






探秘深度学习:Decoupled Classification Refinement 算法与开源实现
在计算机视觉领域,对象检测是至关重要的一个环节,而更高效、准确的检测模型则成为了研究者们不断追求的目标。今天,我们将深入探讨一项创新性的算法——Decoupled Classification Refinement(简称DCR),及其官方的开源实现。这个强大的工具将带给你全新的对象检测体验,无论是学术研究还是实际应用,它都将助你一臂之力。
项目简介
DCR 是由一组来自伊利诺伊大学厄巴纳-香槟分校的研究人员在ECCV 2018年会议上提出的,并在其后的报告中进一步扩展。该算法旨在提升 Faster RCNN 的分类性能,通过解耦分类和定位的过程来优化结果,从而有效抑制假阳性误检。值得注意的是,它的最新版本(DCR V2)不仅提升了准确性,还实现了速度上的显著提升,且可直接进行端到端训练。
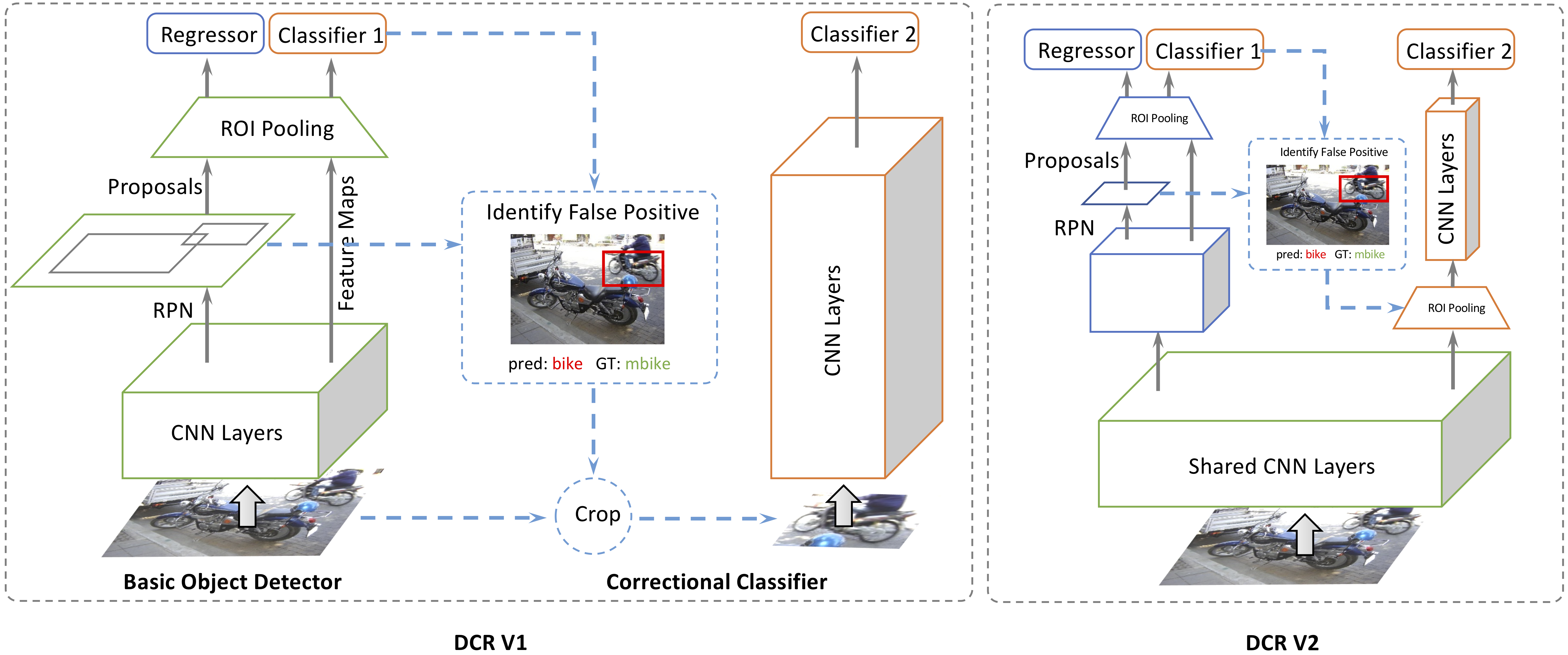 (DCR 高级结构图)
(DCR 高级结构图)
技术分析
DCR 算法的核心是通过两个独立的模块来分别处理分类和定位任务。首先,初步检测器产生候选框,接着通过专门设计的分类细化模块对这些框进行再判断,过滤掉那些低概率的假阳性。这种解耦的方式使得模型能够更专注于识别真正目标,提高了整体的检测精度。
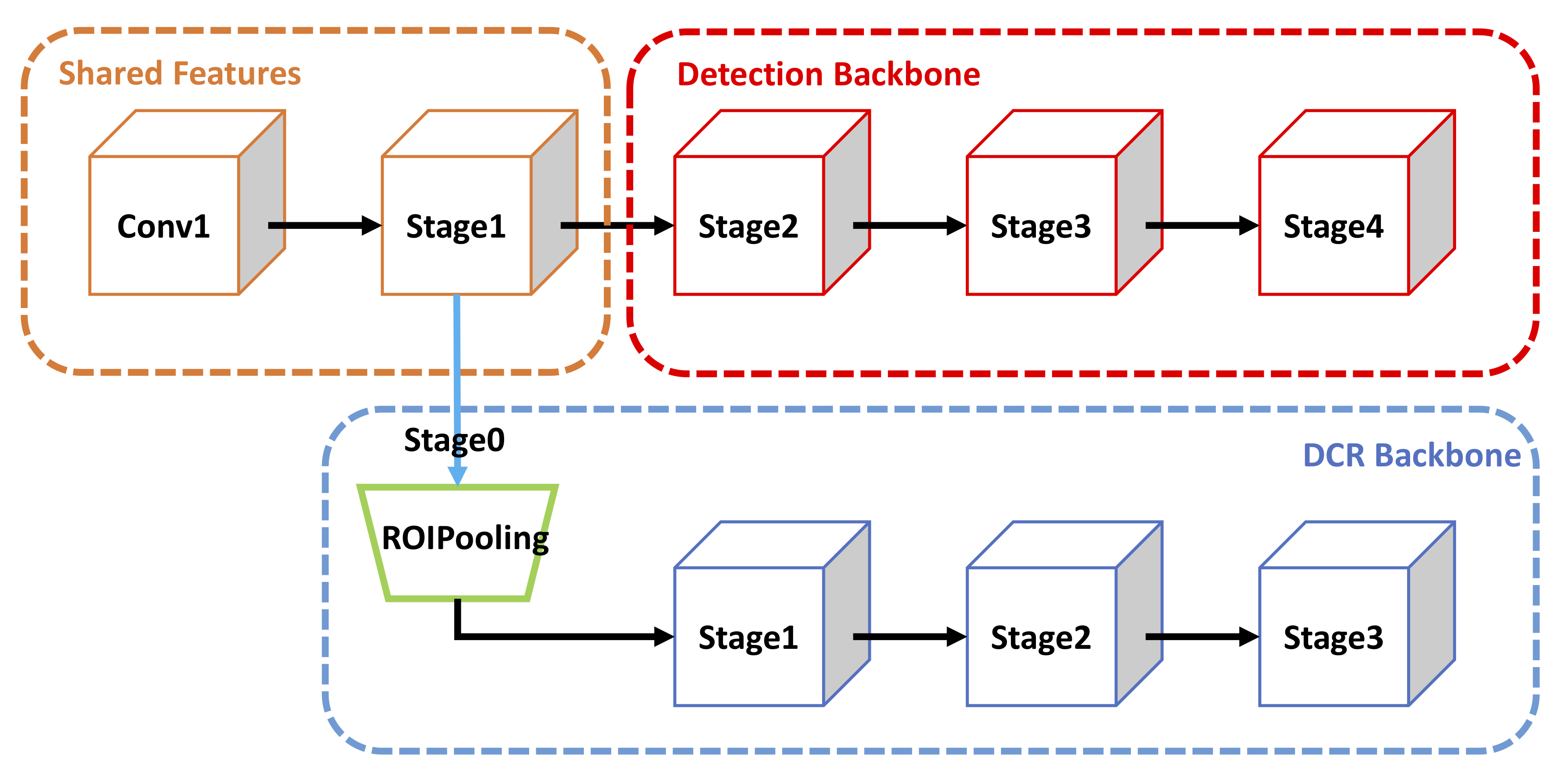 (DCR 细节模块图)
(DCR 细节模块图)
应用场景
DCR 算法适用于广泛的对象检测任务,尤其是在安全监控、自动驾驶、图像理解等对实时性和精确度有高要求的应用中。例如,在智能交通系统中,准确地识别出行人和车辆对于避免事故至关重要;在无人机导航时,能够快速辨别障碍物也是确保飞行安全的关键。
项目特点
- 效率与准确性的平衡:DCR V2 在保持高精度的同时,相比原版 V1 提升了三倍的速度。
- 简化训练流程:与复杂的一阶段训练不同,DCR V2 可以直接进行端到端训练。
- 兼容性好:基于MXNet构建,并在官方1.1.0版本上经过测试,易于集成到现有工作流中。
- 全面支持:提供详细的文档和预训练模型,便于快速上手并进行自己的实验。
注:项目代码已在ECCV 2018论文的基础上进行更新,包含了DCR V1的分支以及最新的DCR V2实现,所有COCO数据集的结果也已公布。
如果你正在寻找一个能大幅提升对象检测性能的解决方案,那么这个项目绝对值得你尝试。立即加入社区,参与 DCV 的探索之旅,共享开源的力量!
















 6587
6587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











