来具体了解一下Java的具体数据类型。
基本数据类型
>(green!)**基本数据类型(Base Data Type)**指的是由Java语言默认提供的八种数据类型。
这八种数据类型是JVM内置设定的,所以有些书籍也称它们是**“内置数据类型”**。
但是不管怎么叫,这八种数据类型都是Java已经预先设定好的数据类型,它们的存储空间一般都是固定的。
>(red!)更进一步细化一下,基本数据类型又可以再分类为以下四类:
- 整型
- 浮点型
- 字符类型
- 布尔类型
在具体看上述四种分类,具体的数据类型之前,先在这里讲一下计算机中数据存储单位的两个概念:
- 位(bit):位是最小的存储单位,每一个位存储一个1位的二进制码,即1位存储一个0或者1
- 字节(Byte):一个字节由8位组成。
整型
>(red!)[-] 关于整型
整型,也叫整数型。
整型这种数据类型,存储数据是以二进制有符号数的形式存储的。
这意味着占用内存空间越大,其所能表示的数值的范围就越大。如果你不想深究何为有符号数,知道这些也就足够了。
而如果你想继续了解它,可以参考文档补充知识点_有符号整数。
这里仅举一个简单的例子:
比如使用一个字节八位存储整型,那么最高位的0/1分别表示正数和负数,剩下的七位则是数值位,那么一个字节的整型取值范围就是[-128,127]。
>(green!)更具体的来说,整型又有四种:
1. byte
1. byte类型也叫字节型,仅占1个字节内存空间,即8位。
1. byte 是占用内存空间最小的整型,只有在极度需要节省空间的场合才会被使用,实际Java开发几乎不会使用。2. short
1. short 也叫短整型,占用2个字节内存空间,即16位。
2. 短整型只比字节型稍大,实际开发中short使用频率也不高。
3. int
1. int 本身就是单词integer的缩写,它就是整型的代名词,占用4个字节内存空间。
2. int 是最常用的整数数据类型,实际开发中整数往往都是int类型的。4. long
1. long 也叫长整型,占用8个字节内存空间。
2. 当int类型不足以存储数据时,就需要使用long类型存储数据,在需要很大的整数时才需要使用long类型。
浮点型
>(red!)[-] 关于浮点型
浮点数是一个比较独特的概念,它在计算机中的存储表示和有符号整数又有所不同,遵循IEEE754标准。
IEEE754标准的浮点数表示方式牵扯到《计算机组成原理》等计算机基础知识。
严格来说即便不掌握也不非常影响做一名Java开发,但是作为基础的知识,仍然建议每位同学弄懂它。
如果你不想再去翻一遍教科书,可以参考补充知识点_IEEE754标准这一文档进行学习。
>(green!)如果你实在不想去领略计算机组成原理的魅力,那么简单来说:
浮点数的表示方式可以理解为用二进制科学计数法来表示一个二进制数,即:a2 × 2n(其中a2是一个二进制数,n是指数)
在IEEE754标准下,将a2称为尾数,n称之为阶码。
于是,IEEE754标准下的浮点数,就有了两个最重要的特点:
因为存在指数运算(阶码),所以浮点数可以表示非常大和非常小的数!
比如:1 * 10-100 这个数非常小,1 * 10100这个数就非常大。
这是浮点数的优点,它的表示范围非常大!
因为计算机存储的限制,尾数的位数必然是有限的,所以这就导致浮点数的精度是有限的!
假如规定尾数只有4位,那么能够表示的有效数字是不可能超过4位的。
比如 1.234 * 100100 这个数,它非常大。但是它最多就只能表示1234四个数,这就是精度有限。
除此之外,浮点数还有一些很独特的设定,由于不是学习重点,这里不再细表,请自行看文档学习即可。
>(red!)具体来说,浮点型有两种:
- float
- float 即单精度的浮点数,占用4个字节内存空间,32位。
- float 相对于double占用空间更小,但它不如double精度高,也没有double表示范围大。
- double
- double 双精度的浮点数,占用8个字节内存空间,64位。
- double尾数位长度更大,更精确,整体表示范围也更大,是更常用的浮点数类型。
字符型
>(red!)[-] 关于字符型
所谓字符,指的是像字母,汉字、标点等类似的符号。
那么字符型,就是用来表示这些符号的数据类型。
很明显,计算机只能存储二进制数据,不可能也没能力直接存储一个符号(字符)。
计算机中存储字符,实际是通过存储一个数值来映射对应的字符。比如:
现在我规定一个整数值1对应字符"a",那么计算机中存储1,就能够对应上字符"a"。
在上述案例中,把某个字符对应的一个整数值,称之为该"字符的编码值"。
而如果用一张表格来存储字符和编码值的映射关系,这就是编码表。
关于编码的相关概念,我们会在后面详细讲解,这里有个简单的概念认识就可以了。
>(green!)Java中的字符型只有一个,那就是char类型。
char本身就是单词"字符"character的缩写,每一个char类型变量都表示某一个字符,它具有以下特点:
Java中的char类型变量占用2个字节内存空间。
Java中的char类型存储字符,实际是存储了一个16位的无符号正整数值。
注:十六位无符号数,16位全部用来存储数值,只能表示整数,取值范围是[0,65535]。
即Java中的char类型能够表示编码值在[0,65535]范围内的的所有字符。
使用的编码集是Unicode编码集。
扩展一下,char类型在代码中的表现:
如果直接输出一个字符型变量:
char c = 'a'; System.out.println(c);结果是:
a
字符类型如果直接输出,就会在控制台打印这个字符。
如果字符型变量参与运算,是可以参与数值运算的:
char c = 'a'; System.out.println(c + 10);结果是:
107
字符型变量参与运算,是编码值参与运算。
字符a的编码值是97,所以输出107。
综上,Java中字符型char就是存储一个正整数,来表示字符。只要这么想,基本不会出问题。
布尔类型
>(red!)[-] 关于布尔类型
所谓布尔类型就非常简单了,就是表示真(true)和假(false)。
和字符类型类型,布尔类型也只有一个:boolean类型,它具有以下特点:
- boolean,布尔类型,用来存储真(true)和假(false)两种布尔值,没有其它取值。
- 布尔类型变量具体占用内存的大小,要分情况而定(以下作简单了解)根据JVM规范中提供的数据:
- 一个独立的boolean类型变量当作int处理,占4个字节。
- 在boolean数组当成byte数组处理,一个boolean元素占1个字节,节省空间。数组的概念我们马上就会学习,如果你不清楚,可以暂且记下。
- 没了。
数值基本数据类型的取值范围(重要)
>(green!)「 基本数据类型中的整型和浮点型都是表示纯粹的数值的,所以它们能够表示的数值范围我们必须要知道!」
整型的取值范围是很容易得到的,通过数值位的长度n(数值位 = 总位数 -1)可以直接算出最大值是2n -1,最小值则是-2n 。
浮点型的取值范围并不是一个普通的区间,严格来说它很复杂,下面表格给出的取值范围只是一个大概值,并不十分准确。如果你想了解最准确的浮点型取值范围,还是请查看 补充知识点_IEEE754标准 学习。
Java数值类型的取值范围
基本数据类型 字节长度 大小(位) 最小值 最大值 取值范围 byte 1字节 8bit -2^7 2^7-1 -128 ~ 127 short 2字节 16bit -2^15 2^15-1 -32768 ~ 32767 int 4字节 32bit -2^31 2^31-1 -2147483648 ~ 2147483647(21亿出头) long 8字节 64bit -2^63 2^63-1 -9223372036854774808 ~ 9223372036854774807(大概922亿亿) float 4字节 32bit - - 大约 ±3.403E38(有效位数7~8位) double 8字节 64bit - - 大约 ±1.798E308(有效数字16~17位)
引用数据类型
>(green!)限制于我们目前学习的知识,还无法给引用数据类型下一个准确的定义。so,我们这里只简单了解一下就可以了。
仅需要记住下面一点就可以了:
Java当中有且仅有两种数据类型,那就是基本数据类型和引用数据类型。 只要不是四类八种基本数据类型,那么它都是引用数据类型。 因为基本数据类型很少,所以我们在Java开发中碰到的变量,非常多都是引用数据类型。最常见的也是最常用的引用数据类型就是String,它表示字符串。
关于引用数据类型,我们会在后面详细讲解。在本节的末尾,我们会简单了解一个String类型的概念。
数据类型的概念搞清楚后,还无法直接使用变量,还需要了解—— **标识符 **的概念。
标识符
相关概念
>(green!)[-] 问题1:什么是标识符?
上面我们提到过,编程的过程就是变量使用的过程。在这个使用变量的过程中,毫无疑问是需要知道变量的名字,才能更方便得去使用它。而在Java代码中,使用 标识符 表示各种各样的名字,也包括变量名。
[-] 问题2:标识符有什么用?
上面已经说过了,标识符是一个表示名字的字符串。
[-] 问题3:需要标识符起名字的常见结构有哪些?
主要有:
- 类名(包括后面会学习的接口名、注解名等)
- 方法名(main就是一个方法名)
- 变量名
- 包名
>(red!)思考题:
现在有一个Hello.java的文件,里面有两个class,为 public class Hello 和 class Test 。
请问:在Hello.java文件的同包下创建类 public class Test 能不能成功?
不行,在Java当中,同包下是没有同名类的,不管这个class是public修饰还是非public的!
标识符命名规范
>(green!)就跟父母给孩子起名字也不是乱起的一样,标识符在命名时,也有自己的独特规范,称之为"标识符命名规范"。 一名合格的Java程序员,应该从写好标识符的命名规范开始。
语法要求
>(green!)中国人起名字上户口总不能叫"Michael"或者"Maria"吧。对于标识符而言,如果不符合下列语法要求,会直接编译报错。
- 标识符的开头必须是:
- 字母(A~Z 和 a~z)
- 下划线(_)
- 美元符号($)
- Unicode 字符集中编号为0xC0以及它后面的所有符号
- 标识符的组成必须是:
- 数字(0~9)
- 字母(A~Z 和 a~z)
- 美元符号($)
- 下划线(_)
- Unicode 字符集中编号为0xC0以及它后面的所有符号
几个注意事项:
- 标识符不能以数字开头。
- 不能是Java中的关键字和保留字。
- 标识符严格区分大小写。
>(red!)课堂提问:
以下标识符命名符合语法要求的有哪些?
HelloWorld,_985,$bS5_c7,class,长风,Class ,DataClass#,_98.3,Hello World,好きだ
约定俗成的规范
>(green!)以上只是语法范畴的标识符命名规则,但就像人可以起名叫"张三"、"李四"这种名字上户口,但几乎没人这么做一样。
在符合语法的前提下,标识符还有一套约定俗成的命名规则。
详细内容可以参考 王道Java开发编程规约 ,我们后面会详细讲解该文档。
在详细说明规范之前,先要看种一种最常用的标识符命名规则:驼峰命名法。
驼峰命名法
>(green!)在计算机中,起名字是很常见的操作,为了起好名字,驼峰命名法就被发明了。所谓驼峰,指的是当多个单词共同组成一个字符串时,不同单词的大写和小写间隔起来,形成一种像驼峰一样的凹凸,故称之为驼峰命名法。 使用驼峰命名法可以清晰得看到不同单词组成的新字符串。驼峰命名法主要有两种:
小驼峰式命名法
- 多个单词组合成一个字符串
- 第一个单词的首字母 小写 。
- 从第二个单词开始,首字母都要大写。
例如:myName,myFirstJavaProgram
大驼峰式命名法
- 多个单词组合成一个字符串
- 第一个单词的首字母 大写 。
- 从第二个单词开始,首字母都要大写
例如:MyName,MyFirstJavaProgram
具体规范
>(green!)在符合语法的前提下,标识符在给不同结构命名时会有不同的规则,这样的目的是更好得区分标识符命名的是何种结构。
分类别来说:
- 类名(包括后面会学习的接口名、注解名等)应该使用大驼峰命名法。
- 变量和方法的命名标识符应该使用小驼峰命名法。
- 包名的命名:
- 多数公司开发的包名会 以反转公司的域名作为开头。例如在百度做开发,项目的包名开头应该是com.baidu.xxx
- 包名的 单词字母应该全部小写,禁止使用大写。
- 多级包名用"."隔开。
除此之外,还有一些统一的规范,也必须要遵守:
- 标识符的命名开头和结尾都禁止使用下划线"_“和美元符号”$"。
- 任何标识符的命名都禁止使用莫名其妙的字母组合、拼音或者拼音英文组合,更不能直接使用中文。特殊地如baidu、beijing或者和业务相关的拼音除外。
总之,标识符的命名尽量使用合法的、拼写准确的英文单词,核心的追求是"见名知意"。比如一个好的变量命名应该能够让人通过名字就知道,该变量的作用。
标识符的命名规范,可以从源码、大神的代码中学习,也是一个逐渐积累的过程。
>(red!)课堂提问:
以下哪些标识符的命名规则符合规范:
- public class student{}
- public class TestDemo{}
- int Num
- String name
- public class Persondemo{}
- 包名 Test.Demo
- 包名 com.baidu
- int nianling
- String 名字
错误示范
>(green!)由于标识符的命名规范实在过于重要,所以给出一些经典的错误示范,希望大家以此为戒。
如何写出让同事无法维护的代码呢?(并成为公司中的头号"重要人物")
- **容易输入的变量名。**比如:qwer,asdf等。
- 让人摸不透你的心思,需要来请教你。
- **单字母的变量名。**比如:a,b,c,x,y,z(如果不够用,可以考虑 a1,a2,a3,a4,….)
- 体现了极简的编程风格,简约就是美。
- **有创意地拼写错误。**比如:getStuedntAge,prnitTeacher等
- 这样写同事根本无法准确定位问题,那就需要我出场了。
- 不太大众化的缩写。比如:WTF,RTFSC …… (使用拼音缩写也同样给力,比如:BT,TMD等)
- 没有较强的联想能力还来做程序员?为公司筛选人才。
- **单纯使用下划线。**比如:直接命名为"_“或者”_abc"
- 真正的程序员不走寻常路。
- **使用不同的语言。**比如混用英语,德语,或是中文拼音。
- 程序员精通多国语言是正常的。
- **l和1一起用。**字母 l 和数字 1 有时候是看不出来的。
- 脑筋要好,眼睛要尖,程序员必备。
- 乱写注释。比如注释和实际代码不同,注释中写废话等等。
- 编不下去了,别这么做就行了。
我可是开玩笑的,如果谁信以为真并且这么做了,那就是"大聪明"了。
变量的使用
>(green!)学完了数据类型和标识符两大概念后,我们就可以在Java代码中使用变量了。先回顾一下之前讲过的常量与变量的概念:
- 变量:程序运行过程中,值可能会发生改变的量(注重变化的可能性而不是确定性)。
- 常量:程序运行过程中,值一定不会发生改变的量。
我们先来看一下常量的概念。
常量
>(green!)[-] 什么是常量?
在程序运行过程中,其值不会发生改变的量,是绝对不会发生改变的量才能称之为常量。
[-] 常量有哪些分类?
从大的分类来说,常量主要分为两类:
- **字面值常量,在Java代码中,所有直接写值的量都是字面值常量。**包括:
- 整数常量:直接写在代码中的整数都是。例如1、2、3等。
- 小数常量:直接写在代码中的小数都是。例如1.1、1.2、1.3等。
- 字符常量:直接写在代码中的,使用单引号引起来的字符都是。例如’A’、'a’等。
- 布尔常量:直接写在代码中的布尔值,只有true和false两个。
- 字符串常量:直接写在代码中的,使用双引号引起来的字符串都是。例如"HelloWorld"、"hello"等
- 空常量:空常量是引用数据类型独有的一种取值,只有null一个。(后面会讲,这里先记一下)
- 自定义常量,通过语法自由地定义一个常量在代码中使用。(面向对象再讲)
字面值常量比较简单,了解即可。接下来主要看变量。
变量
>(green!)[-] 什么是常量?
程序运行期间,其值在某个范围内,可能会发生改变的量就称之为变量。需要强调的是,变量指的是该数据的值会发生变化的可能性,只要有可能被改变,这个量就是变量。反观常量是不可能随着程序运行而发生变化的。
变量是程序中最常见的存储数据的方式,要想使用变量一般都需要两步:
- 声明变量
- 初始化变量
声明变量
>(green!)[-] 什么是声明变量?
声明变量的目的是告诉编译器,变量的数据类型和变量的名字。
由于有这两个目的,所以变量的声明语法就需要两个部分。
声明变量的语法:
声明变量的语法
// Java是强类型语言,每个变量都需要声明它的数据类型 数据类型 变量名;
>(red!)思考:
仅仅声明的变量能够直接使用吗?
初始化变量
>(green!)[-] 什么是初始化变量
声明后的变量还没有值无法使用,给变量赋初始值的过程就是初始化。
既然是赋值,直接写"="连接值就可以了。
注:实际上仅仅声明变量那行代码在Java中是没有意义的,编译器会自动忽略那行仅声明变量的代码! 相当于那行代码被注释了。既然都没有编译进二进制字节码文件,就更不可能开辟空间存放它了。
初始化变量的语法:
初始化变量的语法
变量名 = 变量值; // 一般情况下声明和初始化都合起来使用 数据类型 变量名 = 变量名;
一般,我们把变量声明和初始化连接起来称之为变量的定义。以下提供几个案例:
变量的定义案例
int a = 10; char b = 'A'; double c = 0.1; String str = "Hello";
>(red!)除以上说明和使用外,这里还要特别强调以下:
Java的变量类型有好几种,这里我们讲的变量指的是局部变量(Local Variable)
关于局部变量,这里要明确以下几个概念:
- 在Java当中,把定义在局部位置的变量,称之为局部变量。
- 那么什么是局部位置呢?说白了就是定义在大括号内部的变量。主要包括以下:
- 方法体大括号内部的变量。典型的main方法大括号之中定义的变量。
- 其它代码块当中定义的变量。代码块的概念会在稍后章节中详谈。
- 局部变量最重要的特点是,被代码块(大括号)限制了作用域,仅在大括号内部生效。
注意事项
>(green!)在定义变量的过程中,存在很多细节上的使用注意事项,比如:
Java当中的整数字面值常量,默认当作int处理。假如你想使用字面值整数定义一个long类型变量,那么该字面值常量的后面应该加上一个"L"区分(禁止使用小写"l")。
例如:
字面值常量定义long类型变量
long a = 123L; // 下列方式严格禁止 long b = 123l; //请问这是1231吗?Java当中的小数字面值常量,默认当作double处理。假如你想使用字面值小数定义一个float类型变量,那么该字面值常量的后面应该加上一个"F"或"f"区分。
定义一个变量是有它的作用范围的,这个范围通常用{}来界定,同样一个{}不能有同名变量。
虽然Java语法允许一行定义多个相同数据类型的变量,但规范的Java代码禁止这样做!
例如:
禁止一行定义多个变量
// 下列做法不允许 int a, b = 10, c, d = 10; // 应该改成下面这样 int a; int b = 10; int c; int d = 10;一行定义多个变量,不仅格式不美观,到底定义了多少变量也不直观,不要这么做。
变量使用的细节问题
String类简单了解
>(green!)String类是JDK源码中提供的一个固有类,也是源码中最常被使用的类型,是最常见的Java引用数据类型。
关于String类的详细内容,我们留到后续再去讲解。这里,我们仅简单了解一下String类。
String的意思是字符串,所以在Java当中,String类型是用来表示字符串的。Java代码中,所有用双引号直接引起来的内容,都是String类的一个实例,比如"hello world!"。
一个String类型局部变量的声明、初始化语法是下面形式:
String str = "hello world!";当然,你直接使用输出语句在控制台输出字符串,也是使用了Java的String类。
除此之外,在当前这个阶段,还希望大家能够了解的一个知识点是:如何判断两个String字符串变量的内容一致呢?
比如给你两个字符串变量:
两个字符串变量
String s1 = "hello"; String s2 = "hello";s1和s2的内容是一致的,如何判断呢?这里,我直接给出具体做法,大家可以记忆一下,这些内容在后续再详细学习:
s1.equals(s2);以上结构,用于判断两个字符串变量s1和s2的内容是否一致。它会返回一个布尔类型值,如果一致返回true,否则返回false。
当然,对于s1和s2,它们equals比较的结果是:
true
>(green!)切记:
比较两个字符串变量的内容是否一致,不能使用“==”号!
浮点数的精度问题
>(green!)之前,在讲浮点数的时候,我们就已经讨论过了,浮点数因为遵循IEEE754标准,有一个比较大的缺点:
由于表示有效数字的位数是有限的,所以精度是受限的。
下面我们看两个经典案例:
- 使用Java代码计算 10 / 3.0
- 使用Java代码计算 1 - 0.9
这里涉及一个二进制表示小数的转换问题,规则如下:
十进制正小数(0.开头)转换成二进制,先用小数部分乘以2,取结果的整数部分(必然是1或者0),
- 然后小数部分继续乘2
- 直到小数部分为0,或者已经达到了最大的位数
- 最终的结果(0.开头)正序排列
显然,我们可以得到以下结论:
很多十进制小数转换成二进制时,会存在循环小数的情况。那么有限有效数字的浮点数就不能准确表示这个数字了,那些超出表示位数的数据就被截断丢失了,数据失真,精度丢失,这就是浮点数的精度问题。
最后再说一点:
float和double类型主要是为了科学计算和工程计算而设计的,当你使用它们来表示小数时就已经确定精度对你而言不重要了。
它们执行的二进制的浮点数运算,是在广泛的数字范围上较为精确而快速的近似计算。
float和double都不适合用于精确计算的场合,尤其不适合用于货币运算。
>(red!)牛刀小试
下列代码会输出什么?
浮点数精度问题练习1
double a = 0.1; float b = 0.1F; System.out.println(a == b);下列代码会输出什么?
浮点数精度问题练习2
float a = 0.1F; float b = 0.10000000000000000001F; //中间18个0 System.out.println(a == b);先思考一下答案,然后用IDEA运行代码,验证猜想。
基本数据类型的数据类型转换
>(green!)之前我们提到过,Java是强类型语言,一个变量必须明确它的数据类型, 并且数据类型一旦确定不能随意更改。但不能随意修改并不是不能更改,而是需要一定的条件,Java中变量的数据类型由某一种转换为另一种,我们将这个过程叫做数据类型转换。我们之前提到过:声明是告诉编译器变量的数据类型,那么数据类型的转换,也同样是要告诉编译器怎么转换,转换成了什么数据类型。
数据类型的转换又可以分为两类:
- 自动类型转换
- 强制类型转换
接下来,我们以基本数据类型为例,讲一下这两种类型转换。当然,首先要明确的是:基本数据类型的数据类型转换必须在byte、short、int、long、float、double这些数值类型和char类型之间进行,boolean类型不参与基本数据类型的数据类型转换。
自动类型转换
>(green!)自动类型转换的关键点就在于"自动"这两个字上,到底谁在"自动"帮我们完成类型转换呢?当然是编译器。编译器帮助我们完成类型转换,这意味着我们程序员不需要写额外代码,就可以自动完成类型转换。
对于基本数据类型而言,自动数据类型发生在"小取值范围"转换为"大取值范围"的数据类型转换之间。 但是要注意:
- 整型自然是占用内存空间越大,取值范围就越大。
- 浮点型的float虽然只占4个字节,但是它比所有整型的取值范围都大。
- 该体系中double是取值范围最大的,byte是最小的。
- **char类型比较特殊,在参与数值类型的自动类型转换时,是编码值参与了转换。**而且由于char类型的编码值范围是[0,65535],所以只有int及以上数据类型的取值范围比char类型大。
除了上面四点,还有一个非常重要的不能忽略的点:浮点数有精度问题,某些整型在自动转换成浮点型时,会出现精度丢失数据失真的问题。
以上内容,可以总结为下列一张图:
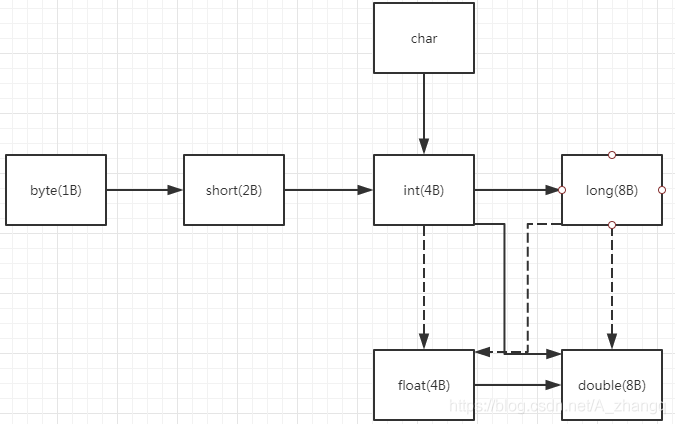
注:
- 以上图中,实线虚线都表示能够发生自动类型转换,箭头表示类型转换的方向。
- 实现表示转换过程中不会有精度问题,虚线表示 可能会产生精度丢失。
强制类型转换
>(green!)自动类型转换是小取值范围到大取值范围数据类型的转换,一般不会出现问题,所以能够自动发生。与自动类型转换相对应的就是强制类型转换,是从"大取值范围"的数据类型转换到"小取值范围"的数据类型。"大变小"的强制类型转换极易造成数据溢出导致数据失真,除非特别有必要,一般情况下不要做强制类型转换。
正是因为强制类型转换比较危险,所以编译器不会自动完成类型转换,而是需要程序员手动写代码完成类型转换。
强制类型转换的语法是:
强制类型转换的语法
// 做强转要慎重考虑再进行 目标数据类型 变量名 = (目标数据类型)(被转换变量的变量名);
表达式类型提升
>(green!)如果表达式当中存在多种数据类型 变量 参与运算,由于表达式的运算结果是唯一的,所以结果 变量 的数据类型将会提升到"最大取值范围"的那个。有以下规则:
- byte、short、char之间不互相转换,一旦发生运算,一律自动转换为int进行运算,结果是int
- byte、short、char任何数据类型与int进行计算,一律自动转换为int进行计算,结果是int
- byte、short、char、int任何数据类型与long进行计算,一律自动转换为long进行计算,结果是long
- byte、short、char、int、long任何数据类型与float进行计算,一律自动转换为float进行计算,结果是float
- byte、short、char、int、long、float任何数据类型与double进行计算,一律自动转换为double进行计算,结果是double
注:char类型比较特殊,在参与数值类型的计算时,是编码值参与了运算。比如:
char c = 'a';如果上述变量c参与数值运算,那么就是编码值97参与运算!
特殊的:
String作为字符串类型,也可以使用" + “在表达式中参与运算,称之为"字符串的拼接”。 任何表达式一旦有字符串拼接运算,那么结果必然是String类型。
>(red!)最后,还是要强调一下:
只要表达式中存在任一变量,那么表达式的最终结果数据类型就遵循"表达式的类型提升"。
>(red!)牛刀小试
看程序说执行结果:
表达式类型提升练习题
System.out.println('a'); System.out.println('a' + 1); System.out.println("hello" + 'a' + 1); System.out.println('a' + 1 + "hello"); System.out.println("5 + 5 = " + 5 + 5); System.out.println(5 + 5 + " = 5 + 5"); System.out.println(5 + 5.0); System.out.println(5 + "5" + 5.0);
总结
>(green!)基本数据类型的类型转换,可以总结出以下规律:
八种基本数据类型中,只有boolean类型不能进行类型转换,其他七种都可以互相转换(自动或强制)。
多种数据类型混合在一起进行运算,先全部提升为"最大取值范围"的数据类型,再进行计算。
byte、short、char使用的时候尤其注意取值范围,若参与运算都会自动提升到int。
“小取值范围”—>"大取值范围"称之为自动类型转换,不需要写代码处理,排序是:byte < short(char) < int < long < float < double~
“大取值范围”—>"小取值范围"称之为强制类型转换,必须要显式写代码处理,否则会编译报错,语法是:
目标数据类型 变量名 = (目标数据类型)(被转换变量的变量名);强制类型转换很容易导致数据失真,谨慎使用。
除了基本数据类型外,引用数据类型也能够发生类型转换,但是条件会苛刻的多,出错的后果也会更严重,这个我们面向对象再详谈。
>(red!)牛刀小试
补充知识
>(green!)关于Java变量的使用,补充一些必要的知识,虽然标题是补充,但是仍属于必须掌握的知识。
原码、反码与补码
>(green!)计算机中的数据是二进制的,而且也不像生活中用" - "负号表示负数那么简单。在计算机中,机器数的表示分为三种形式:
- 原码
- 反码
- 补码
限于篇幅,单独列出一节讲该内容,请参考 补充_有符号整数
ASCII表
>(green!)ASCII(American Standard Code for Information Interchange)美国信息交换标准代码),是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。表格中的每一个十进制ASCII编码值,都映射一个字符。ASCII表是最基本的字符编码表,现在常用的编码表大多是兼容ASCII表的。
ASCII表参考
ASCII值 控制字符 ASCII值 控制字符 ASCII值 控制字符 ASCII值 控制字符 0 NUT 32 (space) 64 @ 96 、 1 SOH 33 ! 65 A 97 a 2 STX 34 " 66 B 98 b 3 ETX 35 # 67 C 99 c 4 EOT 36 $ 68 D 100 d 5 ENQ 37 % 69 E 101 e 6 ACK 38 & 70 F 102 f 7 BEL 39 , 71 G 103 g 8 BS 40 ( 72 H 104 h 9 HT 41 ) 73 I 105 i 10 LF 42 * 74 J 106 j 11 VT 43 + 75 K 107 k 12 FF 44 , 76 L 108 l 13 CR 45 - 77 M 109 m 14 SO 46 . 78 N 110 n 15 SI 47 / 79 O 111 o 16 DLE 48 0 80 P 112 p 17 DCI 49 1 81 Q 113 q 18 DC2 50 2 82 R 114 r 19 DC3 51 3 83 S 115 s 20 DC4 52 4 84 T 116 t 21 NAK 53 5 85 U 117 u 22 SYN 54 6 86 V 118 v 23 TB 55 7 87 W 119 w 24 CAN 56 8 88 X 120 x 25 EM 57 9 89 Y 121 y 26 SUB 58 : 90 Z 122 z 27 ESC 59 ; 91 [ 123 { 28 FS 60 < 92 / 124 | 29 GS 61 = 93 ] 125 } 30 RS 62 > 94 ^ 126 ` 31 US 63 ? 95 _ 127 DEL 不要去尝试记忆ASCII码表,没有任何意义,需要用的时候查表即可。
特殊的几个,比如"a"、"A"等可以记忆一下对应编码值。
整数常量的特殊性
>(green!)首先看一个案例(例题)下列代码都能正常执行吗?
整数常量特殊性案例
byte b = 1 + 2; int a = 1; byte b2 = a + 2;
>(green!)同样是用byte类型接收“实际上的1 + 2”的值,为什么一个能够运行,一个不能?
并且我们上面提过:整数的字面值常量默认作为int类型使用,为什么
byte a = 1 + 2这种语句能够运行呢?通过这个现象,我们其实可以发现编译器是很**“聪明”**的:
- 对于整数字面值常量(包括常量的运算)而言,因为它的值一定不会发生变化,而且整型数据值的位数十分容易判断,所以编译器能够自动判断整型常量是否在接收数据类型的范围内。
- 体现在语法上就是:将一个整型字面值(包括常量的运算)赋值给整型时,如果该常量在整型数据类型的取值范围内,是可以赋值成功的。
以上结论举例来说就是:
byte = 100;
short = 30000;
byte = 1 + 120;
都是合法的,反之如果本来就不在取值范围内,强行赋值会编译报错。
例如:
byte = 128;
short = 30000 + 10000;
>(red!)上述说的现象都是针对,整型字面值常量,而:
整型变量是不具有这种特点的,表达式中一旦有变量参与运算,那么结果一定遵循表达式类型提升原则。
小数字面值常量不具有这种特点。因为浮点数本身就是一种近似表示方法,用double和float分别表示0.1完全是两个数,类似下列行为都是不能通过编译的:
// 编译错误
float f = 0.1;
// 编译错误
float f2 = 0.1 + 0.2;
几个容易引起误解的常见名词
>(green!)这里简单聊几个常见,但是容易引起误解的名词:
- 赋值(assignment)
- 声明(declaration)
- 初始化(initialization)
- 定义(definition)
>(red!)第一个要说的就是赋值和初始化这一对名词:
- 初始化:初始化是从无到有的过程,特指变量声明后的第一次赋值过程为初始化。
- 赋值:在计算机编程领域,严格来说(尤其是C/C++),第一次赋值称之为初始化,再次修改取值的过程才称之为赋值。
对于C++而言,由于存在"运算符重载"的概念:
表达式中的" = "可能不仅仅表示一个等号,而完全可能当作一个函数去使用。
所以C++当中必须要严格区分初始化和赋值,初始化时" = "就是等号,赋值就不一定了。
但是对于Java而言,Java不存在"运算符重载",Java的" = "永远就是等号,所以:
在Java中不区分赋值和初始化这两个名词,初始化就等价于赋值!
接下来就是声明和定义这一对名词:
- 严格来说,声明特指声明变量,目的是告诉编译器变量的数据类型和变量名。
- 严格来说,定义指的是声明并且初始化一个变量的过程。
但是:
在实际的应用中,我们不需要特别死扣概念,比如"声明一个方法/定义一个类/定义一个方法"之类的说法都是没问题的。
>(red!)以上,Java变量的相关知识就基本结束了,概念比较多,大家要多复习理解。
















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











