







原文:Real-World Machine Learning: Model Evaluation and Optimization
作者:Henrik Brink, Joseph W. Richards, Mark Fetherolf
译者:赵屹华
审校:刘翔宇
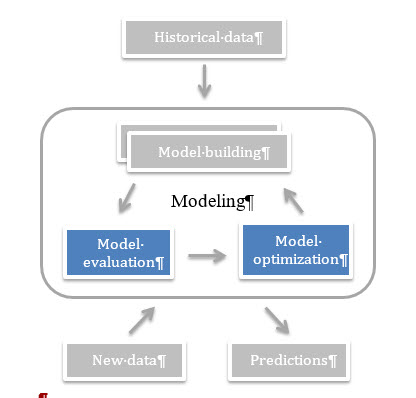
监督学习的主要任务就是用模型实现精准的预测。我们希望自己的机器学习模型在新数据(未被标注过的)上取得尽可能高的准确率。换句话说,也就是我们希望用训练数据训练得到的模型能适用于待测试的新数据。正是这样,当实际开发中训练得到一个新模型时,我们才有把握用它预测出高质量的结果。
因此,当我们在评估模型的性能时,我们需要知道某个模型在新数据集上的表现如何。这个看似简单的问题却隐藏着诸多难题和陷阱,即使是经验丰富的机器学习用户也不免陷入其中。我们将在本文中讲述评估机器学习模型时遇到的难点,提出一种便捷的流程来克服那些棘手的问题,并给出模型效果的无偏估计。
问题:过拟合与模型优化
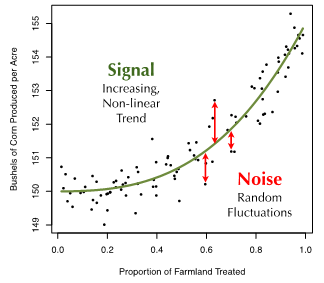
假设我们要预测一个农场谷物的亩产量,其亩产量与农场里喷洒农药的耕地比例呈一种函数关系。我们针对这一回归问题已经收集了100个农场的数据。若将目标值(谷物亩产量)与特征(喷洒农药的耕地比例)画在坐标系上,可以看到它们之间存在一个明显的非线性递增关系,数据点本身也有一些随机的扰动(见图1)。
为了描述评价模型预测准确性所涉及的一些挑战,我们从这个例子说开去。
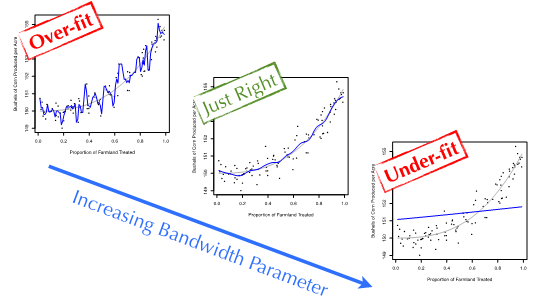
现在,假设我们要使用一个简单的非参数回归模型来构建耕地农药使用率和谷物亩产量的模型。最简单的机器学习回归模型之一就是内核平滑技术。内核平滑即计算局部平均:对于每一个新的数据来说,用与其特征值接近的训练数据点求平均值来对其目标变量建模。唯一一个参数——宽参数,是用来控制局部平均的窗口大小。
图2演示了内核平滑窗宽参数取值不同所产生的效果。窗宽值较大时,几乎是用所有训练数据的平均值来预测测试集里每个数据点的目标值。这导致模型很平坦,对训练数据分布的明显趋势欠拟合(under-fit)了。同样,窗宽值过小时,每次预测只用到了待测数据点周围一两个训练数据。因此,模型把训练数据点的起伏波动完完全全地反映出来。这种疑似拟合噪音数据而非真实信号的现象被称为过拟合(over-fitting)。我们的理想情况是处于一个平衡状态:既不欠拟合,也不过拟合。
现在,我们再来重温一遍问题:判断分析机器学习模型对预测其它农场的谷物产量的泛化能力。这个过程的第一步就是选择一个能反映预测能力的评估指标(evaluation metric)。对于回归问题,标准的评估方法是均方误差(MSE),即目标变量的真实值与模型预测值的误差平方的平均值。
这正是令人棘手的地方。当我们拟合训练数据时,模型预测的误差(MSE)随着窗宽参数的减小而减小。这个结果并不出人意料:因为模型的灵活度越高,它对训练数据模式(包括信号和噪音)的拟合度也越好。然而,由于窗宽最小的模型拟合了训练数据的每一处随机因素导致的波动,它在训练数据集上出现了严重的过拟合情况。若用这些模型来预测新的数据将会导致糟糕的准确率,因为新数据的噪音与训练数据的噪音模式不尽相同。
所以,训练集的误差和机器学习模型的泛化误差(generalization
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3705
3705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









