










C4.5算法
C4.5算法与ID3算法相似,但是对ID3算法进行了改进,C4.5在生成的过程中,用信息增益比准则来选择特征。那么,C4.5算法是如何做到的呢?请看下文:
修改局部最优化条件
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题,使用信息增益比(information gain ratio)可以对这一问题进行校正。
信息增益比定义为其信息增益与训练数据集关于某一特征的值的熵之比:
Gain_ratio(D,α)=
G
a
i
n
(
D
,
α
)
I
V
(
α
)
\frac{Gain(D,α)}{IV(α)}
IV(α)Gain(D,α)
其中
IV(α)=-
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
l
o
g
2
∣
D
v
∣
∣
D
∣
\sum_{v=1}^V\frac{|D^v|}{|D|}log_2\frac{|D^v|}{|D|}
∑v=1V∣D∣∣Dv∣log2∣D∣∣Dv∣
称为属性α的 "固有值“(intrinsic value)。属性α的可能取值越多(即V越大),则IV(α)的值通常会越大。例如,当取ID字段作为切分字段时,IV值为log2k。所以IV值会随着叶结点上样本量的变小而逐渐变大,也就是说一个特征属性中如果标签分类太多,每个叶子上的IV值就会非常大。
值得注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一种启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
我们可利用Gain_ratio代替Gain重新计算数据集中第0列的Gain_ratio,由于根据’accompany’字段切分后,2个分支分别有3个和2个的样例数据,因此其IV指标计算过程如下:

进而可计算’accompany’列的Gain_ratio:

然后可进一步计算其他各字段的Gain_ratio,并选取Gain_ratio最大的字段进行切分。
连续变量处理手段
在C4.5中,同样还增加了针对连续变量的处理手段。如果输入特征字段是连续型变量,则算法首先会对这一列数进行从小到大的排序,然后选取相邻的两个数的中间数作为切分数据集的备选点,若一个连续变量有N个值,则在C4.5的处理理过程中将产生N-1个备选切分点,并且每个切分点都代表着一种二叉树的切分方案,例如:

这里需要注意的是,此时针对连续变量的处理并非是将其转化为一个拥有N-1个分类水平的分类变量,而是将其转化成了N-1个二分方案,而在进行下一次的切分过程中,这N-1个方案都要单独带入考虑,其中每一个切分方案和一个离散变量的地位均相同(一个离散变量就是一个单独的多路切分方案)。例如,有如下数据集,数据集中只有两个字段,第一行代表年龄,是特征变量,第二行代表性别,是目标字段,则对年龄这一连续变量的切分方案如图所示:

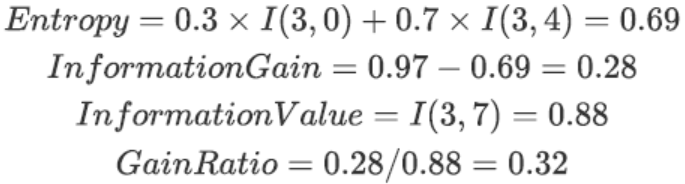
从上述论述能够看出,在对于包含连续变量的数据集进行树模型构建的过程中要消耗更多的运算资源。
但与此同时,当连续变量的某中间点参与到决策树的二分过程中,往往代表该点对于最终分类结果有较大影响,这也为连续变量的分箱压缩提供了指导性意见。例如,上述案例,若要对Age列列进行压缩,则可考虑使用36.5对其进行分箱,则分箱结果对于性别这一目标字段仍然具有较好的分类效果,这也是决策树的最常见用途之一,也是最重要的模型指导分箱的方法。














 4980
4980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









