






最远点采样是三维点云分割中常用到的下采样方法,通过下采样更少点获取邻域点云块的更高维特征,丰富点云的特征提取。
原理:
设待处理点云块共有N个点,需从中采样M个点
先随机选定该待处理点云块中的一个点作为初始点i;
然后计算待处理点云中剩余N-1个点到该初始点i的距离,选择距离最远的那个点作为第二个点j,此时采样点云块M={i,j};
再计算待处理点云中剩余N-2个点到采样点云块M={i,j}的距离,比较N-2个距离,选距离最远的点作为采样点云块的第三个点;
(如何计算点到点集的距离?
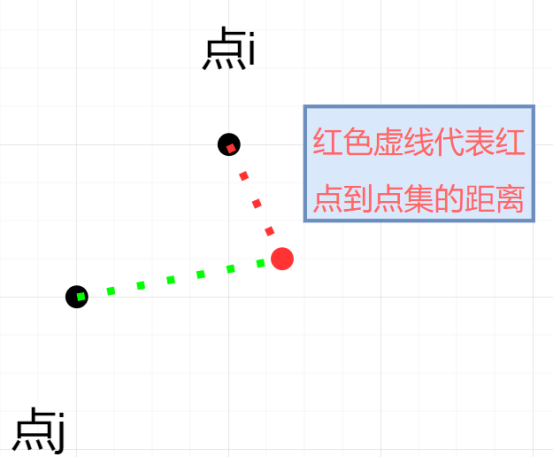
先计算该点到点集中每个点的距离,比较这些距离,最短的为点到点集的距离)
重复第3步,直到采样点云块中有M个点。
python实现:
def farthest_point_sample(xyz, M):
"""
Input:
xyz: pointcloud data, [B, N, 3]
M: number of samples
Return:
centroids: sampled pointcloud index, [B, M]采样点云索引
"""
device = xyz.device # cpu or cuda
B, N, C = xyz.shape
# 定义用来记录采样点索引的容器centroids:[B.M]
centroids = torch.zeros(B, M, dtype=torch.long).to(device)
# 定义记录xyz中每个点到采样点集的距离,初始值为很大的值distance:[B,N]
distance = torch.ones(B, N).to(device) * 1e10
# 随机生成B个0到N的整数,会作为对应batch的初始点索引。若batch_size=16,有16个点索引
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
# batch的序号,若batch_size=16,则batch_indices=(0,1,2,3,.....15)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(M):
# i=0时,将centroids的第一列变成随机生成的初始点索引
# i=1时,将centroids的第二列变成上次生成的初始点索引
centroids[:, i] = farthest
# 取到每个batch对应的初始点的xyz坐标[B,1,3]
# 取到每个batch对应的第二个点的xyz坐标[B,1,3]
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
# dist可计算xyz的所有点到centroid的距离
# 计算N个点到初始点的距离:[B,N]
# 其中[B,N,3]-[B,1,3]=[B,N,3],sum操作后为[B,N]
dist = torch.sum((xyz - centroid) ** 2, -1)
# mask是一个充满布尔值的张量:[B,N]
mask = dist < distance
# 更新距离(满足dist<distance就替换,根据点到点集的距离规定),
# 将满足条件的距离放入distance中:[B,N]
distance[mask] = dist[mask]
# 按distance[B,N]最后一个维度,每行的最大值对应的索引,farthest:[B,]
farthest = torch.max(distance, -1)[1]
return centroidstorch.sum([B,N,3],-1)处理后的张量变成[B,N]
torch.max(tensor,dim)可以返回最大值及其对应的索引,若tensor是二维的,dim=0每列最大值
torch.max([B,N],-1)得到每行的最大值,所以farthest:[B,]
mask = dist < distance
作用是计算原始点集中每个点到刷新后的采样点的距离,然后与上一次的作比较进行更新,这样避免了每一次循环都需要重复计算,大大减少了计算量。















 82
82











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









