







一 Windows darknet安装
源码:https://github.com/AlexeyAB/darknet 适用windows系统。
配置与编译darknet VS 工程。(省略)
二 darknet框架训练分类模型
直接调用编译好的 .\build\darknet\x64\darknet.exe,在cmd中采用以下命令:
darknet classifier train vehicle.data classication.cfg1 关键词解析:
darknet:即.\build\darknet\x64\darknet.exe; classifier:表示分类,检测时为“detect”; train:表示训练,测试时为“predict”;
vehicle.data :训练用到的图片列表文件,模型保存路径,分类类别等设置。具体如下:
classes= 2
train = ./train_anno.list
valid = ./val_anno.list
labels = ./vehicle.labels
backup = backup
top = 12 其中vehicle.labels 为罗列分类类别名称的文件,每一行为各类别标签,格式如下:

train_anno.list & val_anno.list为训练数据列表,也可表示为 .txt 后缀文件,格式如下

文件中 标签label 不作单独一列,而是将label包含在图片路径当中,darknet 读取图片时根据路径判别其类别。此处在路径中根据关键词postivelabel、negativelabel判别正负样本。
label 关键词可在图片名称中体现,如:postivelabel_00001.jpg 、negativelabel_00001.jpg;也可根据label建立相应类别名称文件夹,如文件夹postivelabel中存放正样本。
(注意:路径中不要包含多个label关键词,否则出现多个label的错误)
backup 为训练的模型所保存的路径。
3 classification.cfg 定义网络结构文件,如ResNet、DenseNet、VGG等,darknet源码 ./cfg文件夹中包含多种网络结构文件。
三 darknet框架测试分类模型
1. 单张图片测试, 关键词 predict
darknet classifier predict vehicle.data classication.cfg classify.weights Imagepathclassify.weights: step2 训练的模型, Imagepath:待测试的单张图片。
2. 多张图片测试,关键词 valid
darknet classifier valid vehicle.data classication.cfg classify.weights此时测试的数据为vehicle.data 文件中val_anno.list 列表指定的图片。
四 darknet框架训练检测模型
1. 数据预处理
训练时用到的数据相关文件XX .data(vehicle.data),格式如下:
classes= 57
train = ./train.txt
valid = ./val.txt
names = ./Vehicle.names
backup = backup
top = 1其中 train.txt 包含训练图片列表(不包含类别和坐标),格式如下:

代码以vehicle.data为数据入口,从train.txt获取图片路径读取图片,那如何读取标注信息呢?代码自动识别图片路径XXX/JPEGImages/****.jpg,将JPEGImages文件名替换为 labels,得到标注文件的路径 XXX/labels/****.txt(注意:标注txt文件名与jpg文件名相同,仅后缀不同)。每一张图片对应一个txt标注文件。

单张图片标注文件 veh_0001.txt格式如下:
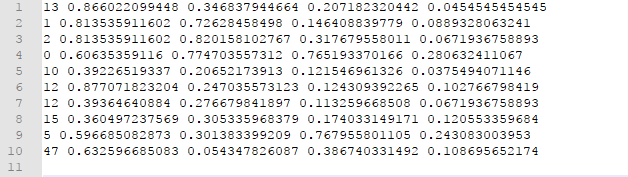
输入图片及标注信息部分处理完成,接下来 vehicle.names文件,文件中每一行为各个类别名称,格式如下:
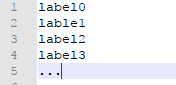
2. 命令行实现模型训练
darknet detector train vehicle.data yolov3_veh.cfg其中,cfg文件根据检测目标种类设置参数,以及网络层数改进。
检测目标类别数 本例calsses = 57,修改yolo层 classes 参数,以及修改yolo层上一个convolutional层 卷积核参数,filters= (4(位置坐标)+1(检测框置信度)+classes) *3

3. 测试
1)单张图片测试,测试结果直接在图片上标注检测框显示,默认保存检测结果图predictions.jpg。
darknet detector test vehicle.data yolov3_veh.cfg yolov3_veh_300000.weights test_0001.jpg其中网络配置文件yolov3_veh.cfg中 ,batch 和 subdivision 都设为1。
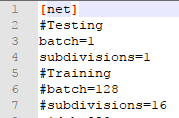
单张图片测试时,输出检测框置信度默认阈值为0.25,也可指定阈值,添加thresh字段,如下:
darknet detector test vehicle.data yolov3_veh.cfg yolov3_veh_300000.weights test_0001.jpg -thresh 0.52) 多张图片测试
darknet detector valid vehicle.data yolov3_veh.cfg yolov3_veh_300000.weights -out detect_result_测试图片列表为 vehicle.data 文件中 valid = ./valid.txt中包含的图片,valid.txt中格式同 train.txt。
阈值设置(如-thresh .5)在源码里的valid下无效,源码里是写死的thresh = .001。对比valid字段对应的validate_detector()和map字段对应的validate_detector_map(),valid没有传递thresh, iou_thresh参数。也可修改源码增加阈值参数的传递。另一种方式是在生成的检测txt中,对其置信度阈值在解析过程中进行过滤。
else if (0 == strcmp(argv[2], "valid")) validate_detector(datacfg, cfg, weights, outfile);
else if (0 == strcmp(argv[2], "map")) validate_detector_map(datacfg, cfg, weights, thresh, iou_thresh, map_points, letter_box, NULL);测试结果保存在默认路径下 results 文件夹中,未指定out字段时,测试结果为 以类别 命名的 txt文件(comp4_det_test_****.txt),共计classes个txt文件。指定out字段时,以其值作为输出txt文件名前缀,即detect_result_****.txt。
各个类别txt文件所包含信息为包含该类别的文件名,概率,检测框坐标,格式如下:

注意:valid批量测试时,默认路径下需有一个results文件夹,不然会报错,darknet退出。
3)计算召回率
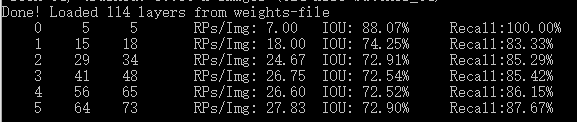
darknet detector recall vehicle.data yolov3_veh.cfg yolov3_veh_300000.weights -thresh .25 源码参见detector.c—>validate_detector_recall( )。测试图片列表根据vehicle.data 中valid=./***.txt或***.list指定。图片gt值按源码中相应的格式文件夹存储,也可将每一张图片对应的gt txt文件与图片放在同一文件夹中。每一张图片对应的同名txt文件gt值格式如下:

源码中默认阈值thresh = .001过小,会有很多置信度较低的检测框,可增加字段-thresh .25 ,即可筛掉置信度低于0.25 的检测框。recall计算结果格式如下:
4)计算mAP
i) 验证集计算mAP,辅助训练
darknet detector train vehicle.data yolov3_veh.cfg -map训练时加入 -map,训练过程中会添加验证集的mAP计算,具体为训练集每训练4个epoch,采用验证集计算一次mAP。生成模型时,会自动保存_best.weights,并根据valid效果自动更新best模型。验证集为vehicle.data中 valid = './valid.txt' ,格式同train图片列表。

ii) 测试集计算mAP
step 1:根据2)valid 测试图片得到检测框。
step 2:根据源码 /scripts/voc_eval_py3.py计算recall、precision、ap。
rec, prec, ap = voc_eval(‘./results/detect_result_{}.txt’, './anno/{}.xml', './eval_data/eval.txt', '3', './eval/cache')其中参数(按顺序)表示:检测结果文件路径(valid检测结果), 标签文件(gt值,默认xml格式), 测试文件路径(图片名列表),待检测的类别名(每一次按某一类别检测),cache文件路径(存储图片、坐标信息)。
iii) 测试集计算mAP (II)
darknet detector map vehicle.data yolov3_veh.cfg yolov3_veh_300000.weights -thresh .25 -iou_thresh .5可以直接通过map命令 计算数据的precision、recall、mAP。同方法i)调用的是同一函数validate_detector_map(最新AlexeyAB/darknet )。
-thresh .25: conf_thresh,检出的bbox置信概率要大于thresh(0.25)才会与gt值计算IOU。调整conf_thresh,可平衡precious和recall值。
-iou_thresh .5:IOU计算出来的最大值的bbox,若其最大值大于预设的iou_thresh,则为正确的检出。
同 i)计算的mAP格式一致,如下:
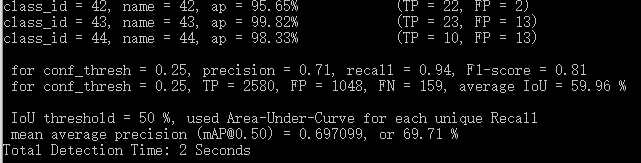
详见源码detector.c 及 validate_detector_map()。

5)计算anchors
采用detector.c 中calc_anchors(),根据数据集计算anchors。
darknet detector calc_anchors vehicle.data -num_of_clusters 9 -width 320 -height 320其中 width 和 height为输入图片的尺寸,yolo v3默认为9组anchors。cfg网络中3个yolo层中的anchor是一样的。
4.微调 fine-tune
darknet detector train vehicle.data yolov3_veh.cfg yolov3_veh_300000.weights -map以训练好的模型的参数初始化,在此基础上微调训练模型。迭代次数是在yolov3_veh_300000.weights的基础上累加的。若改变模型名称,load模型之后,迭代次数会从0开始。学习率和max_batches也要接着微调的模型修改。
若需从0开始迭代训练,可加入-clear字段,只对模型参数进行初始化。命令如下:
darknet detector train vehicle.data yolov3_veh.cfg yolov3_veh_300000.weights -clear -map5.提取模型前N层权重(partial)
darknet.exe partial cfg/yolov4-tiny-custom.cfg yolov4-tiny.weights yolov4-tiny.conv.29 29yolov4-tiny.weights为已训练好的模型,yolov4-tiny.conv.29为输出模型的名字,提取模型前29层卷积层的权重。
再迁移到其他数据集时,以yolov4-tiny.conv.29初始化前29层权重,再进行微调。
darknet.exe detector train data/obj.data cfg/yolov4-tiny-custom.cfg yolov4-tiny.conv.29














 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









