







Abstract
①提出一个 风格引导的扩散模型(SGDiff),把 图像模态 与 预训练的t2i模型 组合起来。
②提出一个 数据集 SG-Fashion。
Method
SGDiff Overview
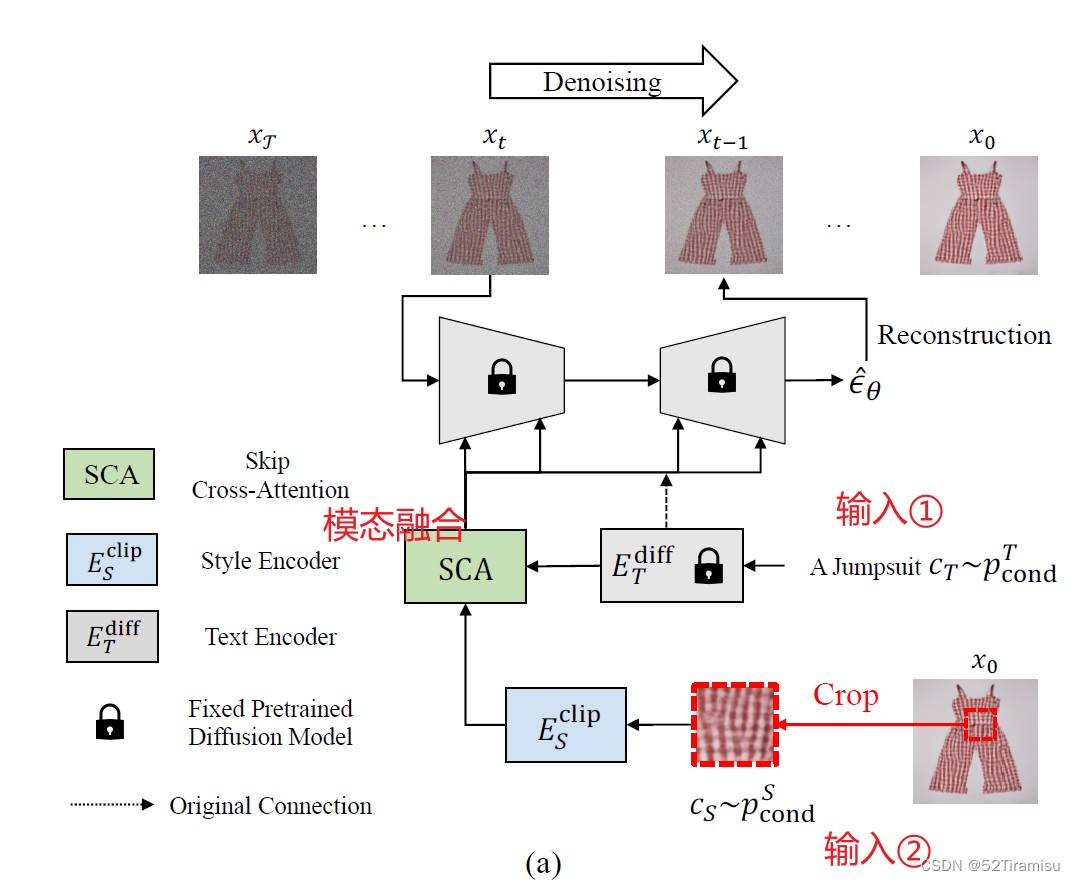

公式含义:在给定时间点 t 上的输入
,目标文本的语义表示
,风格表示
。通过扩散网络
估计该时刻的噪声
。
输入:①文本text;②风格图像。
文本条件 通过扩散模型的
生成
风格条件 通过CLIP模型的
生成
这两个特征在 SCA 模块中进行特征融合(融合细节如下图:)

:
:
再特征拼接:![]()
输出 :

最后再来一个 skip-connection:
Training Objective
从每一时间步骤t,获得重建图像

Perceptual Loss:
![]()
Perceptual Losses for Real-Time Style Transfer and Super-Resolution. 2016
,
分别表示 生成图像
和真实图像
在VGG网络的第 m 层的特征表示。
VGG网络,包含多个卷积层和池化层,用于提取图像特征。
最后基于 Improved DDPM,提出最终目标Loss:
![]()

Multi-Modal Conditions
Experiment
数据集:SG-Fashion,包含17,000 张从优衣库等网站上下载的各类图片。
模型架构:GLIDE+CLIP(ViT/32)
显卡:a single RTX3090
定性比较

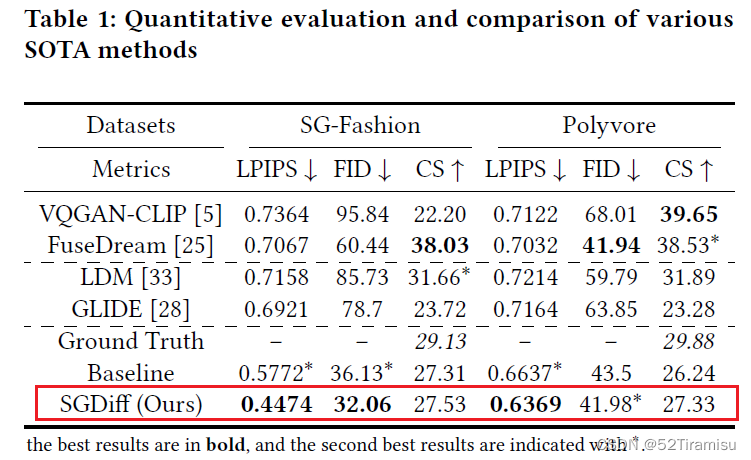
定量比较
收获
- 了解到【模态融合】相关知识;















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









