







0x00 前言
MD5是一种哈希算法,用来保证信息的完整性。
就一段信息对应一个哈希值,且不能通过哈希值推出这段信息,而且还需要保证不存在任意两段不相同的信息对应同一个哈希值。不过MD5算法算出来的值也就16个字节(16*8=128,即128位),肯定存在相同的,找到另一个所花时间长短而已。
参考资料:
1、 The MD5 Message-Digest Algorithm
2、The MD5 Message-Digest Algorithm 中文版
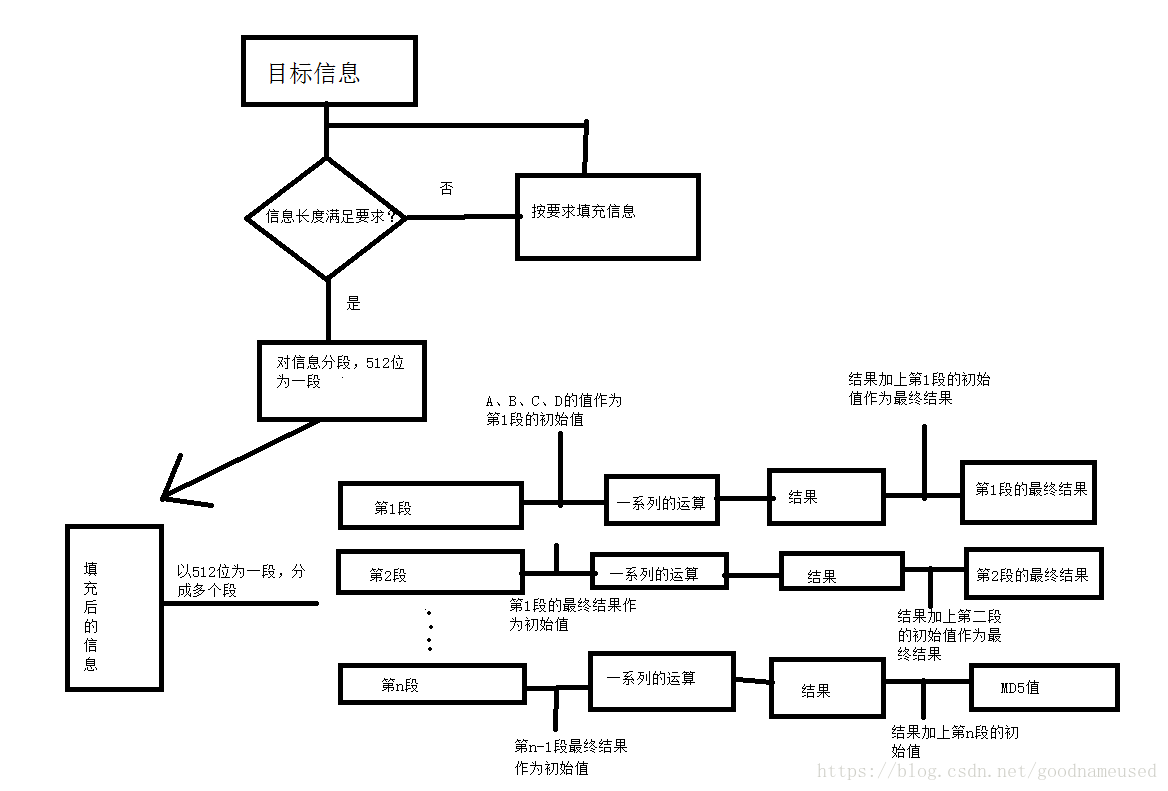
0x01 填充信息
在计算机中,数据存储都是二进制存储的,所以任意一个文件都是些二进制。
每个文件(消息)的大小(长短)都不一样,所以在计算MD5值之前,要将这些文件(消息)用特定内容填充到指定的情况为止。(这里的大小长度是指字节数),本文约定用s_m表示原本的文件(消息)的大小(长度),s_mb表示单位位bit(位),s_mB表示单位为Byte(字节)。
填充的过程如下:
1.先判断消息的长度 s_mb % 512 == 448 ,就是长度对512求余等于448。(这里的512、448是“位”为单位,转成“字节”就是64、56,即s_mB % 64 == 56 填充动作一定要进行,不管消息长度是否符合要求。)
2.如果长度满足 s_mb % 512 == 448,就在文件(消息)的末尾处添加64位(8字节)的值,值的内容是原消息的长度(以位为单位)
3.如果长度不满足要求,就执行以下操作:
(1)填充1个1
(2)填充0,直到满足满足过程的第一步。
注意:这里是以位为单位,假如是以字节为单位,第一个填充的是0x80(1000 0000),然后就填0x0,填充到56个字节
(3)最后填充8个字节,使得整个消息的长度满足64的倍数即m_sB == k * 64 (m_sb == k * 512)。
举例:消息内容为“gnubd”,就能得到以下内容
67 6E 75 62 64 80 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 28 00 00 00 00 00 00 00
注意到最后面这里有个0x28,数8个字节,就是0x0000000000000028,刚刚好是十进制的40,消息的内容是5个字节,也就是40位,还要注意到这里是小端字节序存储
0x02 数据说明
填充信息满足要求后就要开始计算MD5值了,首先先把需要的东西先列出来:
DWORD md5::A = 0x67452301;
DWORD md5::B = 0xEFCDAB89;
DWORD md5::C = 0x98BADCFE;
DWORD md5::D = 0x10325476;
DWORD md5::T[64] = {
0xD76AA478,0xE8C7B756,0x242070DB,0xC1BDCEEE,0xF57C0FAF,0x4787C62A,0xA8304613,0xFD469501,
0x698098D8,0x8B44F7AF,0xFFFF5BB1,0x895CD7BE,0x6B901122,0xFD987193,0xA679438E,0x49B40821,
0xF61E2562,0xC040B340,0x265E5A51,0xE9B6C7AA,0xD62F105D,0x02441453,0xD8A1E681,0xE7D3FBC8,
0x21E1CDE6,0xC33707D6,0xF4D50D87,0x455A14ED,0xA9E3E905,0xFCEFA3F8,0x676F02D9,0x8D2A4C8A,
0xFFFA3942,0x8771F681,0x6D9D6122,0xFDE5380C,0xA4BEEA44,0x4BDECFA9,0xF6BB4B60,0xBEBFBC70,
0x289B7EC6,0xEAA127FA,0xD4EF3085,0x04881D05,0xD9D4D039,0xE6DB99E5,0x1FA27CF8,0xC4AC5665,
0xF4292244,0x432AFF97,0xAB9423A7,0xFC93A039,0x655B59C3,0x8F0CCC92,0xFFEFF47D,0x85845DD1,
0x6FA87E4F,0xFE2CE6E0,0xA3014314,0x4E0811A1,0xF7537E82,0xBD3AF235,0x2AD7D2BB,0xEB86D391
};
DWORD md5::s[64]={
7,12,17,22,7,12,17,22,7,12,17,22,7,12,17,22,
5,9,14,20,5,9,14,20,5,9,14,20,5,9,14,20,
4,11,16,23,4,11,16,23,4,11,16,23,4,11,16,23,
6,10,15,21,6,10,15,21,6,10,15,21,6,10,15,21
};
DWORD md5::m[64]={
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,
1,6,11,0,5,10,15,4,9,14,3,8,13,2,7,12,
5,8,11,14,1,4,7,10,13,0,3,6,9,12,15,2,
0,7,14,5,12,3,10,1,8,15,6,13,4,11,2,9
};
看上去很复杂,其实不是。
首先前4个数值A、B、C、D,它们原本的值是这样的:
A = 0x01234567
B = 0x89ABCDEF
C = 0xFEDCBA89
D = 0x76543210
小端存储的情况下,为了保证ABCD4个值在内存中的显示情况为上面情况,所以要调整数字的位置,故实际情况是:
A = 0x67452301;
B = 0xEFCDAB89;
C = 0x98BADCFE;
D = 0x10325476;
0x03 处理信息
经过信息填充后,填充后的信息长度肯定是512位(64字节)的倍数,也就是说每512位(64字节)为1段可以分成n段,(n大于等于1),对于每一段信息(512位,64字节)又划分成16小段(每段32位,4个字节,用x表示)
用上面的消息为例,x为
x[16] = {0x676E7562, 0x64800000, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000,
0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x28000000, 0x00000000}
对于每一段信息,都会经过下列的运算处理,共4种函数
FF(a,b,c,d,x,s,ti)
GG(a,b,c,d,x,s,ti)
HH(a,b,c,d,x,s,ti)
II(a,b,c,d,x,s,ti)
对于每种函数都会共执行64次
执行顺序是:
先执行16次FF,再执行16次GG,再执行16次HH,最后执行16次II,可以把这个4种函数各执行16次看作一次周期,那么这样的周期有4个,可以简单理解为:
for(i = 0; i < 4; ++i) {
FF(16); //括号内为执行次数
GG(16);
HH(16);
II(16);
}
函数的内容分别是:
void md5::FF(DWORD &a,DWORD &b,DWORD &c,DWORD &d,DWORD x,DWORD s,DWORD ti){
DWORD temp = F(b,c,d) + a + x + ti;
temp = (temp<<s)|(temp>>(32-s));
a = b + temp;
}
void md5::GG(DWORD &a,DWORD &b,DWORD &c,DWORD &d,DWORD x,DWORD s,DWORD ti){
DWORD temp = G(b,c,d) + a + x + ti;
temp = (temp<<s)|(temp>>(32-s));
a = b + temp;
}
void md5::HH(DWORD &a,DWORD &b,DWORD &c,DWORD &d,DWORD x,DWORD s,DWORD ti){
DWORD temp = H(b,c,d) + a + x + ti;
temp = (temp<<s)|(temp>>(32-s));
a = b + temp;
}
void md5::II(DWORD &a,DWORD &b,DWORD &c,DWORD &d,DWORD x,DWORD s,DWORD ti){
DWORD temp = I(b,c,d) + a + x + ti;
temp = (temp<<s)|(temp>>(32-s));
a = b + temp;
}
#define S11 7
#define S12 12
#define S13 17
#define S14 22
#define S21 5
#define S22 9
#define S23 14
#define S24 20
#define S31 4
#define S32 11
#define S33 16
#define S34 23
#define S41 6
#define S42 10
#define S43 15
#define S44 21
其中,F,G,H,I分别是:
DWORD md5::F(DWORD X,DWORD Y,DWORD Z){
return (X&Y)|((~X)&Z);
}
DWORD md5::G(DWORD X,DWORD Y,DWORD Z){
return (X&Z)|(Y&(~Z));
}
DWORD md5::H(DWORD X,DWORD Y,DWORD Z){
return X^Y^Z;
}
DWORD md5::I(DWORD X,DWORD Y,DWORD Z){
return Y^(X|(~Z));
}
调用举例说明
FF (a, b, c, d, x[ 0], S11, 0xd76aa478); /* 1 */
FF (d, a, b, c, x[ 1], S12, 0xe8c7b756); /* 2 */
FF (c, d, a, b, x[ 2], S13, 0x242070db); /* 3 */
FF (b, c, d, a, x[ 3], S14, 0xc1bdceee); /* 4 */
FF (a, b, c, d, x[ 4], S11, 0xf57c0faf); /* 5 */
FF (d, a, b, c, x[ 5], S12, 0x4787c62a); /* 6 */
FF (c, d, a, b, x[ 6], S13, 0xa8304613); /* 7 */
FF (b, c, d, a, x[ 7], S14, 0xfd469501); /* 8 */
FF (a, b, c, d, x[ 8], S11, 0x698098d8); /* 9 */
FF (d, a, b, c, x[ 9], S12, 0x8b44f7af); /* 10 */
FF (c, d, a, b, x[10], S13, 0xffff5bb1); /* 11 */
FF (b, c, d, a, x[11], S14, 0x895cd7be); /* 12 */
FF (a, b, c, d, x[12], S11, 0x6b901122); /* 13 */
FF (d, a, b, c, x[13], S12, 0xfd987193); /* 14 */
FF (c, d, a, b, x[14], S13, 0xa679438e); /* 15 */
FF (b, c, d, a, x[15], S14, 0x49b40821); /* 16 */
/* Round 2 */
GG (a, b, c, d, x[ 1], S21, 0xf61e2562); /* 17 */
GG (d, a, b, c, x[ 6], S22, 0xc040b340); /* 18 */
GG (c, d, a, b, x[11], S23, 0x265e5a51); /* 19 */
GG (b, c, d, a, x[ 0], S24, 0xe9b6c7aa); /* 20 */
GG (a, b, c, d, x[ 5], S21, 0xd62f105d); /* 21 */
GG (d, a, b, c, x[10], S22, 0x2441453); /* 22 */
GG (c, d, a, b, x[15], S23, 0xd8a1e681); /* 23 */
GG (b, c, d, a, x[ 4], S24, 0xe7d3fbc8); /* 24 */
GG (a, b, c, d, x[ 9], S21, 0x21e1cde6); /* 25 */
GG (d, a, b, c, x[14], S22, 0xc33707d6); /* 26 */
GG (c, d, a, b, x[ 3], S23, 0xf4d50d87); /* 27 */
GG (b, c, d, a, x[ 8], S24, 0x455a14ed); /* 28 */
GG (a, b, c, d, x[13], S21, 0xa9e3e905); /* 29 */
GG (d, a, b, c, x[ 2], S22, 0xfcefa3f8); /* 30 */
GG (c, d, a, b, x[ 7], S23, 0x676f02d9); /* 31 */
GG (b, c, d, a, x[12], S24, 0x8d2a4c8a); /* 32 */
/* Round 3 */
HH (a, b, c, d, x[ 5], S31, 0xfffa3942); /* 33 */
HH (d, a, b, c, x[ 8], S32, 0x8771f681); /* 34 */
HH (c, d, a, b, x[11], S33, 0x6d9d6122); /* 35 */
HH (b, c, d, a, x[14], S34, 0xfde5380c); /* 36 */
HH (a, b, c, d, x[ 1], S31, 0xa4beea44); /* 37 */
HH (d, a, b, c, x[ 4], S32, 0x4bdecfa9); /* 38 */
HH (c, d, a, b, x[ 7], S33, 0xf6bb4b60); /* 39 */
HH (b, c, d, a, x[10], S34, 0xbebfbc70); /* 40 */
HH (a, b, c, d, x[13], S31, 0x289b7ec6); /* 41 */
HH (d, a, b, c, x[ 0], S32, 0xeaa127fa); /* 42 */
HH (c, d, a, b, x[ 3], S33, 0xd4ef3085); /* 43 */
HH (b, c, d, a, x[ 6], S34, 0x4881d05); /* 44 */
HH (a, b, c, d, x[ 9], S31, 0xd9d4d039); /* 45 */
HH (d, a, b, c, x[12], S32, 0xe6db99e5); /* 46 */
HH (c, d, a, b, x[15], S33, 0x1fa27cf8); /* 47 */
HH (b, c, d, a, x[ 2], S34, 0xc4ac5665); /* 48 */
/* Round 4 */
II (a, b, c, d, x[ 0], S41, 0xf4292244); /* 49 */
II (d, a, b, c, x[ 7], S42, 0x432aff97); /* 50 */
II (c, d, a, b, x[14], S43, 0xab9423a7); /* 51 */
II (b, c, d, a, x[ 5], S44, 0xfc93a039); /* 52 */
II (a, b, c, d, x[12], S41, 0x655b59c3); /* 53 */
II (d, a, b, c, x[ 3], S42, 0x8f0ccc92); /* 54 */
II (c, d, a, b, x[10], S43, 0xffeff47d); /* 55 */
II (b, c, d, a, x[ 1], S44, 0x85845dd1); /* 56 */
II (a, b, c, d, x[ 8], S41, 0x6fa87e4f); /* 57 */
II (d, a, b, c, x[15], S42, 0xfe2ce6e0); /* 58 */
II (c, d, a, b, x[ 6], S43, 0xa3014314); /* 59 */
II (b, c, d, a, x[13], S44, 0x4e0811a1); /* 60 */
II (a, b, c, d, x[ 4], S41, 0xf7537e82); /* 61 */
II (d, a, b, c, x[11], S42, 0xbd3af235); /* 62 */
II (c, d, a, b, x[ 2], S43, 0x2ad7d2bb); /* 63 */
II (b, c, d, a, x[ 9], S44, 0xeb86d391); /* 64 */
x是上面每一段的16个小段了,其中m[j]表示每次函数处理的小段都不同,按照一定的顺序来处理每个小段,其中的顺序就在x中保存了。
Sxx是循环左移的位数,也有一定顺序。
T是常数,共64个,意味着64次的函数调用都是用不同的数值
对于第一段消息(前512位(64个字节))传入的a,b,c,d的值是上面的ABCD4个有规律的值。
第一段消息处理完后(即4个函数各执行了16次之后),得到新的a,b,c,d的值,将它们分别加上原来a,b,c,d的值(即计算前的值),作为下一段消息(第2个512位(64个字节))的初始a,b,c,d的值。
当每段消息(512位,64个字节)都处理完之后,得到的a,b,c,d的值,按照地址的顺序从低到高打印对应的值,就是所求的MD5值。

















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









