







1 加载数据
导入模块
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import numpy as np
import math
import xgboost as xgb
import toad
from toad.plot import bin_plot, badrate_plot
from matplotlib import pyplot as plt
from sklearn.preprocessing import StandardScaler
from toad.metrics import KS, F1, AUC
from toad.scorecard import ScoreCard
加载数据
# 加载数据
df = pd.read_csv('scorecard.txt')
print(df.info())
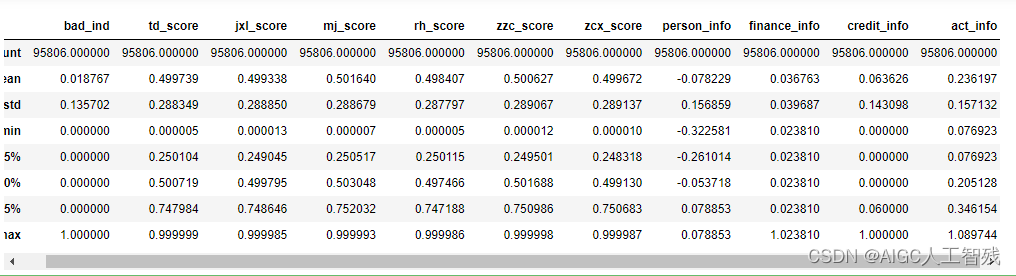
df.head()


df.describe()
数据划分
feature_list = list(df.columns)
feature_drop = ['bad_ind','uid','samp_type']
for lt in feature_drop:
feature_list.remove(lt)
df_dev = df[df['samp_type']=='dev']
df_val = df[df['samp_type']=='val']
df_off = df[df['samp_type']=='off']
print(feature_list)
print('dev',df_dev.shape)
print('val',df_val.shape)
print('off',df_off.shape)

简单数据分析
toad.detector.detect(df)
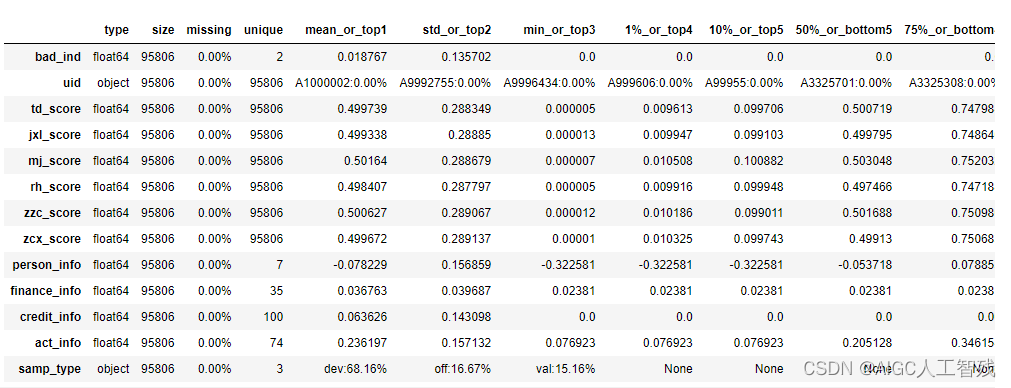
toad库能够同时处理数值型数据和分类型数据。由于没有缺失值,我们不用进行数据填充。
2 特征筛选
使用缺失率、IV和相关系数进行特征筛选。
# 根据缺失值、IV和相关系数进行特征筛选
dev_slt, drop_slt = toad.selection.select(df_dev, df_dev['bad_ind'],
empty=0.7,
iv=0.03,
corr=0.7,
return_drop=True,
exclude=feature_drop)
print('keep:', dev_slt.shape,';drop empty:',drop_slt['empty'].shape,';drop iv:',drop_slt['iv'].shape,';drop_corr:',drop_slt['corr'].shape)
keep: (65304, 12) ;drop empty: (0,) ;drop iv: (1,) ;drop_corr: (0,)
3 卡方分箱
使用toad库,能够对所有特征切分节点,然后进行分箱
# 使用卡方分箱
# 使用卡方分箱
cmb = toad.transform.Combiner()
cmb.fit(dev_slt,
dev_slt['bad_ind'],
method='chi',
min_samples=0.05,
exclude=feature_drop)
bins = cmb.export()
print(bins)
{‘td_score’: [0.7989831262724624], ‘jxl_score’: [0.4197048501965005], ‘mj_score’: [0.3615303943747963], ‘zzc_score’: [0.4469861520889339], ‘zcx_score’: [0.7007847486465795], ‘person_info’: [-0.2610139784946237, -0.1286774193548387, -0.0537175627240143, 0.013863440860215, 0.0626602150537634, 0.078853046594982], ‘finance_info’: [0.0476190476190476], ‘credit_info’: [0.02, 0.04, 0.11], ‘act_info’: [0.1153846153846154, 0.141025641025641, 0.1666666666666666, 0.2051282051282051, 0.2692307692307692, 0.358974358974359, 0.3974358974358974, 0.5256410256410257]}
调整分箱
绘制Bivar图,观察该特征分享后是否单调性,不满足单调性需要调整分箱。
# 绘制bivar图,调整分箱
# 根据节点设置分箱
dev_slt2 = cmb.transform(dev_slt)
val2 = cmb.transform(df_val[dev_slt.columns])
off2 = cmb.transform(df_off[dev_slt.columns])
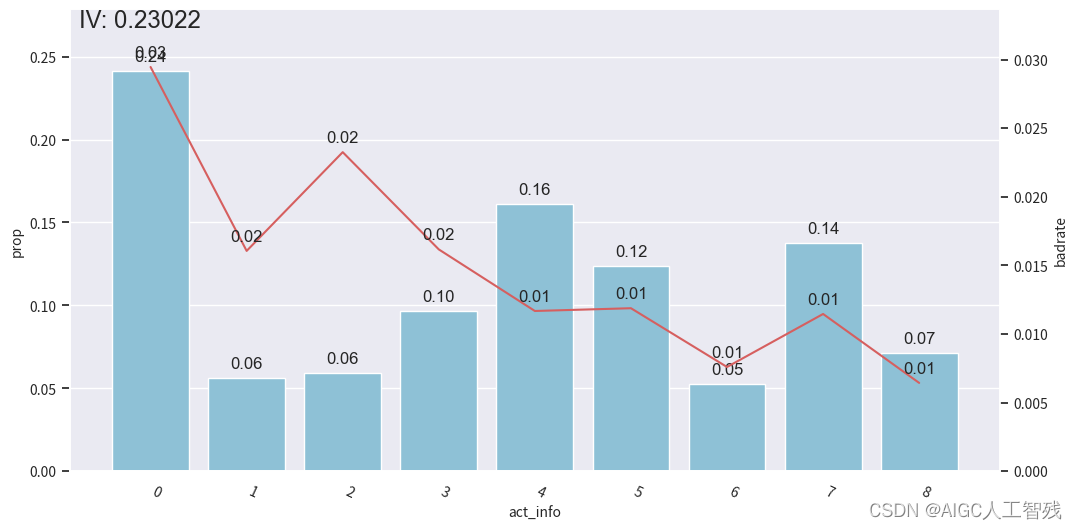
# 观察分箱后的图像-act_info
bin_plot(dev_slt2, x='act_info', target='bad_ind')
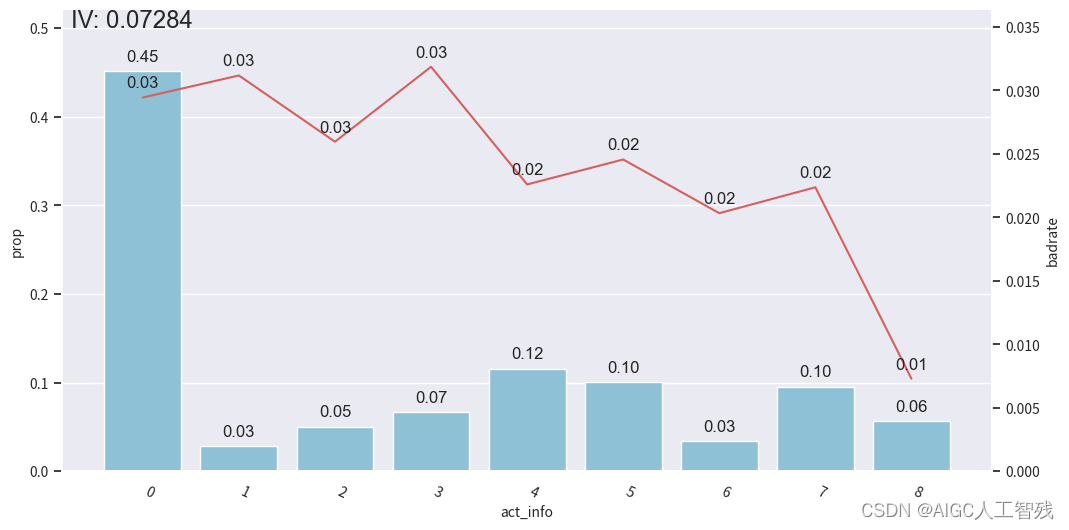
bin_plot(val2, x='act_info', target='bad_ind')
bin_plot(off2, x='act_info', target='bad_ind')
开发样本
测试样本
验证样本
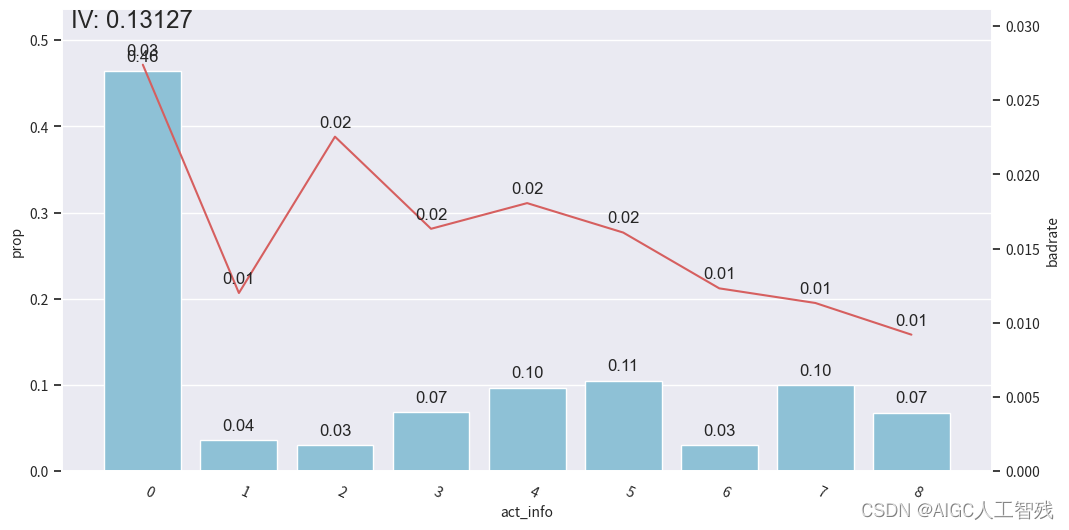
我们能看到前3箱出现上下波动,与整体的单调递减趋势不符,所以进行分箱合并。
# 没有呈现单调性,需要进行合并
bins['act_info']
[0.1153846153846154,
0.141025641025641,
0.1666666666666666,
0.205128205128205
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4361
4361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











