







从学了C语言之后,一直习惯于C/C++任意的强制转化,但是C语言的强制转化却总是带来意想不到的后果,在这里,我将从int,float,double的本质上讲解这些可能出现的问题以及解决办法,在下面你将看到:
OK,现在好戏开始。
- int
- unsigned int: unsigned int所进行的是模数计算,就是正常的二进制相加减,计算方法和十进制加减并无区别,但是unsigned int有着正溢出和负溢出的问题,如下图计算所示:
这一点是我们需要注意的地方。 - int:int所使用的是32位补码,关于补码的运算,在这里就不赘述了,大部分计算机导论的书籍都有相关说明。
- 接下来,要说的就是unsigned int和int的相互转化,请看如下代码:
- unsigned int: unsigned int所进行的是模数计算,就是正常的二进制相加减,计算方法和十进制加减并无区别,但是unsigned int有着正溢出和负溢出的问题,如下图计算所示:

/* WARNING: This is buggy code */
float sum_elements(float a[],unsigned length)
{
int i;
float result=0;
for(i=0;i<=length-1;i++)
{
result+=a[i];
return result;
}
}这段代码计算一个数组所有元素之和,看起来似乎没什么问题。但是当你的数组为空的时候,length输入0之后,却返回一个存储器错误,这是为什么呢?请看上文关于unsigned int计算的式子,length是unsigned int 类型,进行的是模数运算,只代表正数,如果出先了0000000(这里有32个0)-00000..01(31个0,1个1)=111…11111(32个1)=UMAX。一个本该为-1的数变成了无符号数最大值,当然,当i取任何不为0的数都发生了非法访问,自然出现了存储器错误,并且任何数都小于UMAX,就会出现判别式永远为真,出现死循环。解决这个问题的方法有两种,做一个判断,当传入length<1,直接返回0.或者,在之前就将length转化为int。
- 浮点数(float,double的理解)
- 什么是定点数,定点数有什么缺点:
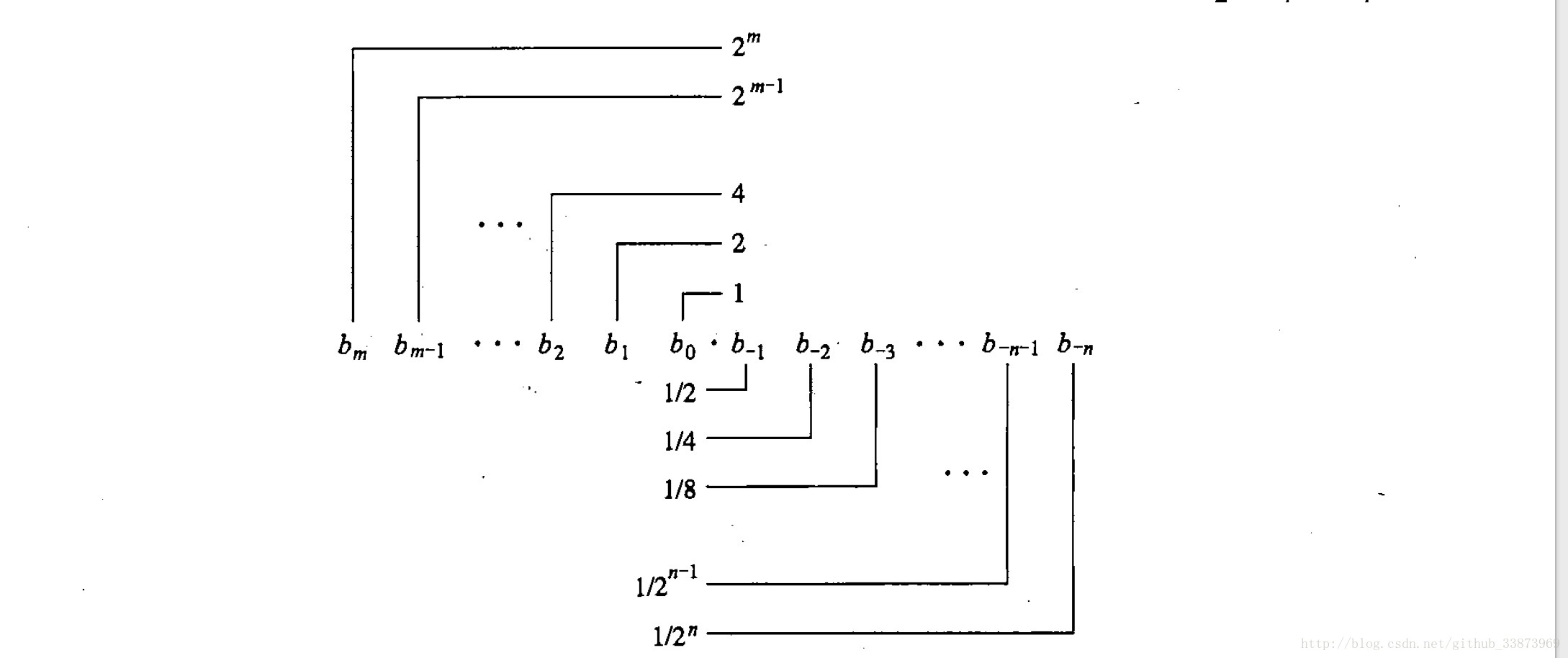
我们用二进制数表示整数,我们也想用二进制表示小数。自然而然,我们会像十进制的小数一样,在二进制上加上小数点,例如1.0011111 2 ,
但是这样的二进制会出现什么样的问题呢?请看下面的二进制小数
- 什么是定点数,定点数有什么缺点:
| 整数部分 | 小数部分 | 二进制(Representation) |
|---|---|---|
| 5 | 3/4 | 101.11 2 |
| 2 | 7/8 | 10.111 2 |
| 1 | 7/16 | 1.0111 2 |
大家观察一下,二进制小数有什么特点。
只能准确的表示
x/2k
的小数,而不为
x/2k
只能近似,请看下面的小数
| 十进制小数 | 二进制(Representation) |
|---|---|
| 1/3 | 0.01010101[01]… 2 |
| 1/5 | 0.001100110011[0011]… 2 |
| 1/10 | 0.0001100110011[0011]… 2 |
[0011]表示无限循环小数
为什么会出现这样的计算结果,请看下面1/3 和 1/5是如何计算的。
1/5就复杂了点
可见,当小数不能表示为
那么定点数有什么缺点呢?很重要的一个缺点是定点数无法标准化,你无法给出一个标准的定点数计算方式,小数点该放哪里,不同小数点的位置又给计算定点数增加了难度。同时,定点数表示的范围太小了,一个32位的定点数,假设没有整数位,全是小数位。那么所能表示的小数的最小值为:
2 −32 ,而32位浮点数光指数位最小都可以表示到2 −126 ,定点数从标准化和范围大小都比较差,但好处就是定点数所能表示的数字精确度高。
- 这个时候,专家组为了统一二进制小数,浮点数来表示二进制小数的方式就出现了,那么浮点数是什么呢?下面用一个最简单的式子表达出来:
s:表示符号位,只用一个bit表示
M:表示尾数(significand)(frac)也表示小数位,即能准确表示小数位
E:表示指数位,简单来说就是位数的多大。
那么,我们来看一下,我们最常用的float,double是怎么组成的:

明显的看出,float有8位指数位,23位尾数位。指数最大可表示的范围为-127~126,但浮点数的指数计算有一点技巧要用到:E-Bias。
下面是浮点数所表示的一个范围:
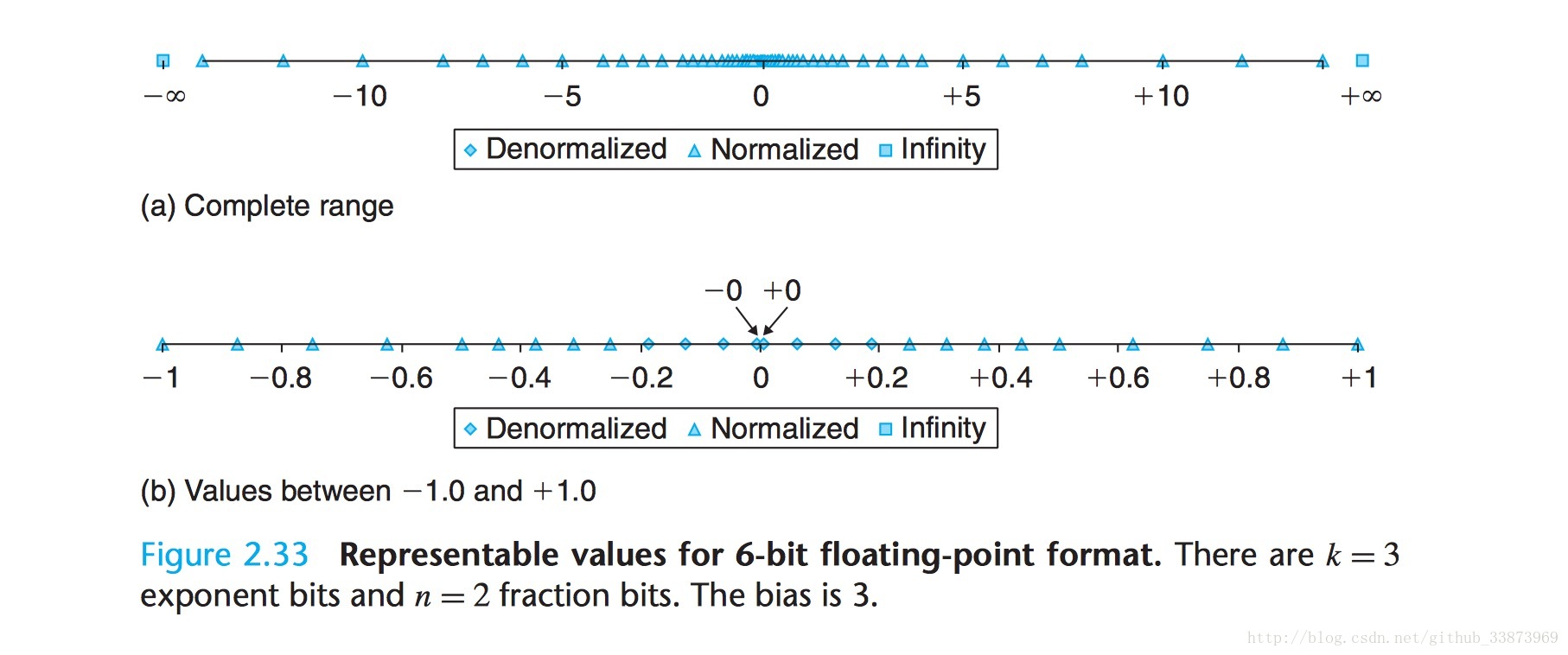
大家可以清楚的看到浮点数随着大小的不同被分成好几种,接近0的被称为Denormalized,比较大的数字被分为Infinity,接下来介绍这几种数字的特征:
Normalized:这是最常见的一种情况,指数位EXP不为0(不小),EXP不全为1(不大)。此时,阶码(这个2
E
)E=e-Bias,e即指数位上计算得到的值,Bias=2
k−1
-1,k表示指数位的位数,float单精度即32位浮点为127,double双精度为1023。故float单精度的E范围为-126~127,对于双精度为-1022~+1023。
而对于尾数位,即小数位:相当于得到的数为1.M(M表示尾数位)
下面就到了重点了,这也是浮点数经常被大家忽略的地方。
Denormalized:当阶数E全为0的时候,被称为Denormalized,那么它的指数位就变成了E=1-Bias, 之所以不用-Bias,而用1-Bias,是为了实现与Normalized的数实现完美过渡,具体如何过渡的图片会在下面给出。
而Denormalized的尾数有什么特点呢:如果frac为0,说明该数为0,但是不知道是+0还是-0。因为,前面的符号位未知。如果frac不为0的话,那么实际的数字表示为0.M(M为尾数位),记住,此时前面是0.,因为只有是0.最终才能接近0
Infinity:当指数位全为1,frac尾数位为0的时候表示Infinity(可以表示无穷大),分别取符号位为1或者0,表示正无穷或负无穷。可以满足Infinity相乘或除,表示溢出。
NaN:not a number,即指数位全为1,frac尾数位不全为0.
一张图可以表示Normailized,Denormalized,Infinity,NaN
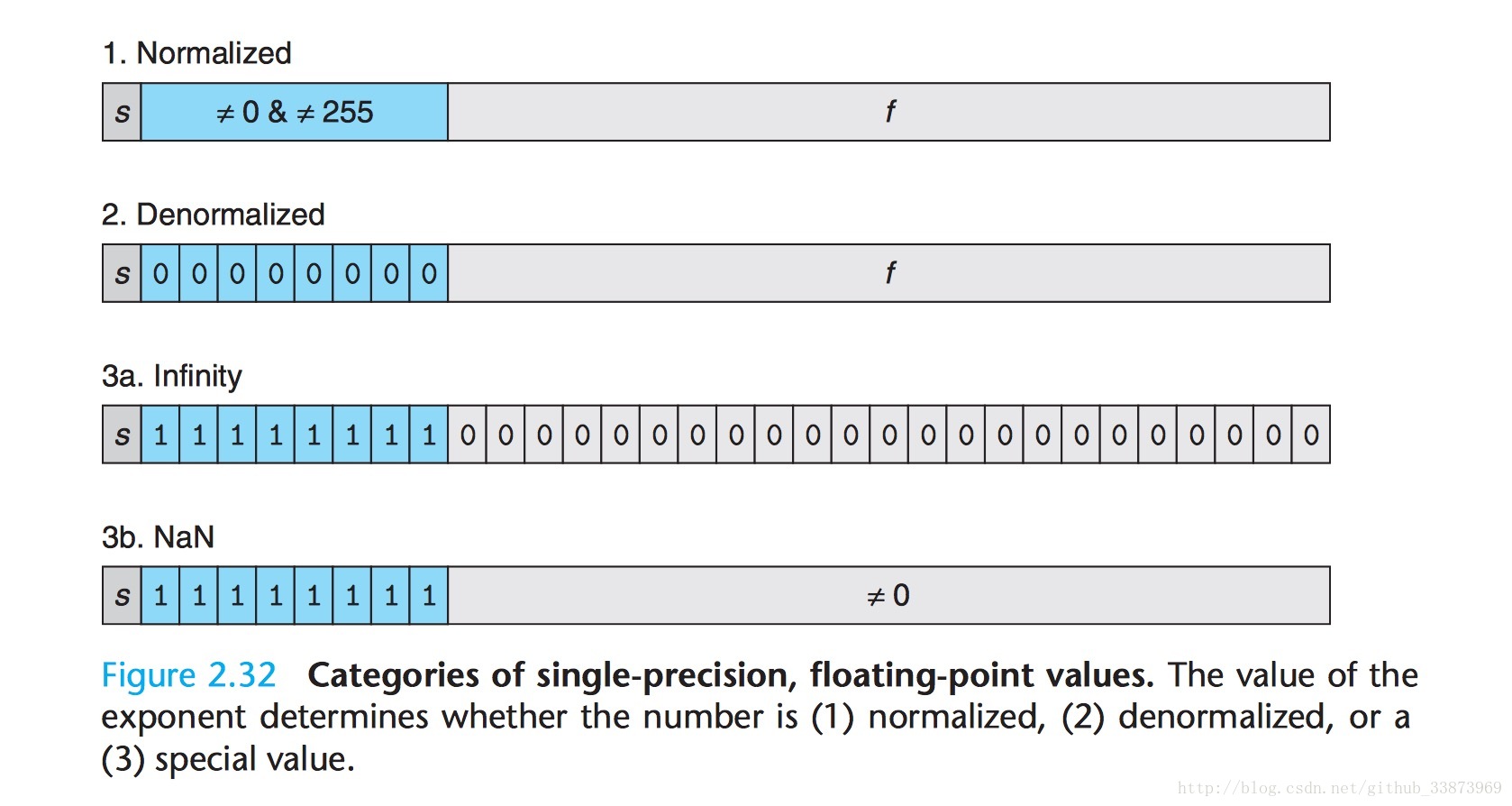
这张图说明,从Denormalized到NaN有什么变化:
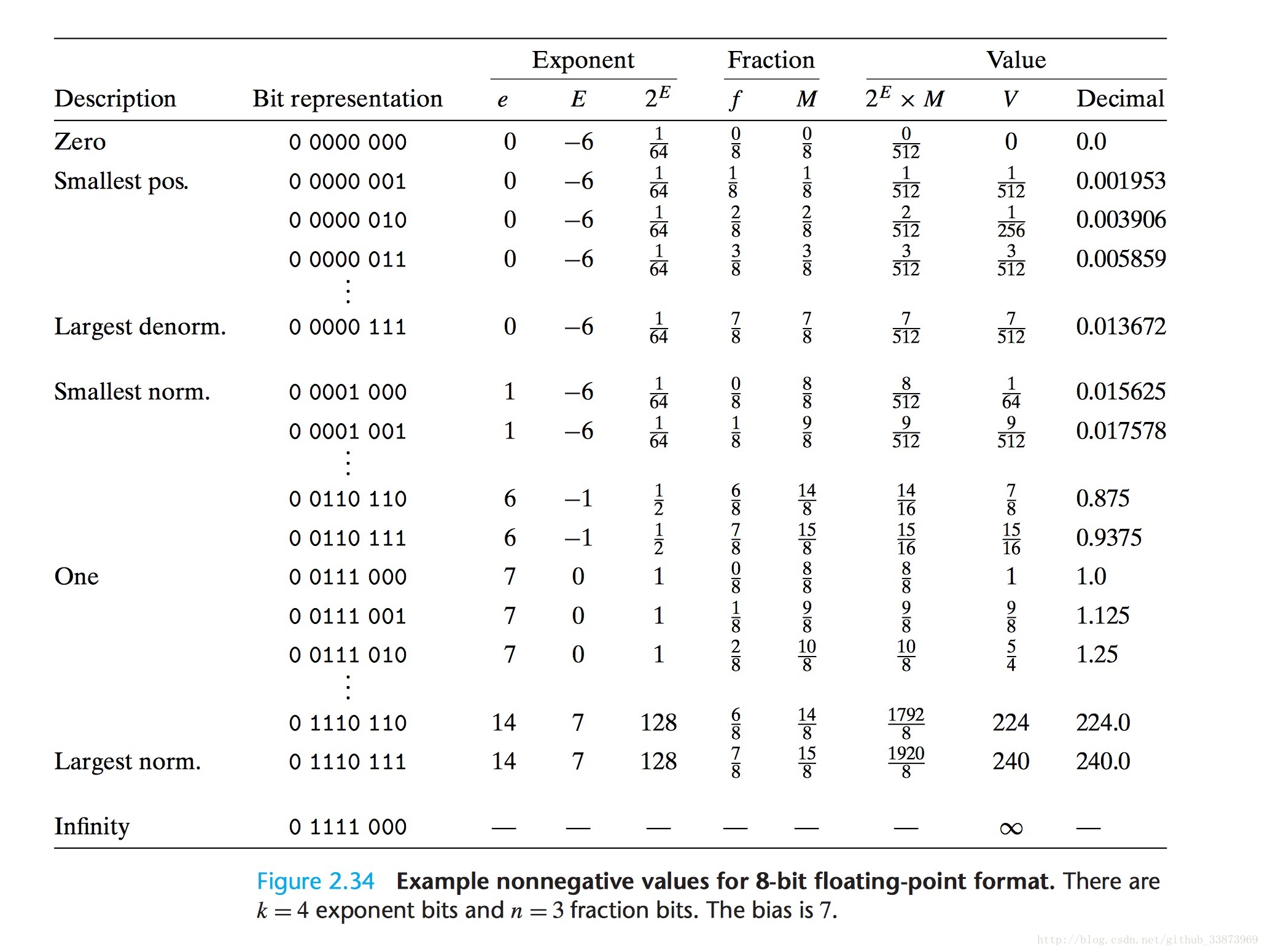
可以看到在Denormalize使用E=1-Bias,并且M前取0,实现了从Largest denorm到Smallest norm完美过渡。
- 浮点数的rounding
上文提到无论是定点数还是浮点数都只能表示有限的位数,那么舍入就显的是一个很重要的环节了。浮点数采取的舍入方法,小于一半的向下舍入,大于一半的向上舍入,在中间的,close to even(向偶数舍入),下面是几个二进制例子:
Format A:
There are k=3 exponent bits. The exponent bias is 3.
There are n=4 fraction bits.
Format B:
There are k=4 exponent bits. The exponent bias is 7.
There are n=3 fraction bits.
要求给出A,将A转化为B
前一半为A,后一半为B
| 位 | 值 | 位 | 值 |
|---|---|---|---|
| 0110000 | 1 | 0111000 | 1 |
| 1011110 | 712 | 1011111 | 712 |
| 0101001 | 2532 | 1011100 | 734 |
| 1101111 | 1512 | 1100 000 | 16 |
| 0000001 | 164 | 0001 000 | 164 |
可以看出第二,三,四的问题的关键在于进位
三的A为:0.11001,即到B先转化为1.1001,明显B的frac只有三位,所有根据close to even,需要接近偶数,所以,round down:1.100,符合。
比较有问题的是最后一个:000 0001 。首先,000说明是Denormalize,则该数表示为0.0001*2
−2
=2
−6
,由于B是4位exp,所以不会是最小的数,所以由Denormalize->Normalize,答案也为1/64
为什么要选择,close to even呢?如果全部的数字都为0.01要精确到小数点后一位的话,如果是四舍五入,那么最后的误差将是0.01*n,但如果是close to even的,认为偶数和奇数是等概率出现,就很小的避免误差往一边倒的情况。
- 浮点数的计算
首先先来两个公式
x+ f y=Round(x+y)
x × f y=Round(x × y)
可见浮点数的计算源于round
浮点数的乘法如下:
(-1) s1 M1*2 E1 × (-1) s2 *M2*2 E2
Exact Result:(-1) s *M*2 E
Sign s: s1^s2
Significand M: M1 × M2
Exponent E: E1+E2
Fixing:
If M>=2, shift M right, increment E
If E out of range, overflow
Round M to fit frac precision
Implementation
Biggest chore is multiplying significands
这里直接贴上相关计算浮点数相加的公式:
浮点数的加法和乘法由于近似的原因,经常无法实现加法的结合律和乘法分配律,如下所示:
(3.14+le10)-1e10=0.0,因为3.14+1e10会舍入,3.14会丢失(1e10表示1*10 10 )
但是3.14+(1e10-1e10)=3.14
le20*(le20-le20)=0.0
le20*le20-le20*le20=NaN,由于溢出的关系,可见在数字大的情况下不满足加法结合律和乘法分配律


最后,来看看double,float和int相互转化可能的问题

判断以下式子是否正确:

A.正确,因为double的frac为32位和int相同,不会丢失信息。
B.错误,因为float的frac为23位小于int,会丢失信息。
C.错误。double比float精度高。从double转float会丢失信息。
D.正确。
E.正确。符号数正负转化只取决于符号位。
F.正确。浮点数在进行运算的时候会全部转化为浮点数。
G.正确。

H.错误。如果f+d溢出,结果为0.

















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









