







文章目录
前言
记录学习的SAS统计模型,正文内容汇集课本,网友帖子和个人理解。
第一章 生存分析
一、什么是生存分析?
在医学或者公共卫生研究中,慢性疾病的发生、发展、预后一般不适用于治愈率、病死率等指标来考核,因为其无法在短时间内明确判断预后情况,为此,只能对患者进行长期随访,统计一定时期后的生存或死亡情况以判断诊疗效果;这样的研究往往会产生带有结局的生存时间资料,英文是time-to-event资料。在分析方法上,需要采用生存分析方法。
1. 生存分析定义
对“生存”两字,不能顾名思义。生存数据不仅仅指的是生命是生、是死的数据;广义而言,生存结局指的是研究对象是否出现我们研究者感兴趣的阳性终点事件;更广泛来说,生存结局是某一现象是否出现失效(failure)事件。
比如说:
研究某病治疗后的复发情况,复发就是“死亡”,未复发就是“生存”。复发是终点事件,这里生存分析主要研究“复发”有关的医学规律。研究戒烟后复吸的因素,复吸就是“死亡”,未复吸就是“生存”。复吸是终点事件,这里生存分析主要研究“复吸”有关的医学规律不仅医学,各个学科都有生存数据的影子,比如研究工作后升迁的因素有哪些,升迁就是“死亡”,未升迁就是“生存”。工业生产中,也需要分析一种仪器设备的生存情况,比如一个零部件如果出现破损,即为“死亡”,否则为生存。企业管理者可能感兴趣,为什么有些零部件会“死亡”呢?所以学习生存分析,首先要理解生存分析的终点事件,往往不是死亡!不要被“生存”两字所迷惑。
2. 生存数据的组成
生存数据可不仅仅是生存或者死亡、复发/不复发、阴性/阳性等这一二分类结局,它其实包括了2个结局指标,是否出现终点事件即EVENT变量和所经历的生存时间即DURATION变量。

生存分析另外一个重要的数据是有关研究对象是否出现结局的信息。实际上,如果一群研究对象进行长期的随访,就会出现许多对象失访的现象,导致研究数据出现缺失,在生存分析上称之为删失即CNSR变量。如果出现删失,表明患者虽然被观察一段时间,但是阳性结局未出现,但人丢了,我们无法得到该对象完整的生存时间。
何为删失数据
本质是缺失数据。在观察到阳性数据和随访结束前,由于①中途失访、②死于其它原因、③随访截止。导致只能提供部分可供于分析的数据。
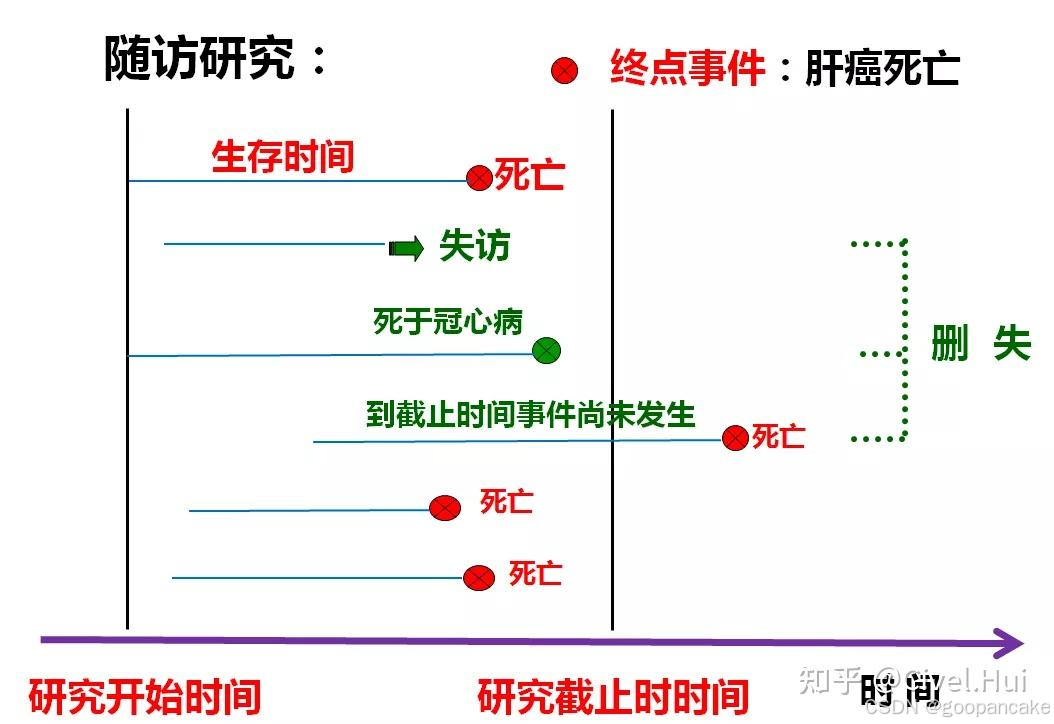
3. 生存分析的目的与方法
针对生存数据,核心目标便是评价一个群体的“死亡速度”,具体比较的是生存时间长短;此外,我们还可以分析由“死亡速度”产生的另外一个里程概念,“死亡”率或者“生存”率。(再次提醒,这里的生存与死亡不是狭义上的概念,而是是否出现阳性事件)。
**生存分析的主要目的就是研究与分析死亡速度、生存率(死亡率)、生存时间。**比如,有10名肝癌患者,三年内,第一年死亡4人,第二年死亡3人,第三年死亡1人。我们便可以计算年死亡速度,第一年死亡速度是40%(4/10),第二年为50.0%(3/6),第三年为33.3%(1/3);三年累计死亡率是80%,生存率为20%。当然也可以计算10名患者总的生存时间。
死亡速度的计算
t时刻存活的个体在t 时刻的瞬时死亡率。(仔细品品,这一概念不是有速度的味道)。具体可以用以下函数来表达:
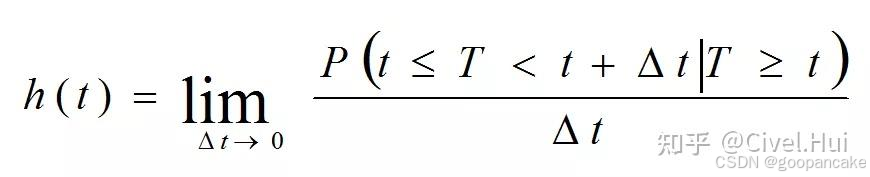
生存率的计算
生存率(survival rate):0 时刻存活的个体经历 t 时后仍存活的可能性,简写为S(t)。生存率根据死亡速度计算得到,这一概念的原理性和计算方式在这里就不再叙述(否则诸位真的看不懂生存分析了)。这一指标,临床上用的非常多,比如我们经常计算肺癌患者3年生存率、10年生存率;乳腺癌患者5年复发率等。研究者可以根据研究对象的生存结局出现的速度,来计算生存率。
生存时间的计算
生存时间的计算,最常见的采用中位生存时间来描述。中位生存时间(median survival time):也称半数生存期,是生存时间中位数,表示恰有50%的个体存活的时间,即生存率为50%时对应的生存时间,是描述集中趋势的指标。中位生存期越长,表示疾病的预后越好。
一般来说,一个群体的死亡速度一般都随时间的变化而变化。一般早期h(t)值较高,晚期较低。因此早期死亡率高,由此造成研究对象生存时间往往都是偏态分布,是正偏态分布。
二、应用部分
1. PROC LIFETEST
KM estimated DOR 代码如下(示例):
ods graphics on;
ods listing close;
ods trace on;*用于在log中查看输出了哪些数据集output,用于ods output中指定数据集label;
ods output
censoredsummary= survnum
survivalplot=survplot
productlimitestimates= survest
quartiles=survqtle;*该数据集中可获得中位生存时间和对应的置信区间;
proc lifetest data=final alpha=0.05;
time DURATION*EVENT(1);*1指定终点事件;
BY GROUP;*指定分组变量;
ods trace off;
ods graphics off;
ods listing;
2. KM plot作图
代码如下(示例):
proc template;
define statgraph stepplot;
begingraph/ designheight=400pt designwidth=600pt;
layout lattice/rows=2 columndatarange=union rowweights=(0.9,0.1);
layout overlay/
yaxisopts=(label="Survival Probability" linearopts=(viewmin=0 viewmax=1));
stepplot x=Time y=Survival/ group=TRT_Group name="step";
scatterplot x=Time y=Censored/ name="scat" legendlabel="Censored" markerattrs=(symbol=plus);
discretelegend "step"/location=inside halign=right valign=top across=1;
discretelegend "scat"/location=inside halign=left valign=bottom;
dropline x=Middle_Surv_Time y=0.5/dropto=x lineattrs=(pattern=dash);
dropline x=Middle_Surv_Time y=0.5/dropto=y lineattrs=(pattern=dash);
endlayout;
layout overlay/
yaxisopts=(display=none) xaxisopts=(display=none);
blockplot x=tAtRisk block=Atrisk/ datatransparancy=.3
valuefitpolicy=shrink labelposition=left display=(fill label outline values) class=TRT_Group
extendblockonmissing=ture;
endlayout;
endlayout;
endgraph;
run;
三、数据解读
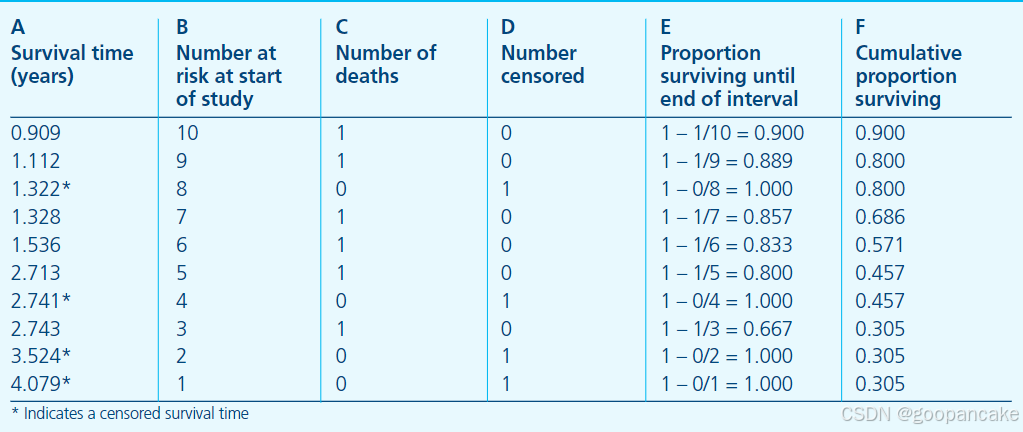
A 列是从试验开始起,持续的观测时间,星号代表在该时间有删失数据发生;B 列是指在 A 列对应的时间开始之前所有存活的研究对象个数,也可以叫做 at risk 的人数,表示当前具有死亡风险的有效人群,是排除了已经死亡和删失的数据之后剩余的人数;C 列为恰好在 A 列对应的时间死亡的人数,D 列即表明在该时间点删失的个数。 E 列即不死亡概率,F 列则表示累积的生存概率,可以看到随着时间增加,死亡人数增多,越到后期,生存概率越低,这是符合常理的。另外需要注意,在删失发生时,生存概率是没有变化的。
第一行则可以解读为,在 0.909 年这个时间点之前,本来有 10 个患者,在 0.909 这个时间点(或其之后的一小段时间区间)死亡了一个人,没有删失数据,意味着还剩 9 人;随后,只要有新增死亡或删失数据,则在表中新建一行,记录时间和人数。
计算每个时间节点的生存概率,即 S(t)。比如在 1.536 年这个时间点,即表中的第五行,病人在该点的生存概率是多少呢?很容易可以想到,要想在 1.536 这个时间点存活,他/她必须在 1.536 之前的所有时间点存活才行,也就是说在 0.909、1.112、1.322、1.328 这几个时间点,病人都必须存活。那么在 1.536 这个时间点的生存概率 P 实际上就等于在包括 1.536 在内的所有之前的时间点都不死亡的概率乘积,即:
P(存活至1.536) = P(0.909时不死亡) * P(1.112时不死亡) * P(1.322时不死亡) * P(1.328时不死亡) * P(1.536时不死亡)
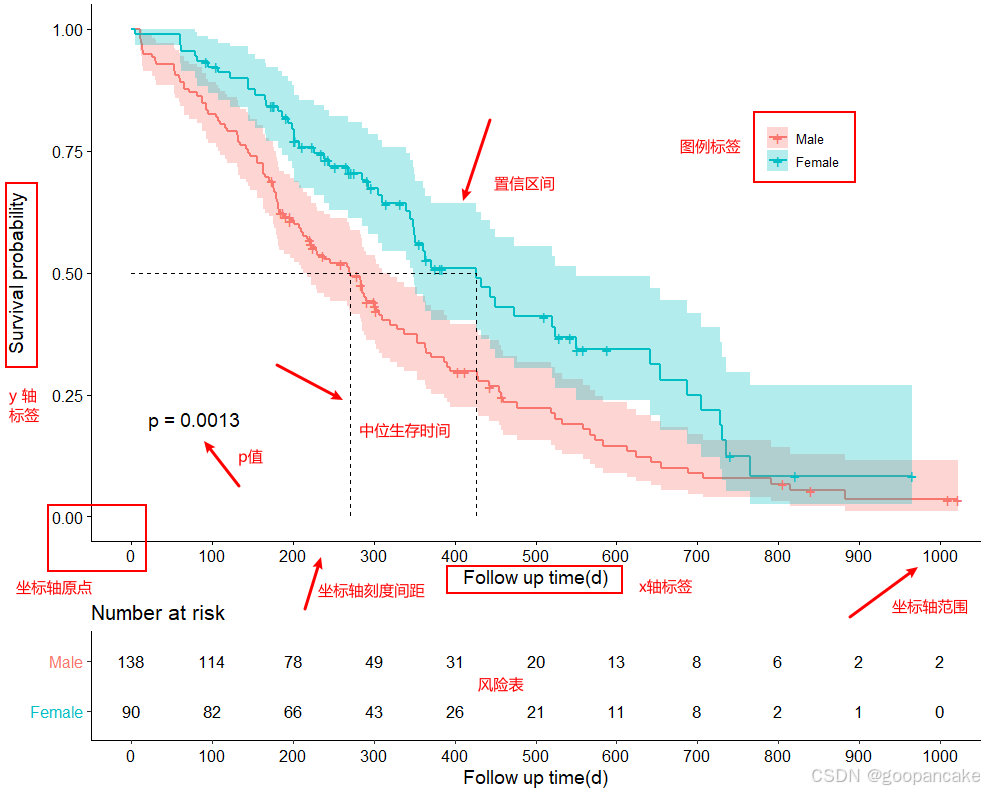
图中不同颜色表示不同的两组病人,在时间轴上生存情况的不同表现。后期蓝色线稍微高一些,说明蓝色组的后期生存概率更高,病人死亡的慢一些。图中+号表示该时点有病人删失,每次下降代表发生了目标终点事件。
四、相关阅读链接
生存分析简明教程
Life-Table Estimates for Males with Angina Pectoris
拓展阅读:
R语言统计与绘图:Kaplan-Meier生存曲线绘制
第二章 重复抽样
一、什么是重复抽样
重复抽样也称回置抽样。从总体 N 个单位中随机抽取一个容量为 n 的样本,每次从总体中抽取一个单位,把结果登记下来,又重新放回,参加下一次抽选。因而重复抽样的样本是由 n 次相互独立的抽选构成的,每次抽选是在完全相同的条件下进行的,每个单位中选的机会在各次都完全相等。
从总体 N 个单位中,用重复抽样的方法,随机抽取 n 个单位构成一个样本,则共可抽取 N^n个样本。
例如,总体有A、B、C、D 4个单位,要从中以重复抽样的方法抽取2个单位构成样本。先从4个单位中取1个,共有4种取法。结果登记后再放回,然后再从相同的4个中取1个,也有4种取法。前后取两个构成一个样本,全部可能抽取的样本数目为4×4=16个,它们是:
AA AB AC AD BA BB BC BD CA CB CC CD DA DB DC DD
不重复抽样也称为不回置抽样。从总体 N 个单位中抽取一个容量为 n 的样本,每次从总体中抽取一个单位,连续进行 n 次抽样构成一个样本,但每次抽取的一个单位都不再放回参加下一次的抽选。因而不重复抽样有这样的特点:样本由 n 次连续抽取的结果构成,实质上等于一次同时从总体中抽取 n 个样本单位,连续 n 次抽选的结果不是相互独立的,每次抽取的结果都影响下一次抽取,每抽取一次,总体单位数就少一个,因而每个单位的中选机会在各次是不同的。
从总体 N 个单位中,用不重复抽样的方法,抽取 n 个单位样本,全部可能抽取的样本数目为 N ( N -1)( N -2)…( N - n +1)个。
例如,从A、B、C、D 4个单位中,用不重复抽样的方法从中抽取2个单位构成样本。先从4个单位中取1个,共有4种取法,第二次再从留下的3个单位中取1个,共有3种取法,前后两个构成一个样本,全部可能抽取的样本数目为4×3=12个,它们是:
AB AC AD BA BC BD CA CB CD DA DB DC
二、应用部分
重复抽样代码如下(示例):
proc surveyselect data=aaa method=urs out=bbb
n=sample_size seed=12345 reps=replicates_number outhits;
run;
不重复抽样代码如下(示例):
proc surveyselect data=aaa method=srs out=bbb
n=sample_size seed=12345 reps=replicates_number;
run;
三、解读
此处不重复抽样用的是simple random sampling,如果method=置空则SRS是默认方法。
此处重复抽样用的是unrestricted random sampling,等概率有放回的选择样本,意味着一个样本可被抽选到多次。由于默认一次循环中重复抽选到的样本只保留单条记录,如果希望保留抽到的所有记录则选用outhits。
reps=语句可限定循环次数,在OUT=的数据集中,变量Replicate将会展示循环次数以区分每次循环选出的记录。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









