







 基于信息增益率的决策树算法(C4.5)及其python实现信息增益率信息增益可以很好的度量特征信息量,但却在某些情况下有一些弊端,举一个例子说明。比如对于编号这个特征,我们知道一般编号值都是各不相同的,因此有多少个编号就需要分为多少类。由于每一个分类中只有一个编号值,即纯度已经最大,所以导致编号这个特征的信息增益最大,而实际上它并不是最优的特征,这样选择决策树也显然不具备泛化能力。这正是信息增益的一个弊端:对可取值数目较多的属性有所偏好。因为信息增益反映的是给定一个条件以后不确定性减少的程度,必然是
基于信息增益率的决策树算法(C4.5)及其python实现信息增益率信息增益可以很好的度量特征信息量,但却在某些情况下有一些弊端,举一个例子说明。比如对于编号这个特征,我们知道一般编号值都是各不相同的,因此有多少个编号就需要分为多少类。由于每一个分类中只有一个编号值,即纯度已经最大,所以导致编号这个特征的信息增益最大,而实际上它并不是最优的特征,这样选择决策树也显然不具备泛化能力。这正是信息增益的一个弊端:对可取值数目较多的属性有所偏好。因为信息增益反映的是给定一个条件以后不确定性减少的程度,必然是
基于信息增益率的决策树算法(C4.5)及其python实现
信息增益率
信息增益可以很好的度量特征信息量,但却在某些情况下有一些弊端,举一个例子说明。
比如对于编号这个特征,我们知道一般编号值都是各不相同的,因此有多少个编号就需要分为多少类。由于每一个分类中只有一个编号值,即纯度已经最大,所以导致编号这个特征的信息增益最大,而实际上它并不是最优的特征,这样选择决策树也显然不具备泛化能力。
这正是信息增益的一个弊端:对可取值数目较多的属性有所偏好。因为信息增益反映的是给定一个条件以后不确定性减少的程度,必然是分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大。
为了减少这种偏好带来的不利影响,“增益率” 这个指标诞生了。替代地,增益率通过引入一个被称作分裂信息(Split information)的项来惩罚取值较多的Feature,分裂信息用来衡量Feature分裂数据的广度和均匀性。增益率定义如下:
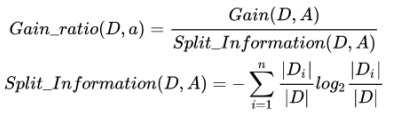
Gain_ratio(D,A):代表基于特征A的增益率。
Split_Information(D,A):代表对属性A信息增益的平衡项。也可以理解为特征A的一种内在属性。
因此,属性A的取值数目越多,平衡项的值越大,增益率也就越小,这也反映出增益率对取值数据较少的属性有所偏好。C4.5算法就是利用增益率来选择特征。
算法的python实现
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 30 11:17:53 2019
@author: Auser
"""
from math import log
import operator
import math
def cal_entropy(dataSet_train):#计算熵
#numEntries为训练集样本数
numEntries = len(dataSet_train)
labelCounts = {
}
for featVec in dataSet_train:#遍历训练样本
label = featVec[-1]#将每个训练样本的类别标签作为类别列表
if label not in labelCounts.keys():#如果一个训练样本的类别不在类别列表字典中
labelCounts[label] = 0#将该训练样本类别进行标记
labelCounts[label] += 1#否则,给类别字典对应的类别+1
entropy = 0.0#初始化香浓商
for key in labelCounts.keys():#遍历类别字典的每个类别
p_i = float(labelCounts[key]/numEntries)#计算每个类别的样本数占总的训练样本数的占比(即某一样本是类i的概率)
entropy -= p_i * log(p_i,2)#log(x,10)表示以10 为底的对数,计算香浓熵
return entropy
def split_data(dataSet_train,feature_index,value):#按照选出的最优的特征的特征值将训练集进行分裂,并将使用过的特征进行删除
'''
划分数据集,特征为离散值
feature_index:用于划分特征的列数,例如“年龄”
value:划分后的属性值:例如“青少年”
'''
data_split=[]#划分后的数据集
for feature in dataSet_train:#遍历训练集
if feature[feature_index]==value:#如果训练集的特征索引的值等于划分后的属性值
reFeature=feature[:feature_index]#删除使用过的特征
reFeature=list(reFeature)
reFeature.extend(feature[feature_index+1:])
data_split.append(reFeature)
return data_split
def split_countinue_data(dataSet_train,feature_index,value,direction):#特征为连续值
data_split=[]
for feature in dataSet_train:
if feature[feature_index]>value:
reFeature=feature[:feature_index]
reFeature=list(reFeature)
reFeature.extend(feature[feature_index+1:])
data_split.append(reFeature)
else:
if feature[feature_index]<=value:
reFeature=feature[:feature_index]
reFeature=list(reFeature)
reFeature.< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 551
551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









