






本文针对 Hadoop Yarn 分布式计算平台的搭建与配置,提供从环境规划、核心配置到实战案例的全流程指南,适合大数据开发新手及运维人员快速上手。文中附完整命令清单与避坑技巧,可直接用于生产环境部署。
一、环境规划与准备
📌 集群节点规划(3 节点示例)
| 节点名称 | 角色定位 | IP 地址 |
|---|---|---|
| bigdata01 | NameNode+ResourceManager | 192.168.100.128 |
| bigdata02 | DataNode+NodeManager | 192.168.100.129 |
| bigdata03 | DataNode+NodeManager | 192.168.100.130 |
⚙️ 软件依赖
- Hadoop 3.3.6(已完成 HDFS 基础部署)
- JDK 1.8(需提前配置
JAVA_HOME环境变量) - 节点间 SSH 免密登录(用于远程管理)
二、核心配置步骤
1. 配置 hadoop-env.sh
vi /opt/installs/hadoop/etc/hadoop/hadoop-env.sh
# 添加以下内容(确保权限与路径正确)
export JAVA_HOME=/opt/installs/jdk # JDK安装路径
export HDFS_NAMENODE_USER=root # NameNode运行用户
export HDFS_DATANODE_USER=root # DataNode运行用户2. 获取并配置 classpath(避免 AppMaster 报错)

3. 配置 mapred-site.xml(指定计算引擎)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
指定mapreduce运行平台为yarn4. 配置 yarn-site.xml(资源管理核心)
<configuration>
<!-- ResourceManager主节点地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
<!-- NodeManager内存资源配置(根据节点硬件调整) -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value> <!-- 示例:8GB内存 -->
</property>
<!-- 启用MapReduce Shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>5. 分发配置文件到从节点
cd /opt/installs/hadoop/etc/hadoop/
xsync.sh mapred-site.xml yarn-site.xml启动和停止yarn平台:
启动: start-yarn.sh
停止: stop-yarn.sh 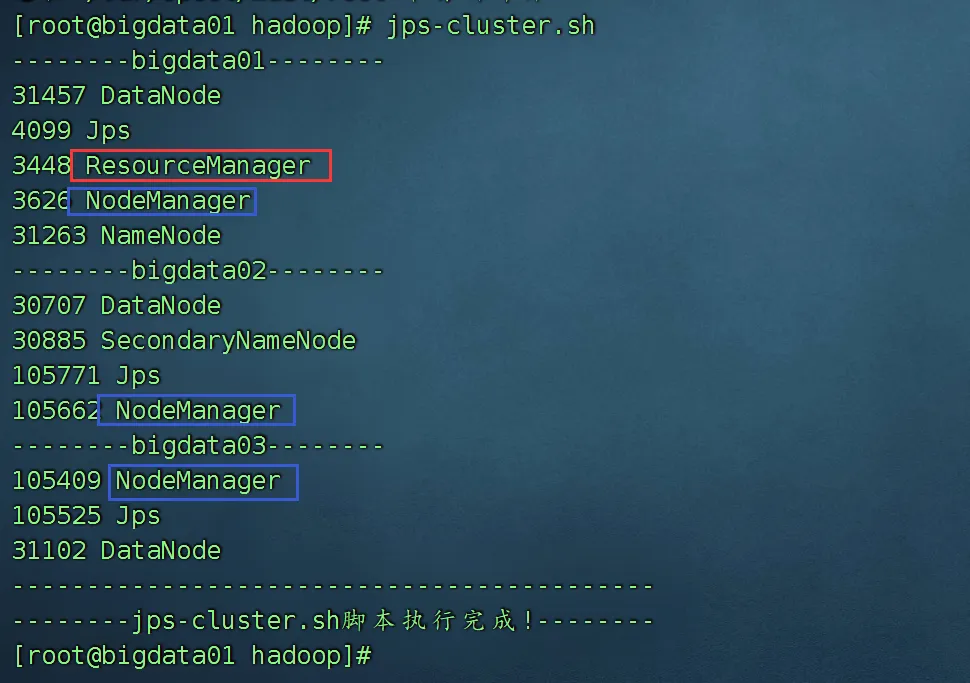
也可以使用web访问一下:
http://bigdata01:8088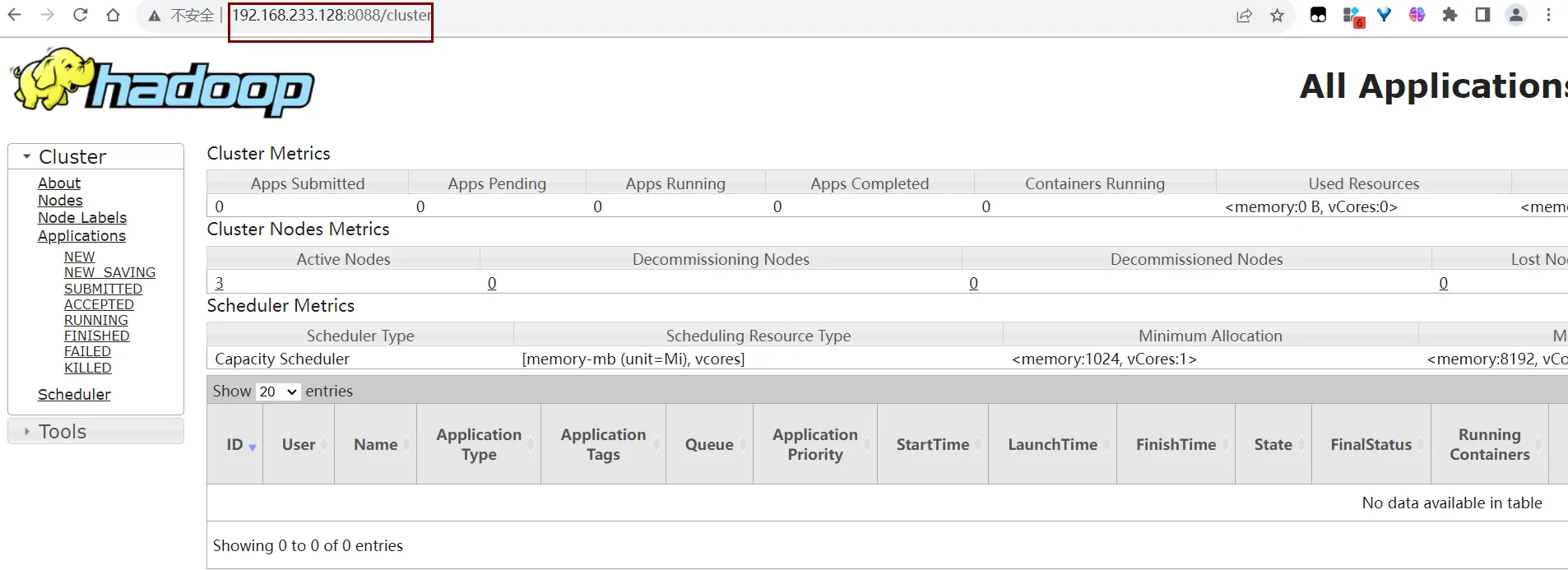
三、服务启动与停止命令速查表
| 操作场景 | 命令示例 | 说明 |
|---|---|---|
| 启动 HDFS | start-dfs.sh | 启动 namenode + datanode |
| 启动 Yarn | start-yarn.sh | 启动 ResourceManager + NodeManager |
| 停止全部服务 | stop-all.sh | 等价于 stop-dfs.sh + stop-yarn.sh |
| 单独重启 ResourceManager | yarn --daemon restart resourcemanager | 用于单节点服务修复 |
| 访问 Yarn Web 界面 | 浏览器打开 http://bigdata01:8088 | 监控资源使用与任务状态 |
四、实战案例:用 Yarn 运行 WordCount
1. 准备测试数据
# 本地创建测试文件
echo "hello hadoop hello yarn" > wc.txt
# 上传至HDFS
hdfs dfs -mkdir /home
hdfs dfs -put wc.txt /home 2. 提交 Yarn 计算任务
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /home/wc.txt /home/output 3. 查看计算结果
hdfs dfs -cat /home/output/part-r-00000
# 预期输出:hello 2 hadoop 1 yarn 1 4. 任务监控
通过 Yarn Web 界面查看任务进度:
- 应用列表:显示所有正在运行的作业
- 日志查看:点击任务 ID 获取详细日志
- 资源监控:实时查看 CPU / 内存使用情况
五、避坑指南:新手常见问题解决方案
1. 权限配置错误
- 报错现象:
Permission denied - 解决方法:
- 确认
hadoop-env.sh中用户配置正确(如root或指定用户) - 检查 HDFS 目录权限:
hdfs dfs -chmod -R 755 /home
- 确认
2. 端口占用冲突
- 报错现象:
ResourceManager failed to start - 解决方法:
-
lsof -i:8088 # 查看8088端口占用进程 kill -9 <PID> # 强制终止冲突进程3. 节点时间不同步
- 影响:导致心跳超时、任务调度失败
- 解决方法:
-
# 同步所有节点时间(以阿里云NTP为例) ntpdate time1.aliyun.com六、总结与扩展
Yarn 的搭建核心在于配置文件的准确性和集群节点的一致性。建议在正式部署前,先通过虚拟机环境进行测试,熟练掌握后再扩展到生产集群。
如需获取本文完整配置文件模板,可关注博主并留言 “YARN 搭建”,后续将更新《Yarn 资源调优实战》系列内容。欢迎在评论区分享搭建过程中遇到的问题,共同探讨大数据技术实践!

















 194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









