






TensorFlow 2.0 框架下的 TabNet 实现
tf-TabNetA Tensorflow 2.0 implementation of TabNet.项目地址:https://gitcode.com/gh_mirrors/tf/tf-TabNet
项目介绍
TabNet for Tensorflow 2.0 是一个基于最新TensorFlow 2.0版本的实现,它移植了《TabNet: Attentive Interpretable Tabular Learning》这篇论文中的算法,原代码可在Google Research的GitHub仓库中找到。这个项目提供了一个灵活且可解释的框架,用于处理表格数据的学习任务。
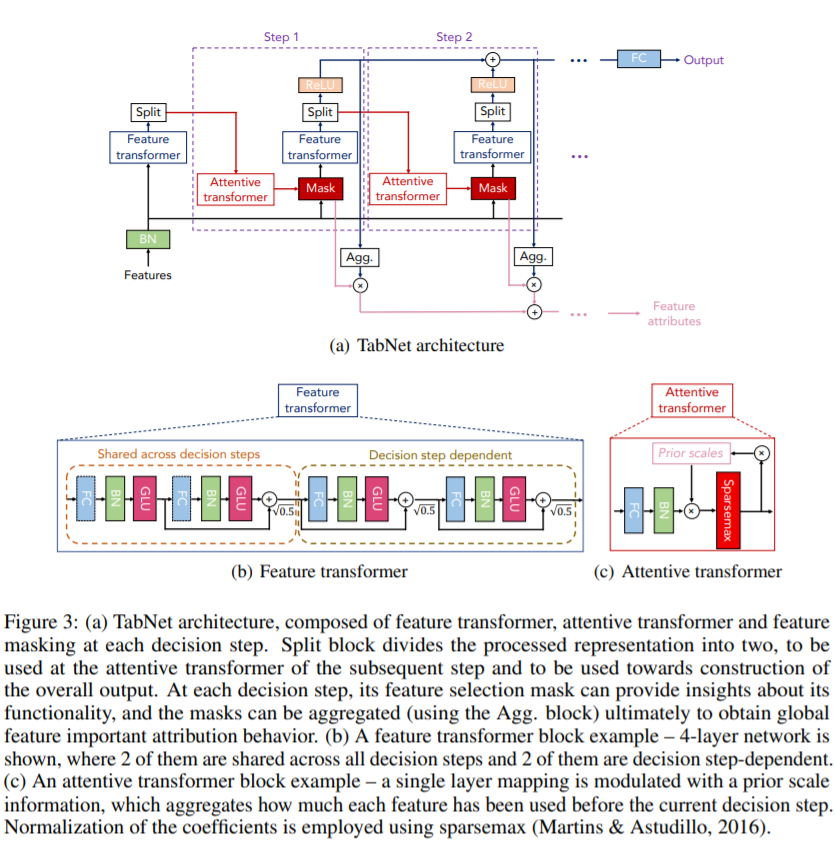
模型架构如图所示,由两阶段块组成,一阶段关注输入特征,另一阶段构造模型输出。
项目技术分析
与原始实现相比,本项目有两个主要区别:
-
提供了选择规范化方法的选项。在原论文中使用的是批量归一化(Batch Normalization),但这个实现也支持组归一化(Group Normalization)。考虑到大批次可能带来的计算成本,组归一化(设置
num_groups为1时相当于实例归一化)是一个合理的选择,其结果不依赖于批次大小。 -
不再强制要求输入必须是表格数据列。通过设置
feature_columns=None和指定数据的输入维度(使用num_features),即使对图像数据(经过展平为长向量)也能得到半可解释的结果。
安装与使用
安装最新的发布分支,可以执行以下命令:
$ pip install --upgrade tabnet
若要安装主分支,使用:
$ pip install git+https://github.com/titu1994/tf-TabNet.git
CPU或GPU版本的安装可以选择[cpu]或[gpu]:
$ pip install tabnet[cpu]
$ pip install tabnet[gpu]
导入tabnet.py文件,你可以创建TabNet基础块,或者创建具有适当头部的TabNetClassifier和TabNetRegressor模型,以适应不同的任务需求。
堆叠式 TabNets
通过将多个TabNets堆叠在一起,可以提高模型容量,虽然会牺牲一定的可解释性。这可以通过StackedTabNetClassifier来实现。
特性可视化
TabNet模型提供了获取特征选择掩码的方法,这对于理解模型决策过程非常有用。这些掩码可以在训练过程中通过Eager模式进行可视化,并使用TensorBoard展示。
系统要求
- TensorFlow 2.0+
- TensorFlow-datasets(仅在评估
train_iris.py时需要)
应用场景
- 金融领域:用于信用评分、欺诈检测等,通过解释性学习来理解影响决策的因素。
- 医疗保健:预测疾病发展或治疗效果,揭示重要的患者特征。
- 市场营销:客户细分、营销活动效果预测,理解哪些因素影响顾客行为。
项目特点
- 兼容TensorFlow 2.0:利用TF 2.0的高级功能,优化性能。
- 灵活的归一化策略:可以根据需要选择批归一化或组归一化。
- 不受限的输入类型:除表格数据外,还可应用于其他形式的数据。
- 可解释性:提供特征选择掩码,便于理解模型决策。
- 易用性:提供预定义的分类和回归模型,简单导入即可使用。
综上所述,TabNet for Tensorflow 2.0是一个强大的工具,适用于各种表格数据的机器学习任务,并提供了可解释性这一重要优势。无论是初学者还是经验丰富的开发者,都值得尝试这个项目,将其纳入你的工具箱。
tf-TabNetA Tensorflow 2.0 implementation of TabNet.项目地址:https://gitcode.com/gh_mirrors/tf/tf-TabNet


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











