







MySQL-DB的优化技术
对mysql优化时一个综合性的技术,主要包括
a. 表的设计合理化(符合3NF)
b. 添加适当索引(index)
c. 分表技术(水平分割,垂直分割)
d. 读写分离
e. 存储过程(模块化编程,可以提高速度)
f. 对mysql配置优化(my.ini)
max_connections=1000(一般网站)调整缓存大小
g. mysql服务器硬件升级
h. 定时的去清除不要的数据,定时进行碎片整理(MyISAM)
InnoDB索引原理
互联网大多数应用是读多写小的,读写比例可达10:1;并且数据库在做查询时IO消耗较大,理论上,B+树的查找时间复杂度为log1.44(n),是大于logn的。从下图可以发现,MySQL是由一个个磁盘块组成的树形结构。每个磁盘块由数据项和指针组成。且所有的数据都是存放在叶子磁盘节点,非叶子磁盘节点不存放数据。
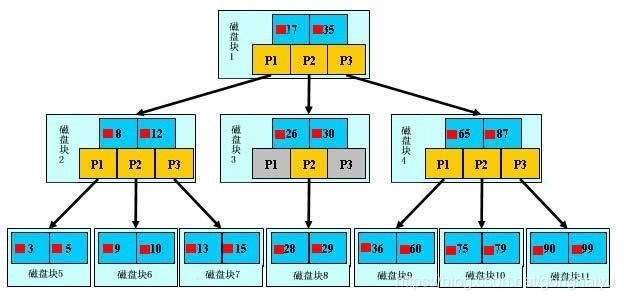
查找过程
以磁盘块1为例,指针 P1 表示小于17的磁盘块,P2 表示在 17~35 之间的磁盘块,P3 则表示大于35的磁盘块。
比如要查找数据项99,首先将磁盘块1 load 到内存中,发生 1 次 IO。接着通过二分查找发现 99 大于 35,所以找到了 P3 指针。通过P3 指针发生第二次 IO 将磁盘块4加载到内存。再通过二分查找发现大于87,通过 P3 指针发生了第三次 IO 将磁盘块11 加载到内存。最后再通过一次二分查找找到了数据项99。
由此可见,如果一个几百万的数据查询只需要进行三次 IO 即可找到数据,那么整个效率将是非常高的。
观察树的结构,发现查询需要经历几次 IO 是由树的高度来决定的,而树的高度又由磁盘块、数据项(主键)的大小决定的。
磁盘块越大,数据项越小那么树的高度就越低。这也就是为什么索引字段要尽可能小的原因。
关于索引的原理,可以参考:https://blog.csdn.net/QGhurt/article/details/108501927
什么样的表才是符合3NF(范式)
表的范式,是首先符合1NF,才能满足2NF,进一步满足3NF。
1NF:字段不可分。即表的列具有原子性,不可再分解,即列的信息不能分解。则满足第一范式。有很多同学在设计表时,里边存储了json格式,就不满足第一范式。

2NF:有主键,非主键字段依赖主键,通常我们设计一个主键来实现2NF。第二范式
3NF:即表中不要有冗余数据,就是说,表的信息,如果能够被推导出来,有时提高效率,增加冗余字段,采用反3NF更加合理。
添加适当的索引
2.1 sql语句本身的优化
如何从一个大项目中,迅速定位执行速度慢的语句?
-
了解mysqlDB运行的状态如何查询(想知道mysql运行的时间/一共执行了多少次select/update/delete,当前连接数)
-show status
-show status like “uptime”
-show status like “com_select”
-show [session| global] status like “com_insert” 类推:update,delete
-show status like ‘connections’;
-netstat –anp 查找端口
-show status like “slow_queries”;-慢查询 -
如何去定位慢查询
构建一个大表(400万)->存储过程构建
默认情况下,mysql认为10秒才是一个慢查询
修改mysql的慢查询.
-show variables like ‘long_query_time’;//显示当前慢查询的时间 -
set long_query_time = 1//修改慢查询的时间(永久生效,最好配合slow_query_log_file=/tmp/mysql_slow.log记录位置)2.set global slow_query_log=1重启后会失效。
构建大表:
为了存储过程能够正常执行,我们需要把命令执行结束符修改下
delimiter $$ -
在默认情况下mysql不记录慢查询日志,需要在启动的时候指定
bin\mysqld.exe –safe-mode –slow-query-log[mysql5.5可以在my.ini指定]
bin\mysqld.exe –log-slow-queries=d:/abc.log[低版本mysql5.0可以在my.ini指定]
先关闭mysql,再重新启动。如果启用了慢查询日志,默认把文件放在my.ini文件中记录的位置。
2.2优化问题
通过explain语句可以分析mysql如何执行sql语句。
添加索引-四种(主键索引、唯一索引、全文索引、普通索引)
1.主键索引
1.1添加索引
当一张表,把某个列设为主键的时候,则该列就是主键索引。主键会自动索引。
如果创建表时,没有指定主键索引,也可以在创建表后添加:
alter table 表名 add primary key(列名)
1.2查询索引
desc 表名(缺点:不能显示索引名)
show index(es) from 表名
show keys from 表名
2.全文索引
全文索引,主要是针对文件,文本的检索,比如文章,全文索引针对MyISAM有用。
创造表时指定索引类型engine=myisam charset utf8
错误用法:
select * from articles where body like ‘%mysql%’;【不会使用到全文索引】
证明:
explain select * from articles where body like ‘%mysql%’
正确的用法是:
select * from articles where match(title,body) against (‘database’)【可以】
说明:
1.在mysql中fulltext 索引只针对myisam生效
2.mysql自己提供的fulltext,针对英文生效->sphinx(coreseek)技术处理中文
3.使用方法是match(字段名)against('关键字’)
4.全文索引一个叫停止词,因为在一个文本中,创建索引是一个无穷大的数,因此,对一些常用词和字符,就不会创建,这些词,称为停止词。a an the 等。
3. 唯一索引
1.当表的某列被指定为unique约束时,这列就是一个唯一索引(索引内的值不允许重复)。
create table ddd(id int primary key auto_imcrement,name varchar(32) unique);
这时name列就是一个唯一索引。
unique 字段可以为NULL,并可以有多个,但是如果有具体的内容,则不能重复
主键字段,不能为NULL,也不能重发
2.在创建表后,再去创建唯一索引
create table eee(id int primary key auto_increment ,name varchar(32));
create unique index 索引名 on 表名(列名)
3.复合索引
3.1创建
create index 索引名 on 表(列1,列2)
3.2删除
alter table 表名 drop index 索引名;
如果删除主键索引:
alter table 表名 drop primary key
3.3修改
先删除,再重新创建
索引使用的注意事项。
2.3索引的代价
1.磁盘占用
2.对dml(update delete insert)语句的效率影响,变慢,因为要维护索引文件
存储引擎 允许的索引类型
MyISAM BTREE
InnoDB BTREE
MEMORY/HEAP HASH,BTREE
2.4在哪些列上适合添加索引
1.较频繁的作为查询条件字段应该创建索引
Select * from emp where eno = 1
2. 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
Select * from emp where sex=‘男’
3. 更新非常频繁的字段不适合创建索引
Select * from emp where logincount = 1
4. 不会出现在where子句中字段不该创建索引
总结:满足以下条件,才应该创建索引:
a. 肯定在where条经常使用。
b. 该字段内容不是唯一的几个值(sex)
c. 字段内容不是频繁变化(update)
5. 负向查询不能使用索引,比如not in 就不能使用索引,in(少数)会使用索引。
6. 经常需要排序、分组和联合操作的字段上建立索引。
7. 限制索引的数目,越多的索引,在更新时需要更新所有索引,则变慢。
8. 尽量使用数据量少的索引,如果索引的值很长,那么查询的速度会受到影响。尽量使用前缀索引。
9. 索引列不能参与计算,保持列“干净”;带函数的查询不参与索引。
2.5使用索引的注意事项
- 对于创建多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。右边的就不会使用索引。
Explain可以帮助我们在不真正执行某个sql语句时,就执行mysql怎样执行,这样利用我们去分析sql指令。


select_type
PRIMARY:子查询中最外层查询
SUBQUERY:子查询内层第一个SELECT,结果不依赖于外部查询
DEPENDENT SUBQUERY:子查询内层第一个SELECT,依赖于外部查询。
UNION:UNION语句中第二个SELECT开始后面所有的SELECT。
SIMPLE
UNION RESULT UNION中合并结果

-
对于使用like的查询,查询如果是‘%aaa%’,不会使用到索引。‘aa%’会使用到索引。比如:explain select * from dept where dname like ‘%aaa’\G 不能使用索引,即,在like查询时,关键字最前面,不能使用%或者_这样的字符,如果一定要前面有变化的值,则考虑使用全文索引->sphinx。
-
下列的表将不使用索引:
a. 如果条件中有or,即使其中有条件带索引也不会使用。换言之,就是要求使用的所有字段都必须建立索引。建议不要使用or
b. 对于多列索引,不是使用的第一部分,则不会使用索引。
c. like查询是以%开头
d. 如果列类型是字符串,那一定要在条件中将数据使用引号引起来。否则不使用索引。(添加时,字符串必须”),也就是,如果列是字符串类型,就一定要用“”把查询内容包括起来。
e. 如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
f. 不同字符集的字段关联查询不能使用索引,会直接报错。 -
如何查看索引使用情况:
Show status like ‘handler_read”;这个值越高说明索引使用率越高。而handler_read_rnc_next:这个值越高,说明查询低效。 -
查询具体的字段而非全部字段
要尽量避免使用 select *,而是查询需要的字段,这样可以提升速度,以及减少网络传输的带宽压力。 -
优化子查询
尽量使用 Join 语句来替代子查询,因为子查询是嵌套查询,而嵌套查询会新创建一张临时表,而临时表的创建与销毁会占用一定的系统资源以及花费一定的时间,但 Join 语句并不会创建临时表,因此性能会更高。 -
注意查询结果集
我们要尽量使用小表驱动大表的方式进行查询,也就是如果 B 表的数据小于 A 表的数据,那执行的顺序就是先查 B 表再查 A 表。 -
不要在列上进行运算操作
不要在列字段上进行算术运算或其他表达式运算,否则可能会导致查询引擎无法正确使用索引,从而影响了查询的效率。 -
适当增加冗余字段
增加冗余字段可以减少大量的连表查询,因为多张表的连表查询性能很低,所有可以适当的增加冗余字段,以减少多张表的关联查询,这是以空间换时间的优化策略。 -
字段默认值不要使用null,目前的规范是索引字段不要使用null,其他字段可以使用null。select count(*) 是会查出满足条件的null的字段记录,但是select count(1)不会查出这些数据。
-
如果明确只有一条记录,则使用 limit 1,可以提高效率,让数据库停止游标移动。
-
查找类型与数据库要保持一致,虽然可查出数据,但不会使用索引。join字段两表字段类型相同,不然不会命中索引。
2.6 SQL语句的小技巧
a. 在使用group by 分组查询时,默认分组后,还会排序,可能会降低速度。在group by后面增加order by null就可以防止排序。
b. 有些情况下,可以使用连接来替换子查询,因为使用join,Mysql不需要在内存中创建临时表。
Select * from dept,emp where dept.deptno=emp.deptno;【简单处理方式】
Select * from dept left join emp on dept.deptno= emp.deptno:【左外连接,更好】
2.7如何选择mysql的存储引擎
Myisam存储:如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎。比如:bbs中的发帖表,回复表。
INNODB存储:对事务要求高,保存的数据都是重要数据,我们建议使用INNODB,比如订单表,账号表
问MyISAM和INNODB的区别
-
事务安全
-
查询和添加速度
-
支持全文检索
-
锁机制
-
外键 MyISAM不支持外键,INNODB支持外键。(在php开发中,通常不设置外键,通常是在程序中保证数据的一致,而在java中,建议是设置外键的)

-
如果你的数据库的存储引擎是myisam,请一定记住要定时进行碎片整理。
通过optimize table test100(表名)。或者mysql_query(“optimize tables $表名”);
2.8 PHP定时完成数据库的备份
a. 手动备份数据库(表的)方法 mysqldump –u root –proot 数据库名字[表名1 表名2 ]>文件路径
b. 如何使用备份文件恢复数据:在mysql控制台:source d:\temp.dept.bak
c. 使用定时器自动完成
把备份数据库的指令,写入到bat文件,然后通过任务调度器crontab.定时调用bat文件。
如果mysqdump文件路径中有空格,则一定要使用“”包括。把mytask.bat做成一个任务,并定时调用,在2:00调用一次。
控制面板-任务计划中添加任务计划。
3.分表技术
1.水平分割
a. 表的分割技术
分表or 使用内存缓存(但数据量超大不行)
分表规则:
qqlogin0,qqlogin1,qqlogin2:根据用户id%3=值,根据值来取出这个用户在哪个表,$tbname=’qqlogin’.%id%3;然后查询tbname这张表。
b.我们在提供检索时,应该业务的需求,找到分表的标准,并在检索页面,约束用户检索的方式->分页,如果有大表检索的需求也是少数。
2.垂直分割
把某个表的某些字段,这些字段,在查询时,并不是已经关系,但是数据量大,建议把这些字段单独放到另外一个表中,提高效率。
a. 表的字段定义是保小不保大。Tinyint(1),tinyint(2):0前痛 01
注意:主键最好是不含业务逻辑。
关于网站的图片和视频存放,我们的数据库中,一般只是存放图片或者视频的路径。资源是放在文件系统(往往配合独立的服务器)
b. 如何优化mysql配置文件。
端口号
最大连接数
缓存
my.inif
max_connections = 1000(这里最大2000)
query_cache_size
最重要的参数是内存,我们主要用的是innodb引擎,所以,下面两个参数调的很大
innodb_additional_mem_pool_size =64M
innodb_buffer_pool_size = 1G
对于myisam,需要调整key_buffer_size
当然调整参数还是要看状态,用show status语句可以看到当前状态,以决定调整哪些参数。
4.读写分离
读写分离amoeba(新浪)mysql-proxy,或者直接使用shardingjdbc或者数据库的读写分离。
5. mysql的增量备份
问题提出:
增量备份的定义:mysql数据库会以二进制的形式,自动把用户对mysql数据库的操作记录到文件中。当用户希望恢复到时候可以使用备份文件进行恢复。
增量备份会记录(dml语句,创建表的语句,不会记录select)
记录的(a. 操作语句本身 b. 操作的时间 c.position)一个机器上可以安装两个mysql,但是同版本的不能安装。
步骤:
(1)这里指定把备份文件放到哪个目录。
log-bin=d:/binlog/log/mysqllog
(2)启动mysql得到文件
d:/binlog/mylog/mylog.index 索引文件,有哪些增量备份文件。
d:/binlog/mylog/mylog.000001存放数据库操作的文件。
(3)可以使用mysqlbinlog程序来查看备份文件的内容。当我们进行除select操作。
进入到cmd控制台
cmd>mysqlbinlogg 备份文件路径。

(4) 恢复(一定要看日志文件)方式有两种:a. 时间点;b.位置。
a.时间点:mysqlbinlog –stop-position=”3862” d:\binlog\mylog.000001 | mysql –uroot –proot
时间段: mysqlbinlog –start-datetime=”2013-01-12 18:20:21”-stop-datetime=”3862” d:\binlog\mylog.000001 | mysql –uroot –proot
b. 位置:mysqlbinlog –start-datatime=”2013-01-12 18:20:21”
d:\binlog\mylog.000001 | mysql –uroot –proot
c. 设置日志过期时间:my.cnf下,[mysqld]下添加expire_logs_day=3
(5)如何在工作中将全备份和增量备份配合使用
方案:每周一做一个全备份。Mysqldump,启用增量备份,把过期时间设为大于等于7。
如果出现数据库奔溃,就可以通过时间或者位置恢复。(需要去看日志文件)
6.其他优化
6.1 数据库结构优化
- 最小数据长度
- 使用最简单数据类型(其实同上)
- 尽量少定义 text 类型
- 适当分表、分库策略
6.2 硬件优化
MySQL 对硬件的要求主要体现在三个方面:磁盘、网络和内存。
- 磁盘
磁盘应该尽量使用有高性能读写能力的磁盘,比如固态硬盘,这样就可以减少 I/O 运行的时间,从而提高了 MySQL 整体的运行效率。
磁盘也可以尽量使用多个小磁盘而不是一个大磁盘,因为磁盘的转速是固定的,有多个小磁盘就相当于拥有多个并行运行的磁盘一样。 - 网络
保证网络带宽的通畅(低延迟)以及够大的网络带宽是 MySQL 正常运行的基本条件,如果条件允许的话也可以设置多个网卡,以提高网络高峰期 MySQL 服务器的运行效率。 - 内存
MySQL 服务器的内存越大,那么存储和缓存的信息也就越多,而内存的性能是非常高的,从而提高了整个 MySQL 的运行效率。














 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









