







条件随机场(conditional random filed, CRF)是深度学习算法运用于文本序列标注任务前,性能最优异的相关技术之一。即使在深度学习时代,将CRF层接于底层编码层之上仍是序列标注任务的baseline之一。
CRF++是CRF算法的实现,虽然在深度学习时代的使用面有所减少,但作为经典工具仍值得了解其基本用法。
0. 工具安装
CRF++工具包以及本文案例所使用的【人民日报】标注语料的下载请戳链接,提取码:egs1
压缩平台内包含适用于windows平台的包和linux平台的tar包。使用要求点电脑具有C++ compiler (gcc 3.0 or higher)。
windows平台可直接使用,而linux平台需安装:
1.解压安装包:tar –xvzf 软件包名
2.cd 进入解压后的目录,执行‘./configure’命令为编译做好准备
3.执行“make”命令进行软件编译
4.执行“make install”完成安装 (注意:需先执行“su”获取root用户权限)
5.执行“make clean”删除安装时产生的临时文件(可不执行)
安装成功后,文件共包含如下文件:
- doc文件夹:就是官方主页的内容。
- example文件夹:有四个任务的训练数据、测试数据和模板文件。
- sdk文件夹:CRF++的头文件和静态链接库。
- crf_learn.exe:CRF++的训练程序。
- crf_test.exe:CRF++的预测程序
- libcrfpp.dll:训练程序和预测程序需要使用的静态链接库。
在具体训练和测试使用时候真正需要使用的是crf_learn.exe,crf_test.exe和libcrfpp.dll,这三个文件。*也就是说,我们需要将这三个文件拷贝到任务文件夹下,并在任务文件夹下执行相关命令行,才能有效。
1. 训练阶段
1.1 语料准备
标注的训练语料以及测试语料的格式满足conll格式,即每行为token以及标注,每列间用\t分隔,最后一列为我们的预测目标,每个句子间用\n分割。
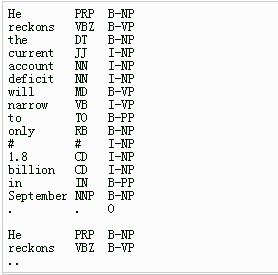
对于原始语料,必须将其严格转换为conll格式才能顺利训练和测试。以【人民日报】语料为例,可通过如下的预处理过程:
home_dir = "./"
def splitWord(words):
uni = words
li = list()
for u in uni:
li.append(u)
return li
# 4 tag
# S/B/E/M
def get4Tag(li):
length = len(li)
# print length
if length == 1:
return ['S']
elif length == 2:
return ['B', 'E']
elif length > 2:
li = list()
li.append('B')
for i in range(0, length - 2):
li.append('M')
li.append('E')
return li
# 6 tag
# S/B/E/M/M1/M2
def get6Tag(li):
length = len(li)
# print length
if length == 1:
return ['S']
elif length == 2:
return ['B', 'E']
elif length == 3:
return ['B', 'M', 'E']
elif length == 4:
return ['B', 'M1', 'M', 'E']
elif length == 5:
return ['B', 'M1', 'M2', 'M', 'E']
elif length > 5:
li = list()
li.append('B')
li.append('M1')
li.append('M2')
for i in range(0, length - 4):
li.append('M')
li.append('E')
return li
def saveDataFile(trainobj, testobj, isTest, word, handle, tag):
if isTest:
saveTrainFile(testobj, word, handle, tag)
else:
saveTrainFile(trainobj, word, handle, tag)
def saveTrainFile(fiobj, word, handle, tag):
if len(word) > 0:
wordli = splitWord(word)
if tag == '4':
tagli = get4Tag(wordli)
if tag == '6':
tagli = get6Tag(wordli)
for i in range(0, len(wordli)):
w = wordli[i]
h = handle
t = tagli[i]
fiobj.write(w + '\t' + h + '\t' + t + '\n')
else:
# print 'New line'
fiobj.write('\n')
# B,M,M1,M2,M3,E,S
def convertTag(tag):
fiobj = open(home_dir + 'people-daily.txt', 'r', encoding='utf-8')
trainobj = open(home_dir + tag + '.train.data', 'w', encoding='utf-8')
testobj = open(home_dir + tag + '.test.data', 'w', encoding='utf-8')
arr = fiobj.readlines()
i = 0
for a in arr:
i += 1
a = a.strip('\r\n\t ')
if a == "": continue
words = a.split(" ")
test = False
if i % 10 == 0:
test = True
for word in words:
# print "---->", word
word = word.strip('\t ')
if len(word) > 0:
i1 = word.find('[')
if i1 >= 0:
word = word[i1 + 1:]
i2 = word.find(']')
if i2 > 0:
w = word[:i2]
word_hand = word.split('/')
# print "----",word
w, h = word_hand
# print w,h
if h == 'nr': # ren min
# print 'NR',w
if w.find('·') >= 0:
tmpArr = w.split('·')
for tmp in tmpArr:
saveDataFile(trainobj, testobj, test, tmp, h, tag)
continue
if h != 'm':
saveDataFile(trainobj, testobj, test, w, h, tag)
if h == 'w':
saveDataFile(trainobj, testobj, test, "", "", tag) # split
trainobj.flush()
testobj.flush()
1.2 特征模板准备
CRF++采用的是线性链条件随机场,其特征包括状态特征函数 s l ( y i , x , i ) s_l(y_i,x,i) sl(yi,x,i)和转移特征函数 t k ( y i − 1 , y i , x , i ) t_k(y_{i-1},y_i,x,i) tk(yi−1,yi,x,i)。不同于深度学习模型通过定义CNNs、RNNs等Encoder自动提取特征,在CRF++需要手动定义相关的特征,即特征模板。
与线性链条件随机场的两类特征函数对应,在特征模板中可以定义Unigram和Bigram模板。其基本格式为%x[row, col]。方括号里的编号用于标定特征来源,row表示相对当前位置的行,0即是当前行;col对应训练文件中的列。
对于Unigram模板,每一行模板生成一组状态特征函数,数量是L*N 个,L是标签状态数。N是此行模板在训练集上展开后的唯一样本数。
对于Bnigram模板,每一行模板也会生成一组状态特征函数,区别在于其会多一个上节点标签 y i − 1 y_{i-1} yi−1参数,因此数量是L*L*N 个。
不熟悉CRF基本原理的朋友可戳示例。
以【人民日报】语料为例,可设定如下的模板:
# Unigram
U00:%x[-1,0]
U01:%x[0,0]
U02:%x[1,0]
U03:%x[-1,0]/%x[0,0]
U04:%x[0,0]/%x[1,0]
U05:%x[-1,0]/%x[1,0]
U10:%x[-2,1]
U11:%x[-1,1]
U12:%x[0,1]
U13:%x[1,1]
U14:%x[2,1]
U15:%x[-2,1]/%x[-1,1]
U16:%x[-1,1]/%x[0,1]
U17:%x[0,1]/%x[1,1]
U18:%x[1,1]/%x[2,1]
U20:%x[-2,1]/%x[-1,1]/%x[0,1]
U21:%x[-1,1]/%x[0,1]/%x[1,1]
U22:%x[0,1]/%x[1,1]/%x[2,1]
# Bigram
B
1.3 命令行训练
准备好conll格式化的语料文件以及模板文件template后,在同目录下准备好crf_learn.exe,crf_test.exe和libcrfpp.dll三份文件,即可开始训练:
crf_learn <特征模板文件> <语料文件> <模型存储文件>
可以配置如下的训练参数:
可选参数
-f, –freq=INT使用属性的出现次数不少于INT(默认为1)
-m, –maxiter=INT设置INT为LBFGS的最大迭代次数 (默认10k)
-c, –cost=FLOAT 设置FLOAT为代价参数,过大会过度拟合 (默认1.0)
-e, –eta=FLOAT设置终止标准FLOAT(默认0.0001)
-C, –convert将文本模式转为二进制模式
-t, –textmodel为调试建立文本模型文件
-a, –algorithm=(CRF|MIRA)
选择训练算法,默认为CRF-L2
-p, –thread=INT线程数(默认1),利用多个CPU减少训练时间
-H, –shrinking-size=INT
设置INT为最适宜的跌代变量次数 (默认20)
-v, –version显示版本号并退出
-h, –help显示帮助并退出
训练过程中shell会输出训练信息:
iter:迭代次数。当迭代次数达到maxiter时,迭代终止
terr:标记错误率
serr:句子错误率
obj:当前对象的值。当这个值收敛到一个确定值的时候,训练完成
diff:与上一个对象值之间的相对差。当此值低于eta时,训练完成
在训练开始前,需要特别注意语料文件和特征模板文件的编码格式均为utf-8,同时语料文件满足conll格式,特征模板文件中的特征定义合理合法。
2. 预测阶段
模型训练完成后,就可以开始预测了:
crf_test -m <模型存储文件> <预测语料文件> > <预测结果输出文件>
【Reference】















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









