






概述:
为了对股票市场价格的波动进行预测,根据所提供的原始数据,本文做了以下工作:
首先在数据预处理部分,在对数据进行描述性统计后,针对模型的缺失值采取了0值填补的方法;同时针对数据严重右偏的统计分布特点采用了对数化的方式进行处理。
而在特征工程部分,主要是按照美国股市的交易时间等特点,额外构建了三个时段加总波动率以及一个波动方向加总项这四个特征。模型建立与预测部分则是利用lightgbm决策树模型和tabnet神经网络模型双模型模型进行模型融合预测尝试获得超越一般单模型的预测效果,而最终得到的双模型结果平均绝对误差为3.87。
最后,本文指出了未来继续优化的改进方向。
数据描述性统计
首先在进行描述性统计之前,使用python检测导入数据中的空值,并且将这些空值替换成数字0.
表1 字段含义解释
| 字段 | 含义 |
| ID | ID唯一取值 |
| date | 日期 |
| product_id | 股票的标识号 |
| volatility1 ~ volatility54 | 波动率,举例:volatility2到volatility1间隔5分钟内的波动率 |
| return1 ~ return54 | 波动方向,举例:return2到return1间隔5分钟内的波动方向 |
| target | 预测volatility字段5分钟后的2小时内的波动率 |
根据上表1可知:ID字段为股票的代号,通过python程序计数可以发现,共有318只股票,其中ID是每只股票的唯一代码;Date字段为交易日期,使用python程序随机查询两只股票后发现,每只股票前后交易日期并不连续,前后间隔从1天到5天均有,具体见下图1。
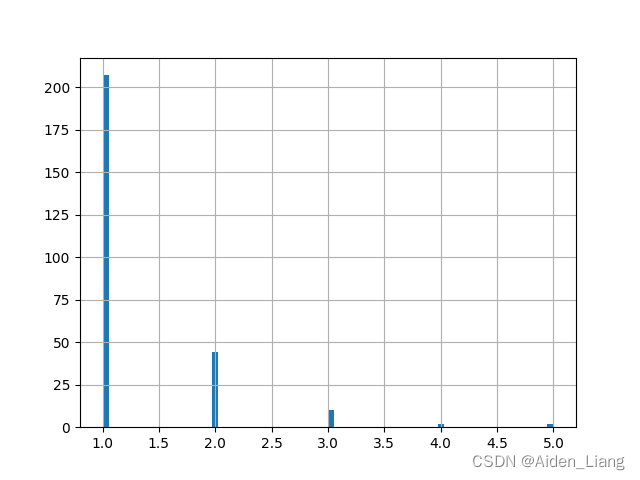
图1 日期间隔图
综上所述,每一行数据就是对于某一只股票的某一个交易日期的波动率数据和波动方向数据。同时由于每一行行数据中包含54个波动率数据以及波动方向数据,每个数据时段是5分钟,可知每一行已知波动率 总时长为4.5小时。又因为要对当天接下来的2个小时的波动率进行预测,可知,每天股票交易总时长为6.5小时,该数据来源于美股市场。
最后对于target字段,进行简单的描述性统计可以发现如下信息:平均值为19.55,标准差为17.64,最小值为0.016,最大值为511.87。同时,通过下方图2箱型图可以看出,target字段整体呈现出明显的右偏,以及存在大量的异常大值,因此通过取对数的方式对target字段进行转换。
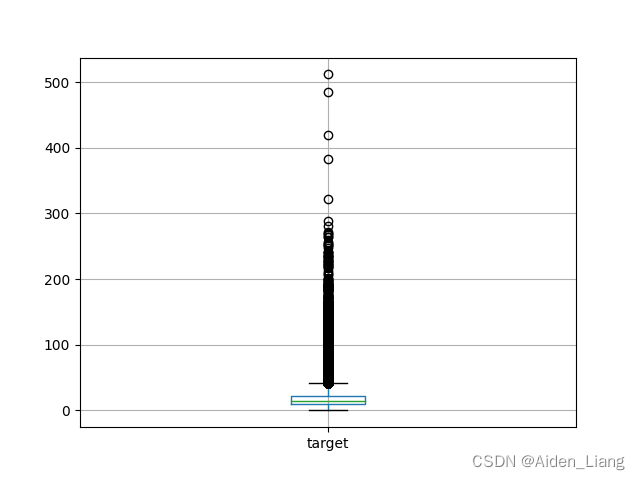
图2 target字段箱型图
总结:
1. 训练数据给出了318只股票过去若干天中每隔5分钟统计一次的波动率以及波动方向数据。
2. 但每只股票数据包含的天数不一样,同时前后两天也不一定是连续的。
3. 需要基于这些数据构建一个预测模型,用于预测某只股票未来两小时的波动率,实际上是根据一天中前4个半小时的波动率以及波动方向数据来预测后两个小时的股票波动率。
特征工程
在特征工程部分主要的思路是保留了股票ID以及原有数据特征的同时构建了四个新特征:
1.开盘后半小时内的汇总波动率half_hour:将volatility1~ volatility6相加,并将加总值取对数。由于开盘后半小时内的波动率最大并且可能反映全天的交易情绪,因此单独提出 出来。
2.开盘后0.5小时~2.5小时的汇总波动率fir_hour:将volatility7~ volatility30相加,并将加总值取对数。和sec_hour字段一起构成两个连续的两小时波动率,有利于预测下一个 两小时波动率。
3.开盘后2.5小时~4.5小时的汇总波动率sec_hour:将volatility31~ volatility54相加,并将加总值取对数。和fir_hour字段一起构成两个连续的两小时波动率,有利于预测下一个两小时波动率。并且和所要预测的目标波动率在时间上是相邻的。
4.波动方向加总值sum_returns:数值绝对值越大说明当天该股涨跌状态越极端,可以反映一定的波动率信息。
同时,构造完指标后可以发现前三个汇总波动率指标都和处理前的target指标营业呈现出右偏以及异常值多的特点,因此同时将上述几个指标进一步进行对数化处理。
模型建立:
我首选的机器模型是lightgbm这个决策树模型。在机器学习算法应用中,对于采用表格数据的任务,基本都是决策树模型的主场,像XGBoost和LightGBM这类提升(Boosting)树模型已经成为了现在数据挖掘比赛中的标配。树模型优点包括:模型的决策流形(decision manifolds)可看成超平面边界的;跟踪决策节点,追溯推断过程,可解释性较好;训练速度快。
但是神经网络在许多领域被认为是最先进的,并且在具有最少特征工程的大型数据集上表现特别好。因此为了提高模型适应性和泛化能力,我也使用了tabnet神经网络模型,这一专门针对表格型数据设计的网络结构模型。并且在最终结果中将两个模型的输出结果融合为一个输出结果。
LightGBM
在LightGBM的具体部署中我使用的是KFold交叉验证框架——分5次,每次将训练集中各不相同的占20%的数据抽出当做训练的验证集,剩余的数据作为新的训练集来训练并验证模型。如此一来,就可以训练出5个LightGBM子模型,并在预测中将5个子模型的结果进行加权平均。
而在具体模型超参数设计方面,比如学习率等等,则是迁移网上开源的该比赛官方公布的baseline的参数,具体见附录代码
Tabnet
在Tabnet模型的部署过程中,由于神经网络模型训练时间较长,采取的是单次训练法,取全部训练数据的10%作为验证集其余作为训练集进行训练。具体部署过程见附录代码部分。
测试结果
首先,由于原数据的测试集的结果未知,无法比对,所以从训练集中抽取5%的数据作为模型建立过程中的训练用测试集(注意与出题方所给的测试集相区分,由于老师没有出题方测试集的目标结果,本次报告中不涉及对出题方测试集)。
在结果输出和评估部分,我选择的指标是mean_absolute_error(平均绝对误差),计算方式简单,就是预测值和实际值的差异绝对值的平均值。同时为了使得评估指标更具解释力,在计算指标前,我将模型拟合所得结果和实际值分别进行指数化还原,抵消先前对数化造成的影响后再计算mean_absolute_error。
最终发现,对于从训练集划分出来的测试集数据,lightgbm单模型的预测平均绝对误差为3.73,tabnet单模型的预测平均绝对误差为13.99. 最终,由于lightgbm模型效果更优,在最后双模型结果融合中选择将0.7的权重分配给lightbgm模型结果,0.3的权重分配给tabnet模型的结果,最后合成一个结果输出(部分预测结果展示如下表2)。最终输出的双模型结果平均绝对误差为3.87。
可见,lightgbm模型的效果优于tabnet模型。相对于target字段19.55的平均值,17.64的标准差而言,lightgbm模型以及双模型结果尚属优秀。
表2 部分预测结果
| ID | target_pred | target |
| 35 | 181.9126818 | 140.710194 |
| 37 | 13.24487802 | 13.80636922 |
| 60 | 114.2571988 | 140.0771951 |
| 75 | 15.24946887 | 15.19724398 |
| 91 | 14.69331675 | 9.020787189 |
| 117 | 23.22847665 | 33.84984054 |
| 214 | 27.03769022 | 21.17896818 |
| 236 | 26.45727809 | 36.10503996 |
| 256 | 12.7634072 | 17.24889881 |
| 261 | 10.75908539 | 12.59003105 |
| 262 | 10.22184776 | 11.39775302 |
| 282 | 9.188189191 | 13.47338435 |
| 305 | 14.77469924 | 14.00747805 |
| 309 | 14.99987218 | 11.53480375 |
| 321 | 30.13646635 | 28.74701205 |
| 327 | 31.87909791 | 29.94713135 |
| 335 | 12.9058705 | 15.32482955 |
| 338 | 8.01319919 | 4.612601128 |
| 346 | 16.66359631 | 15.34352299 |
未来改进方向
本次预测分析尚有许多不足之处,未来可以在以下方面进行持续改进:
- 特征工程部分构建更多特征,如可以尝试通过波动率变量差分的方式来构造变量以反映股票价格波动率在一天中随着时间推移而逐渐下降的趋势。
- 特征工程中加入特征筛选和合并,总特征数量超过100个,且不同特征之间可以预见会存在较强的相关性(如前后两个5分钟时段的波动率),如果根据特征重要性进行特征筛选或者采用PCA等方法进行数据降维,或许可以进一步提升预测效果。
- 模型的超参数搜索,由于训练时间等限制,本次模型训练过程中并没有加入网格搜索等超参数搜索方法,如果加入调参步骤,可能可以对模型预测结果进一步优化。
# -*- coding: utf-8 -*-
"""
Created on Sat Sep 10 17:31:32 2022
@author: liangshanliao
"""
# 导入相关工具包
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn.model_selection import KFold
from pytorch_tabnet.tab_model import TabNetRegressor
import lightgbm as lgb
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#%%导入数据及描述性统计
#导入数据
'''
不导入test是因为本次作业老师无法获取test对应的目标字段,因此只是用train来重建一个test集
'''
train = pd.read_csv(r"D:\桌面\量化投资大作业\CFM对金融市场的波动性预测\train_new.csv")
#test = pd.read_csv(r'D:\桌面\量化投资大作业\CFM对金融市场的波动性预测\test_new.csv')
# 将train数据集拆分为训练集和测试集
'''
如果是使用出题方所给的测试集则不需要这一步
'''
test = train.sample(frac=0.05)
train=train[~train.index.isin(test.index)]
test=test.reset_index(drop=True)
train=train.reset_index(drop=True)
#空值处理,统一填充为0
#print(pd.isnull(train.values).any())
train.fillna(value=0,inplace=True)
test.fillna(value=0,inplace=True)
#异常值处理
train["target"] = train["target"].apply(np.log)
#print(pd.isnull(train.values).any())
#统计股票数量为318支股票
#print("product_id:",len(train["product_id"].unique()))
#由以下代码可知,每个股票id的交易数据中的日数各不相同,某些股票数据中前后天数并不连续
temp = train.groupby(['product_id'])['date'].count().reset_index(drop = False)
temp.columns = ['product_id', 'lengs']
#print(temp.head(10))
df_sample20 = train.query("product_id==20")
#print("max_time_id: {}".format(df_sample20['date'].max()))
#print("count_time_id: {}".format(df_sample20['date'].nunique()))
#df_sample20['date'].diff().hist(bins=10)
#%%特征工程
#%%%特征构建部分
#1.股票ID(product_id)作为特征之一加到特征中去
#2.原有的特征数据作为特征
#3.添加return数据的加总项作为特征
return_features = [f'return{i}' for i in range(1, 55)]
train["sum_returns"]=0
test["sum_returns"]=0
for f1 in tqdm(return_features):
train['sum_returns'] += train[f1]
test['sum_returns'] += test[f1]
#4.添加0~2小时、2~4小时、4~4.5小时的3个时段波动率之和作为特征
volatility_features_1 = [f'volatility{i}' for i in range(7, 31)]
volatility_features_2 = [f'volatility{i}' for i in range(31, 54)]
volatility_features_3 = [f'volatility{i}' for i in range(1, 7)]
train['fir_hour'] = train[volatility_features_1].apply(lambda x: x.sum(), axis=1) # 按行求和,添加为新列
train["fir_hour"] = train["fir_hour"].apply(np.log)
train['sec_hour'] = train[volatility_features_2].apply(lambda x: x.sum(), axis=1) # 按行求和,添加为新列
train["sec_hour"] = train["sec_hour"].apply(np.log)
train['half_hour'] = train[volatility_features_3].apply(lambda x: x.sum(), axis=1) # 按行求和,添加为新列
train["half_hour"] = train["half_hour"].apply(np.log)
test['fir_hour'] = test[volatility_features_1].apply(lambda x: x.sum(), axis=1) # 按行求和,添加为新列
test["fir_hour"] = test["fir_hour"].apply(np.log)
test['sec_hour'] = test[volatility_features_2].apply(lambda x: x.sum(), axis=1) # 按行求和,添加为新列
test["sec_hour"] = test["sec_hour"].apply(np.log)
test['half_hour'] = test[volatility_features_3].apply(lambda x: x.sum(), axis=1) # 按行求和,添加为新列
test["half_hour"] = test["half_hour"].apply(np.log)
train.fillna(value=0,inplace=True)
test.fillna(value=0,inplace=True)
#%%建模部分(融合lgbm树模型和神经网络模型)
#建立预测效果评估函数
def mean_absolute_error(y_true, y_pred):
"""
Mean Absolute Error, .
"""
y_true=np.asarray(y_true)
y_pred=np.asarray(y_pred)
return np.mean(np.abs(y_true - y_pred))
#%%%lightgbm树模型+KFold验证法
#提取特征值数据
features = [f for f in train.columns if f not in ['ID','Date','target']]
#记录预测结果
preds = np.zeros(test.shape[0])
# out-of-fold result
oof=np.zeros(train.shape[0])
#划分为特征集和目标集
train_X = train[features]
train_Y = train['target']
val_label=[]
#尝试5折验证法
folds = KFold(n_splits=5, shuffle=True, random_state=2022)
for fold_, (train_index, test_index) in enumerate(folds.split(train_X, train_Y)):
train_x, test_x, train_y, test_y = train_X.iloc[train_index], train_X.iloc[test_index], train_Y.iloc[train_index], train_Y.iloc[test_index]
#每一fold的测试集和验证集数据
trn_data = lgb.Dataset(train_x, train_y)
val_data = lgb.Dataset(test_x, test_y)
#最大迭代次数
num_round=5000
#从网上迁移过来的训练过的参数
params = {'learning_rate': 0.12,
'boosting_type': 'gbdt',
'objective': 'regression_l1',
'metric': 'mae',
'min_child_samples': 46,
'min_child_weight': 0.01,
'feature_fraction': 0.7,
'bagging_fraction': 0.7,
'bagging_freq': 2,
'num_leaves': 16,
'max_depth': 5,
'n_jobs': -1,
'seed': 2019,
'verbosity': -1,
}
clf1 = lgb.train(params,
trn_data,
num_round,
valid_sets = [trn_data, val_data],
verbose_eval = 50,
early_stopping_rounds = 50,
)
#对Kfold验证法下的验证集进行预测并与已知结果对比
val_train=clf1.predict(test_x, num_iteration=clf1.best_iteration)
oof[test_index]=val_train
scores = mean_absolute_error(oof[test_index], test_y)
print('===scores===', scores)
#利用训练出来的模型对测试集进行预测,以kfold训练出来的5个模型的预测结果平均作为最终结果
val_pred = clf1.predict(test[features], num_iteration=clf1.best_iteration)
#这里除5是因为5折验证法
preds += val_pred/5
#计算kflod验证法下,训练集集预测结果和实际结果对比成绩
result_scores = mean_absolute_error(np.exp(oof), np.exp(train_Y))
print('===result_scores===', result_scores)
#===result_scores=== 3.7563330549393688
#%%%神经网络Tabnet模型
from sklearn import model_selection
# 将数据集拆分为训练集和测试集
train_X=train_X.to_numpy()
train_Y=train_Y.to_numpy().reshape(-1, 1)
train_X[np.isinf(train_X)] = 0
train_Y[np.isinf(train_Y)] = 0
X_train, X_test, y_train, y_test = model_selection.train_test_split(train_X, train_Y, test_size = 0.1, random_state = 1235)
clf2 = TabNetRegressor()
clf2.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
max_epochs=1000,
)
test_X=test[features].to_numpy()
test_X[np.isnan(test_X)] = 0
test_X[np.isinf(test_X)] = 0
tabnet_preds = clf2.predict(test_X)
#%%结果输出
#lightbgm模型和tabnet神经网络模型结果输出
#同时这里指数化还原结果输出
test['target1'] = 0.7*np.exp(preds)
test['target2'] = 0.3*np.exp(tabnet_preds)
test['target_pred']=test['target1']+test['target2']
#平均绝对值偏移
result_scores_lgb=mean_absolute_error(np.exp(preds),test['target'])
result_scores_tn=mean_absolute_error(np.exp(tabnet_preds),test['target'])
result_scores_d=mean_absolute_error(test['target_pred'],test['target'])
print('===lgb_result_scores===', result_scores_lgb)
print('===tabnet_result_scores===', result_scores_tn)
print('===final_result_scores===', result_scores_d)
test[['ID', 'target_pred','target']].to_csv('./final_result.csv', index = False)

















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









