







机器学习实战-模型评估
对于所学到的东西需要做一个评估。
错误率
错误率=a个样本分类错误/m个样本
精度=1-错误率
误差:学习器与实际预测输出与样本的真实值产生的差异
训练误差:即经验误差,学习器在训练集上的误差
泛化误差:学习器在新样本上的误差。
评估方法
留出法
D分为两个互斥的集合,一个作为S,一个作为T。
分层采样:S中正例和T中反例子一样。比如,D中有500正例子,500反例子。分层采样获得70%的样本有S,有350正例子,350反例子;其中30%的样本T,有150正例子,150反例子。
一般采用随机划分,重复进行实验评估后取平均值作为留出法的评估结果。
例如,进行100次随机划分,每次产生一个训练/测试集用于实验评估,100次后得到100个结果,而留出法返回的是100个结果的平均。
交叉验证法
也称作K折算法,D划分为k个大小相似的互斥子集。D通过分层采样得到每个子集Di,保持数据分布的一致性。每次用k-1个子集的并集作为训练集,余下那个作为测试集。既可以获得k组训练/测试集。进行k次训练和测试,最终返回k个测试结果的均值。
比如,第一次,1/10作为训练,9/10作为测试,然后2/10作为训练,8/10作为测试....
性能度量
均方误差。查准率,查全率,F1
PR曲线
二分类问题:true positive 真正例,False positive 假正例,True negative 真反例,False negative 假反例
查准率P = TP/(TP+FP)
查全率R = TP/(TP+FN)
通常来说,查准率高,查全率比较低;
学习器最可能是把正例的样本排在前面,按此排序,把样本作为正例进行预测。
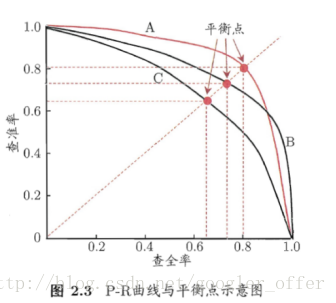
A优于B
F1
F1=(2*P*R)/(P+R)=2*TP/样例总数+TP-TN
Fb = (1+b^2)*P*R/[(b^2*P)+R]
b>0度量了查全率对查准率的相对重要性,当b=1的时候退化为F1,,b>1的时候对查全率影响比较大,相反对查准率比较大。
F1是查全率与查准率的调和平均,Fb则是加权平均。
类似还有混淆矩阵等。
ROC,AUC曲线
ROC:纵轴:真正率TPR,横轴:假正率FPR
TPR=TP/(TP+FN),FPR=FP/(TN+FP)
若一个学习器的ROC曲线被另一个包住了,则后者的性能要强;若交叉则判断AUC面积。
检验















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









