






问题一采用遗传算法来解决作品评审分配问题。问题的描述是有一些专家和一些作
品,每个作品需要被
5
个专家评审。目标是找到一种评审分配方式,使得所有作品都被
5
个不同的专家评审,同时尽量减少交叉评审的情况。
源代码在文末给出
(1) 问题设置:
首先,设置问题的参数,包括专家人数、作品数量、每个作品被评 审的次数、种群数量、变异率、和迭代次数。
(2) 适应度函数:
定义一个适应度函数,这个函数用来评估评审分配的质量。适 应度函数的目标是尽量减少交叉评审的情况,因此采用了交集方差作为评估指 标。适应度函数计算了每对专家之间的评审作品的交集情况,并计算了这些交 集的方差。方差越小,表示交叉评审越少,评审分配质量越高。
(3) 初始化种群:
随机生成一个初始的评审分配种群,其中每个个体代表一种评审 分配方式。这些个体通过随机选择专家来评审每个作品,保证每个作品被 5
个 不同的专家评审。
(4) 交叉和变异操作:
使用遗传算法的交叉和变异操作来生成新的评审分配个体。交叉操作中,随机选择两个个体,并随机选择一个位置,将这两个个体在该位 置之后的部分进行交叉,生成一个新的个体。在变异操作中,随机选择一个个 体,随机选择一个位置,将该位置的列全部置为 0
,然后再随机选择
5
个位置, 将这些位置的值置为 1
。
(5) 选择操作:
通过计算适应度函数,选择出适应度较高的一半个体作为下一代种群 的父代。
(6) 迭代:
不断重复交叉、变异和选择操作,直到达到指定的迭代次数。
(7) 结果输出:
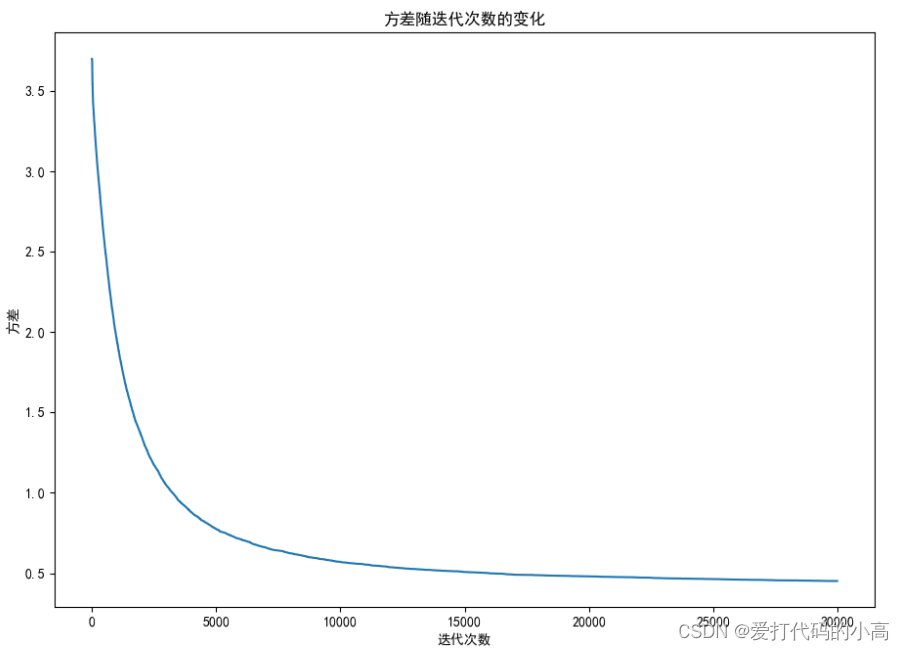
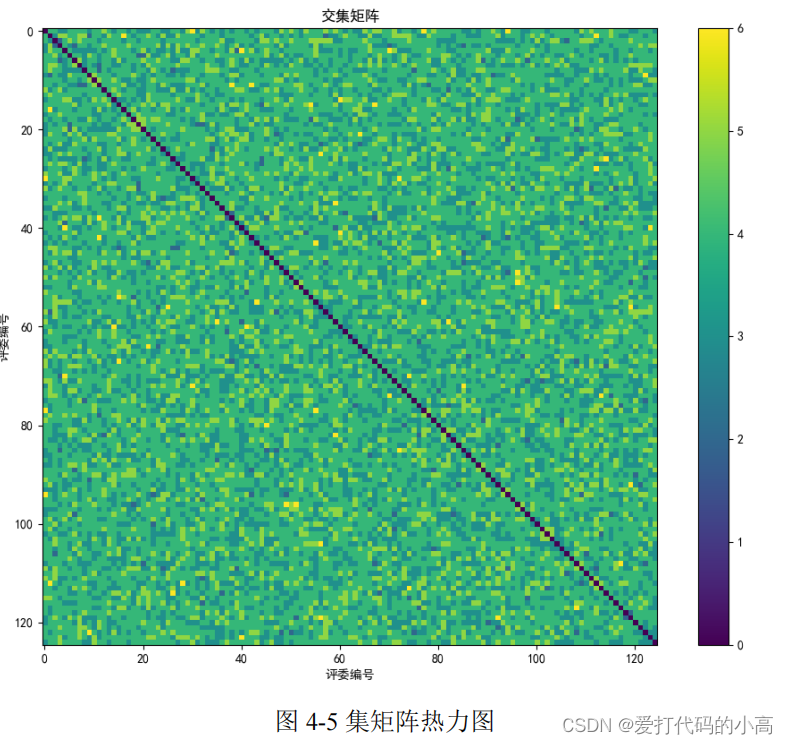
输出最佳评审分配矩阵和最小的交集方差,以及每个专家评审的作品 列表。还绘制了平均交集随迭代次数的变化图、方差随迭代次数的变化图以及最佳评审分配的交集矩阵。
总的思路是通过遗传算法不断优化评审分配方式,使得交叉评审尽量减少,以提高
评审分配的质量。
开始解题:
(1)
初始化种群:
首先,初始化一个包含多个评审分配个体的种群。对种群每个个体矩阵以这种方
式进行编号:
A_1,A_2,A_3…A_n(n = Num_popul)
其中
Num_popul
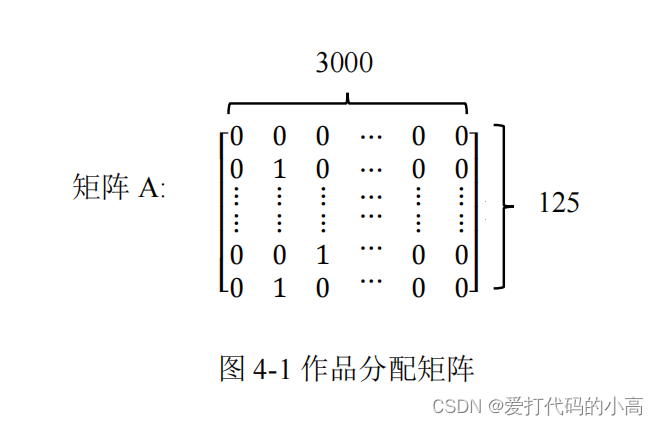
代表种群个体数。 每个评审分配个体都表示了一种专家对作品的评审分配方式。这些分配方式是随机 生成的。随机分配过程如下:初始化 n(n = Num_popul)
个分配矩阵,矩阵有
125
行, 3000 列,矩阵内的值代表某个专家是否对某个作品评审,例如
𝐴
11 12
= 1
代表第
11 个评委评审了作品编号为 12
的作品。图
4-1
为一个矩阵的样例。遍历每个个体矩阵 的每一列,在每一列中随机挑选 5
个不同的位置将值置为
1
。例如在第 i(i ≤ 3000
) 次遍历中,在[1
,
125]
这个范围内随机生成
5
个整数
[a, b, c, d, e, f]
,
代表第
i
个作品被编号为[a, b, c, d, e, f]
的专家评审。
(2)
适应度评估:
对种群中的每个评审分配个体,使用适应度函数来评估其质量。适应度函 数的目标是计算交集方差来评估评审分配的质量,最小化每两个专家评审作品 交集的方差。
计算每两个专家评审作品交集的方差需要对第一步生成的矩阵进一步处理。 见式子 5-1
式中
S
矩阵通过
A
矩阵乘
A
矩阵的转置得到的新矩阵
,
根据矩阵运算 规则易知矩阵 S
的大小为
(125
×
125),
存储的是每两个专家评审作品的交集。例 如𝑆
𝑖𝑗
(i, j< Num_Exp)
里的数字就代表的是第
i
个评委和第
j
个评委评审作品的 交集数量。
S = A × 𝐴 𝑇
式
4-1
求解出交集矩阵后还需要进一步处理,处理后再计算交集矩阵的平均值和 方差。在 S
矩阵中,第
i
行
i
列
(i < Num_Exp)
的元素的值为第
i
个评委与自身的 交集,等于他评审作品的数量,在实际问题中,这个值并无意义,所以将 S
矩 阵中的这个值置为 0
,也就是
S
矩阵的对角线元素置为
0
。见式
5-2
实现这一功 能,E
代表单位矩阵。
S = S − S × E
式
4-2
求解出交集矩阵之后就可以进行平均值和方差运算,由于S
𝑖𝑗
(i, j< Num_Exp) 代表的是第 i
个专家和第
j
个专家的评审作品交集
,
S
𝑗𝑖
(i, j< Num_Exp)
代表的是 第 j
个专家和第
i
个专家的评审作品交集易知
S
矩阵的上三角和下三角所对应的 值相同,所以只需要计算上三角的平均值和方差。这样操作还可以优化后续算 法的时间复杂度。平均值的计算见式 5-3
,方差的计算见式
5-4,
式中的
n
代表矩 阵的宽度等于专家人数。
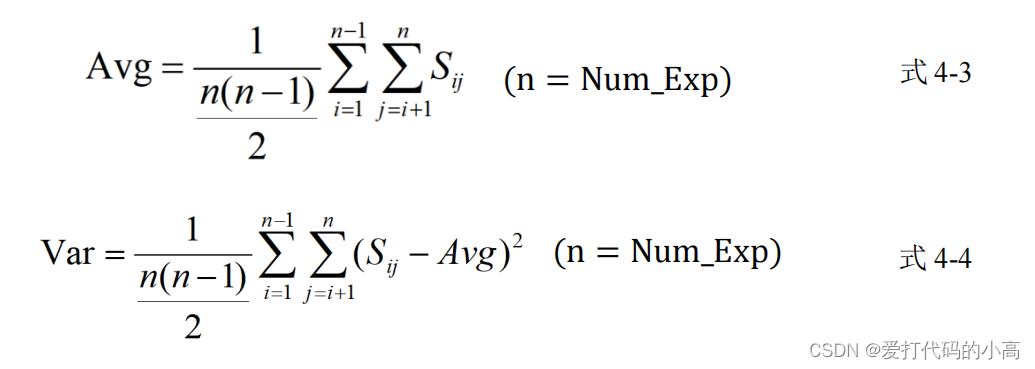
(3)
选择操作:
通过交叉操作选择一部分优秀的评审分配个体,繁殖下一代后进行选择操 作。选择操作是利用适应度函数比较生成孩子矩阵是否优于双亲矩阵,若优选 则择孩子矩阵进入新的种群,若非优则排除。
(4)
交叉操作:
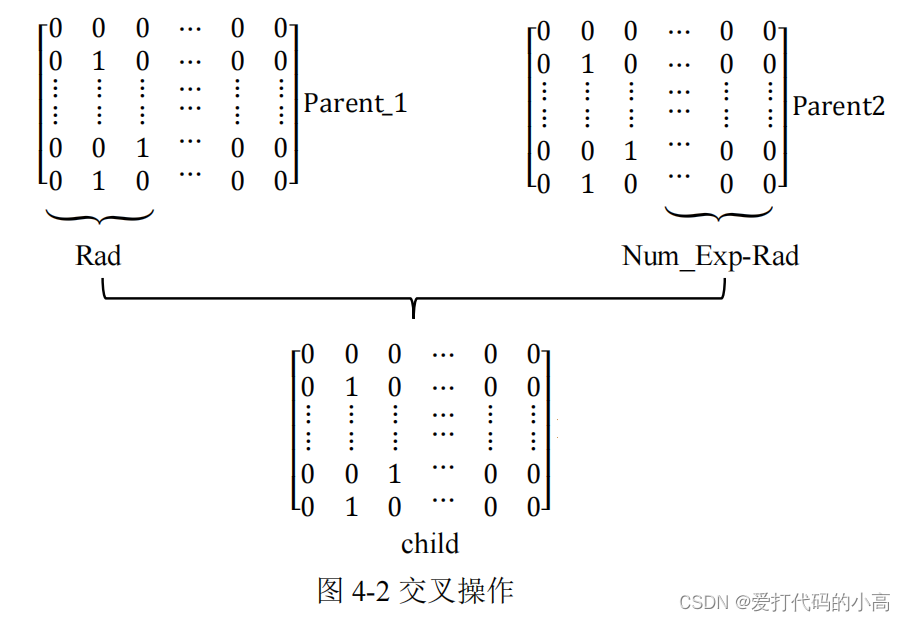
从个体中随机选择两个,进行交叉操作。交叉操作类似于基因组合,目的 是将两个评审分配个体的信息结合起来,生成一个新的个体,这样进行列的交 叉不会改变问题要求,生成的孩子矩阵具有和原矩阵相同的性质。首先从种群 数中随机选取两个编号作为两个父类矩阵 Parent_1
,
Parent_2
,再在
[1,125]
中随 机选择一个数作为断点对 Parent_1
,
Parent_2
进行切片组合生成一个孩子矩阵 child 见图
4-2
随机生成了一个数字
Rad
,截取
Parent_1
矩阵的前
Rad
列,
Parent_2 的后 Num_Exp-Rad
列。
(5)
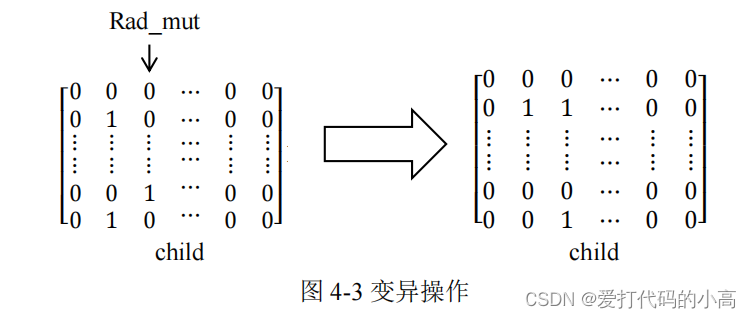
变异操作:
对新生成的 child
矩阵进行变异操作。变异操作的目的是引入多样性,以避 免陷入局部最优解。如图 4-3
在
[1,3000]
范围内随机生成一个整数
Rad_mut
作为 索引列,
将这一列的数字全置为
0
,在
[1
,
125]
这个范围内随机生成
5
个整数 [a, b, c, d, e, f]作为索引行,将矩阵相对应的行置为
1
。这个变异操作在实际问题 里对应的是重置某个作品的分配方案,重新选择 5
个专家进行评审。
(6)
生成下一代种群:
将选择、交叉和变异操作生成的新个体加入到种群中,形成下 一代种群。
(7)
重复迭代:
重复上述步骤,直到达到指定的迭代次数(或满足其他停止条件)。
(8)
输出结果:
在迭代结束后,输出最佳的评审分配矩阵,其中每个元素表示某个专 家是否评审某个作品。还输出最小的交集方差,以及平均交集随迭代次数的变 化。同时,输出每个专家评审的作品列表。
源代码:(使用时可以设置小问题规模和较小的迭代次数,可以很快运行方便查看结果)
import random
import time
import numpy as np
from matplotlib import pyplot as plt
random.seed(42)
# 设置问题参数
num_experts = 125 #专家人数
num_works = 3000 # 作品数量
num_reviews_per_work = 5 #作品要被5次评审
population_size = 100 #种群数量
mutation_rate = 0.5 # 变异率
num_generations = 30000 #迭代次数
# 定义适应度函数(交集方差)
def fitness(assignment):
intersection_matrix = np.dot(assignment, assignment.T)
np.fill_diagonal(intersection_matrix, 0)
average_intersections = [] #存储平均值,计算方差
for i in range(num_experts):
for j in range(i + 1, num_experts):
average_intersections.append(intersection_matrix[i][j])
average_intersections.append(intersection_matrix[j][i])
return np.var(average_intersections)
# 初始化种群
def initialize_population(population_size, num_experts, num_works):
population = []
for _ in range(population_size):
assignment = np.zeros((num_experts, num_works), dtype=int)
for team in range(num_works):
judges = random.sample(range(num_experts), num_reviews_per_work)
for judge in judges:
assignment[judge][team] = 1
population.append(assignment)
return population
# 交叉操作(随机选取列数进行交叉)
def crossover(parent1, parent2):
crossover_point = random.randint(0, num_works - 1)
child = np.hstack((parent1[:, :crossover_point], parent2[:, crossover_point:]))
return child
# 变异操作(随机将一列置为0,再随机选择该列的5个数置为1)
def mutate(assignment):
mutated_assignment = np.copy(assignment)
# 随机选择一列并将其所有元素置为0
col_to_zero = random.randint(0, num_works - 1)
mutated_assignment[:, col_to_zero] = 0
# 随机选择该列的5个位置将其值置为1
col_indices = list(range(num_experts)) # 该列的所有行索引
random.shuffle(col_indices) # 随机打乱行索引
for i in range(5):
row = col_indices[i]
mutated_assignment[row, col_to_zero] = 1
return mutated_assignment
# 遗传算法主循环
population = initialize_population(population_size, num_experts, num_works)
best_fitness = float('inf')
best_assignment = None
average_intersections = []
fitness_sector = []
for generation in range(num_generations):
# 评估种群中的每个个体
print("当前迭代次数",generation)
if(generation%100 == 0):
print(time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime()))
fitness_scores = [fitness(assignment) for assignment in population]
# 选择操作
selected_indices = np.argsort(fitness_scores)[:population_size // 2]
selected_population = [population[i] for i in selected_indices]
# 交叉和变异操作
new_population = selected_population.copy()
while len(new_population) < population_size:
parent1 = random.choice(selected_population)
parent2 = random.choice(selected_population)
child = crossover(parent1, parent2)
if random.random() < mutation_rate: # 添加小概率的变异
child = mutate(child)
new_population.append(child)
population = new_population
# 记录最佳评审分配
current_best_fitness = min(fitness_scores)
fitness_sector.append(current_best_fitness)
if current_best_fitness < best_fitness:
best_fitness = current_best_fitness
best_assignment = population[np.argmin(fitness_scores)]
# 计算平均交集并记录
intersection_matrix = np.dot(best_assignment, best_assignment.T)
np.fill_diagonal(intersection_matrix, 0)
sum_average = 0
for i in range(num_experts):
for j in range(i + 1, num_experts):
sum_average += intersection_matrix[i][j]
sum_average += intersection_matrix[j][i]
sum_average = sum_average / (num_experts * (num_experts - 1))
average_intersections.append(sum_average)
# 输出最佳评审分配和最小交集方差
print("最佳评审分配矩阵:")
print(best_assignment)
print("最小交集方差:", best_fitness)
print("平均交集:",average_intersections[-1])
for expert in range(num_experts):
reviewed_works = [work for work in range(num_works) if best_assignment[expert][work] == 1]
print(f"专家{expert + 1}评审的作品: {reviewed_works}")
# 绘制平均交集随迭代次数的变化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(range(num_generations), average_intersections)
plt.xlabel('迭代次数')
plt.ylabel('平均交集')
plt.title('平均交集随迭代次数的变化')
plt.show()
plt.plot(range(num_generations), fitness_sector)
plt.xlabel('迭代次数')
plt.ylabel('方差')
plt.title('方差随迭代次数的变化')
plt.show()
# 绘制最佳评审分配的交集矩阵
intersection_matrix = np.dot(best_assignment, best_assignment.T)
np.fill_diagonal(intersection_matrix, 0)
plt.imshow(intersection_matrix, cmap='viridis')
plt.colorbar()
plt.title('交集矩阵')
plt.xlabel('评委编号')
plt.ylabel('评委编号')
plt.show()
















 6542
6542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









