







回归分析
1. 数据准备
state.x77为car包中的内置数据,为美国50个州在1977年的控制人口(Population)、收入(Income)、文盲率(Illiteracy)、谋杀率(Murder)和结霜天数(Frost)等数据。想要研究影响谋杀率的主要因素。
library(car)
states <- as.data.frame(state.x77[,c("Murder","Population","Illiteracy","Income","Frost")])
2. 分析变量之间的关系
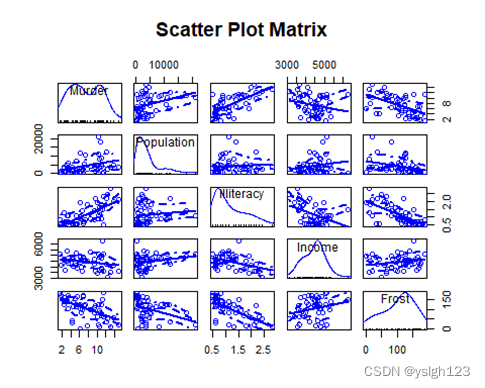
该步骤是为了查看变量之间的相关性,检查自变量之间是否存在共线性,若不存在共线性,则可以直接进行线性模型的拟合。若存在共线性,则考虑仅保留共线性高的变量中的一个。同时还可以查看因变量与哪个自变量相关性最高。如下所示,文盲率和谋杀率有较高的相关性。
cor(states) # 相关系数
## Murder Population Illiteracy Income Frost
## Murder 1.0000000 0.3436428 0.7029752 -0.2300776 -0.5388834
## Population 0.3436428 1.0000000 0.1076224 0.2082276 -0.3321525
## Illiteracy 0.7029752 0.1076224 1.0000000 -0.4370752 -0.6719470
## Income -0.2300776 0.2082276 -0.4370752 1.0000000 0.2262822
## Frost -0.5388834 -0.3321525 -0.6719470 0.2262822 1.0000000
scatterplotMatrix(states, main="Scatter Plot Matrix")
3. 多元线性回归
利用lm函数进行线性回归
model <- lm(Murder~Population+Illiteracy+Income+Frost,states)
summary(model)
## Call:
## lm(formula = Murder ~ Population + Illiteracy + Income + Frost,
## data = states)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.7960 -1.6495 -0.0811 1.4815 7.6210
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.235e+00 3.866e+00 0.319 0.7510
## Population 2.237e-04 9.052e-05 2.471 0.0173 *
## Illiteracy 4.143e+00 8.744e-01 4.738 2.19e-05 ***
## Income 6.442e-05 6.837e-04 0.094 0.9253
## Frost 5.813e-04 1.005e-02 0.058 0.9541
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.535 on 45 degrees of freedom
## Multiple R-squared: 0.567, Adjusted R-squared: 0.5285
## F-statistic: 14.73 on 4 and 45 DF, p-value: 9.133e-08
结果显示illiteracy变量极显著,系数为4.14,表明控制人口、收入和温度不变时,文盲率上升1%,谋杀率将会上升4.14%。控制人口也显著。
4. 有交互作用的多元线性回归
变量之间可能存在着相互影响的情况,称为交互作用。当交互作用显著时,则说明这两个变量相互作用的结果有显著效应。两变量各自的效应则难以判断。mtcars数据中mpg为每加仑英里数,hp为马力,wt为车的重量。
data(mtcars)
fit <- lm(mpg ~ hp + wt + hp:wt, data=mtcars 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2303
2303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









