








微软研究院
Dynamic Convolution: Attention over Convolution Kernels
paper:https://arxiv.org/abs/1912.03458
摘要
轻量级权重卷积神经网络(CNN)由于其较低的计算预算限制了CNN的深度(卷积层的数量)和宽度(通道的数量),因此性能下降,导致特征表达能力有限。为了解决这个问题,提出了动态卷积,一种在不增加网络深度或宽度的情况下增加模型复杂性的新设计。动态卷积不是在每层使用单个卷积核,而是基于其注意力机制动态聚合多个平行卷积核,这些注意力机制与输入有关。组装多个核,不仅由于核尺寸小而计算效率高,而且由于这些核通过注意力机制以非线性方式聚合,因此具有更大的特征表达能力。
论文背景
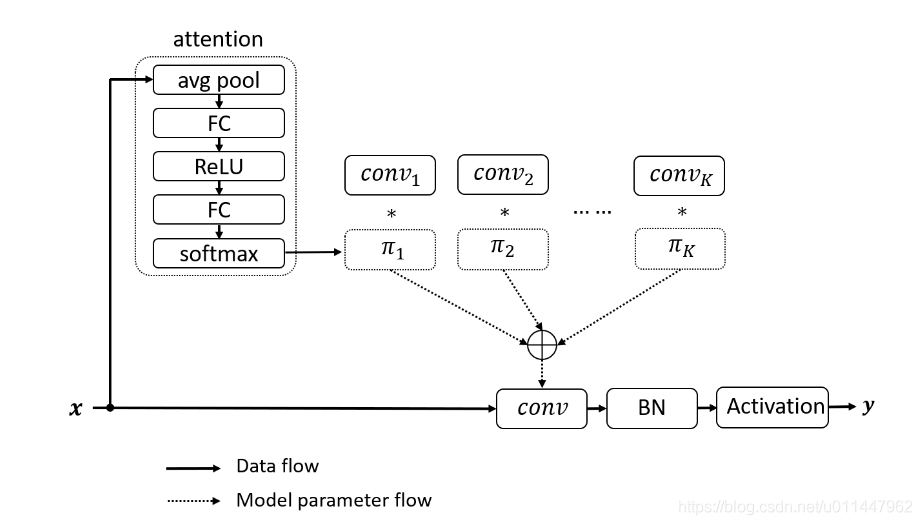
动态卷积的基本思路就是根据输入图像,自适应地调整卷积参数。不同于静态卷积用同一个卷积核对所有的输入图像做相同的操作,而动态卷积会对不同的图像(如汽车、马、花)做出调整,用更适合的卷积参数进行处理。简单地来说,卷积核是输入的函数。
论文主要思想
动态卷积的创新在于将多个卷积核与注意力机制相结合。注意力机制采用avg pool和两层全连接层,模型复杂度低且高效;使用Softmax将权重限制在0与1之间,使模型能够深层次学习特征。动态卷积也不再是一个线型函数,而是通过注意力以非线性方式叠加特征表达能力更强。
keras实现
import numpy as np
import tensorflow as tf
import keras.backend as K
from keras import initializers, regularizers, constraints, activations
from keras.utils import conv_utils
from keras.legacy import interfaces
from keras.layers import Layer, Dense, GlobalAvgPool2D, Conv2D, BatchNormalization
class DyConv2D(Layer):
def __init__(self,
filters,
kernel_size,
num_experts,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
axis=-1,
rank=2,
**kwargs):
super(DyConv2D, self).__init__(**kwargs)
if num_experts < 1:
raise ValueError('A CondConv layer must have at least one expert.')
self.num_experts = num_experts
self.rank = rank
self.axis = axis
self.filters = filters
self.kernel_size = conv_utils.normalize_tuple(kernel_size, rank, 'kernel_size')
self.strides = conv_utils.normalize_tuple(strides, rank, 'strides')
self.padding = conv_utils.normalize_padding(padding)
self.data_format = K.normalize_data_format(data_format)
self.dilation_rate = conv_utils.normalize_tuple(dilation_rate, rank, 'dilation_rate')
self.activation = activations.get(activation)
self.use_bias = use_bias
self.kernel_initializer = initializers.get(kernel_initializer)
self.bias_initializer = initializers.get(bias_initializer)
self.kernel_regularizer = regularizers.get(kernel_regularizer)
self.bias_regularizer = regularizers.get(bias_regularizer)
self.activity_regularizer = regularizers.get(activity_regularizer)
self.kernel_constraint = constraints.get(kernel_constraint)
self.bias_constraint = constraints.get(bias_constraint)
self.condconv_bias = None
self.condconv_kernel = None
self.kernel_shape = None
self.gap = GlobalAvgPool2D(data_format=self.data_format)
self.fc1 = Dense(self.num_experts, activation='relu')
self.fc2 = Dense(self.num_experts, activation='softmax')
self.bn = BatchNormalization(axis=self.axis)
self.out_shape = None
def build(self, input_shape):
input_dim = input_shape[self.axis]
self.kernel_shape = self.kernel_size + (input_dim, self.filters)
self.condconv_kernel = self.add_weight_my(
name='condconv_kernel',
kernel_shape=self.kernel_shape,
num_experts=self.num_experts,
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint,
trainable=True)
if self.use_bias:
bias_shape = (self.filters,)
self.condconv_bias = self.add_weight_my(
name='condconv_bias',
kernel_shape=bias_shape,
num_experts=self.num_experts,
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint,
trainable=True)
self.fc1.build((input_shape[0], input_shape[self.axis]))
self._trainable_weights += self.fc1._trainable_weights
self.fc2.build((input_shape[0], self.num_experts))
self._trainable_weights += self.fc2._trainable_weights
if self.data_format == 'channels_last':
self.bn.build((input_shape[0], input_shape[1], input_shape[2], self.filters))
else:
self.bn.build((input_shape[0], self.filters, input_shape[1], input_shape[2]))
self._trainable_weights += self.bn._trainable_weights
self.built = True
super(DyConv2D, self).build(input_shape)
def batch_conv_bias(self, input_tensor, kernel, bias):
input_tensor = tf.expand_dims(input_tensor, axis=0)
kernel = tf.reshape(kernel, self.kernel_shape)
x = K.conv2d(
input_tensor,
kernel,
strides=self.strides,
padding=self.padding,
data_format=self.data_format,
dilation_rate=self.dilation_rate)
if self.use_bias:
# Compute example-dependent biases
x = K.bias_add(x, bias, data_format=self.data_format)
return x
def call(self, input):
x = self.gap(input)
x = self.fc1(x)
x = self.fc2(x)
# Compute example dependent kernels
kernels = tf.matmul(x, self.condconv_kernel)
biases = tf.matmul(x, self.condconv_bias)
_, h, w, c = input.get_shape().as_list()
outputs = tf.map_fn(lambda i: self.batch_conv_bias(input[i, :, :, :], kernels[i, :], biases[i, :]),
elems=tf.range(tf.shape(x)[0]), dtype=tf.float32)
if self.data_format == 'channels_last':
outputs = tf.reshape(outputs, (-1, h, w, self.filters))
else:
outputs = tf.reshape(outputs, (-1, self.filters, h, w))
outputs = self.bn(outputs)
if self.activation is not None:
outputs = self.activation(outputs)
self.out_shape = outputs.get_shape().as_list()
return outputs
def get_config(self):
config = {
'num_experts': self.num_experts,
'rank': self.rank,
'filters': self.filters,
'kernel_size': self.kernel_size,
'strides': self.strides,
'padding': self.padding,
'data_format': self.data_format,
'dilation_rate': self.dilation_rate,
'activation': activations.serialize(self.activation),
'use_bias': self.use_bias,
'kernel_initializer': initializers.serialize(self.kernel_initializer),
'bias_initializer': initializers.serialize(self.bias_initializer),
'kernel_regularizer': regularizers.serialize(self.kernel_regularizer),
'bias_regularizer': regularizers.serialize(self.bias_regularizer),
'activity_regularizer': regularizers.serialize(self.activity_regularizer),
'kernel_constraint': constraints.serialize(self.kernel_constraint),
'bias_constraint': constraints.serialize(self.bias_constraint)
}
base_config = super(DyConv2D, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def compute_output_shape(self, input_shape):
return tuple(self.out_shape)
@interfaces.legacy_add_weight_support
def add_weight_my(self,
name,
kernel_shape,
num_experts,
dtype=None,
initializer=None,
regularizer=None,
trainable=True,
constraint=None):
"""Adds a weight variable to the layer.
# Arguments
name: String, the name for the weight variable.
shape: The shape tuple of the weight.
dtype: The dtype of the weight.
initializer: An Initializer instance (callable).
regularizer: An optional Regularizer instance.
trainable: A boolean, whether the weight should
be trained via backprop or not (assuming
that the layer itself is also trainable).
constraint: An optional Constraint instance.
# Returns
The created weight variable.
"""
if dtype is None:
dtype = K.floatx()
flattened_kernels = []
for _ in range(num_experts):
kernel = initializer(kernel_shape)
flattened_kernels.append(tf.reshape(kernel, [-1]))
weight = K.variable(tf.stack(flattened_kernels),
dtype=dtype,
name=name,
constraint=constraint)
if regularizer is not None:
self.add_loss(regularizer(weight))
if trainable:
self._trainable_weights.append(weight)
else:
self._non_trainable_weights.append(weight)
return weight声明:本内容来源网络,版权属于原作者,图片来源原论文。如有侵权,联系删除。
创作不易,欢迎大家点赞评论收藏关注!(想看更多最新的文献欢迎关注浏览我的博客)















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









