







互联网广告系统综述六模型
声明:
1)该博文是整理自网上很大牛和专家所无私奉献的资料的。具体引用的资料请看参考文献。具体的版本声明也参考原文献
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应,更有些部分本来就是直接从其他博客复制过来的。如果某部分不小心侵犯了大家的利益,还望海涵,并联系老衲删除或修改,直到相关人士满意为止。
3)本人才疏学浅,整理总结的时候难免出错,还望各位前辈不吝指正,谢谢。
4)阅读本文需要互联网广告业的基础(如果没有也没关系了,没有就看看,当做跟同学们吹牛的本钱)。
5)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。请直接回帖,本人来想办法处理。
经过几个博文的啰啰嗦嗦,又是业务又是定向又是系统架构的,给各位的感觉都是在描述一些外围的东西,真正核心的东西还没说到。对于心急得如干柴烈火的热血青年来说,似乎一直在各种前戏,一直没感受到提抢上阵的快感。
就算这么急,这还是得说——在广告算法领域,如果说ctr预估是包子馅的话,前面那些东西就是包子皮,直接吃包子馅,不见得是很正确的吃法。
下面就说说大家喜闻乐见的模型吧。
1.1准确估计ctr的意义
得从前面的算分排序那一节说起了。
对于一些大型媒体行业平台,当时就说了ctr的估算要求比较准确,这ctr估高了,会把出价不高同时用户也不喜欢的广告的分算得比较高,这样的广告就排在了前面,这样广告平台既收不到钱,也讨不到用户喜欢;但ctr估低了,出价一般高但是用户比较喜欢的广告的分算得比较低,没机会投出去,用户就会总是看到不喜欢的广告,对媒体来说,这个最终也会导致用户的流失,照样赔了夫人又折兵。
对于广告生态圈中的DSP来说,同样DSP需要评估流量质量,如果发现一个流量的质量很高,就开高价去竟争这个流量;如果流量质量低,就开低价去竟争。如果评估得太高,出很高的价钱拿到了质量很低的流量,那就达不到广告主的要求,会亏钱;如果评估得太低,一直拿不到流量,没办法赚钱。评估流量质量,说到底了是预估一个流量的ctr。
说到这份上,总该明白一个问题了吧——估准ctr非常重要。这个就是广告算法工程师的工作的重中之重。
用另一个方式理解ctr,就是一个用户点击某一个广告的概率,点击的概率大,意味着越喜欢这个广告,用户越喜欢的广告,广告的质量自然可以认为是比较高的。
怎么算是估准了呢?举个例子,假如1万个人对同一个广告预估了1w个ctr的值,ctr的值当然有高有低了,如果这1w个人点击这个广告总共100次的话,同样也希望这1w个值的累加大致是100,这样才算估准了。但是,但是要注意的是,在这1w个值里面,那100个点击的人估算的值要明显比不点击的人要高,这就叫分开了,这才算是估得比较好的,如果人人都是大致0.01的话,也可以算是比较好的预估(因为跟真实的很接近),但是就没那么具备区分能力了,在有些业务下面,就不容易发挥更多的用处。
要估准ctr的意义说完了,就开始谈谈模型了。
1.2为啥要模型
预估一个人对一个广告的ctr,不可能是一个广告算法工程师在那里看着,来一个广告请求就估计一下,给个决定,这样人累死,估计得也乱七八糟,还效率不高,一天撑死了估计个几十万个请求,不得了了。
只能用机器来估,但是机器是很笨的,只能进行简单的规则运算,这些规则还必须提前指定。如果人工指定这些规则,如30岁用户点击匹克篮球的广告概率是多少,男性的用户点击匹克篮球的广告的概率是多少,年龄和性别在总的ctr预估里面占多少比重等等,需要大量的先验知识,而且还不能根据实际情况变化,往往有问题。而且规则往往是有组合的。这个方法比用人估计好很多了,但还是很原始。
这时候数学家们就来劲了,直接看和简单规则不行,复杂规则可以啊,而且复杂的规则可以用函数来拟合啊,而且上面的那些规则都可以用统计方法得到,用函数把他们组合起来也可以啊。
数学方法就这样引进来了。
有两个相关的方面,一个是统计方法;另一个就是拟合一个函数去组合规则,这个函数就是模型。
用数学的方式来表示对点击率的预估,做的工作可以用下面的图来描述。

统计方法怎么用呢?如可以统计过去投放过的记录中,30岁的用户点击匹克篮球的广告的点击率是多少,这个数据直接就能根据投放日志统计出来;再统计男性的用户点击匹克篮球的广告的点击率是多少,这样前面的两个东西就得到了。
但是知道这两个点击率,可以认为是两个规则;但这还不够,还需要知道这两个点击率在评估这个人点击匹克篮球的广告的概率中分别起什么作用,这就是规则的组合。这两个点击率加起来不行,相减也是不行的,加权累加可能是一种办法,但是这样行吗?还有怎么加权呢?用一个函数去组合这些规则就是很好的解决方案。为了描述的方便,我们用数学的方法来描述这两个规则,把这两个点击率(也就是规则)称为特征,用一个向量x=(x1,x2)来统一表示,其中x1表示30岁的用户对匹克篮球的广告的点击率,x2男性的用户对匹克篮球的广告的点击率。
问题就转变成了利用一个函数把向量x转变成用户对匹克广告的ctr了。这个函数就是模型,用数学的方法来描述就是完成上面的图中函数f的形式,这个函数f的形式确定了,就有了ctr=f(x)。
可以看到的是,利用模型是避免了人工规则扩展的困难,也使得每个ctr的计算变得可以用机器经过一些计算就可以完成,从而达到互联网在线服务的标准。
在传统领域也有些广告主利用先验知识做ctr预估的,就像是派传单,也要先看看哪个路人更容易接才派出去的;又比如化妆品促销活动,活动大使们肯定是找街上的一些女生来参加他们的活动,只有女生才更可能乐意参加他们的活动,这些都是一些ctr预估活动在起着作用,但是这个是人用了自己强大的大脑和先验知识来完成的,互联网在线服务要求并发高,务必要估得多而且快。想象一下行人密集得像地铁里面一样,而且都是百米冲刺的速度从派传单小哥或者活动大使面前经过,他们还怎么做生意?
所以模型加上人和广告对的向量表示,才能完成互联网的高并发与高速度的需要。
1.3用什么模型
上面说到了那个函数f就是模型,由于它的工作很复杂,那么形式应该是很复杂的,但是太复杂的模型不利于扩展,就用简单的形式来。经过工业界长期的工作,认为下面的形式是比较有效的。
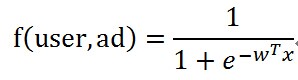
其中x是上面的那个x,w也是一个向量,表示的是x的每个特征的权重。这个w每取一个值,对相同的user和ad对就能得到一个预估的ctr,在f的形式已经确定的情况下w也可以称为是模型,因为它能根据x的取值,也就是特征的取值来决定ctr,也就是,f的形式主要是由w来确定的。
那么w这个向量的每个特征取值就变得很重要了,这个w的每个特征的值也可以由人工指定,但是上面说过了,需要大量的先验知识,而且特征会特别多,如上面还有地域,职业,学校什么的,可以搞到成千上万的特征,人工指定没办法做到周全。所以这个权重的是要用一些方法来让机器自己学习到的,这个过程称为训练,这个训练过程还不能只根据一个记录user和ad对来训练,要根据很多对来训练。每个展示记录就是一个对,根据历史的一段时间内的展示记录,能有很多的数据对可以进行训练。
说到了训练要用很多数据,但是这样说不够数学化,机器也做不了。只有把训练描述成一个数学问题的形式,机器才能接受。
很多年前最优化课程的老师说过,所有的问题都可以转化成一个最优化问题,当时听不懂也不知道为啥,现在才明白,计算机时代都只能这么来的,问题就是怎么构建那个最优化问题,就是几乎所有的算法工程师的工作,各种大牛们发表的paper都可以总结成在构建什么样的问题和怎么解这个问题。
现在有待解决的事情就是把权重向量w的每个特征的计算出来,拥有的条件是一大堆的x和这个x对应的用户的反馈:点击或者不点击。
1.3模型求解
上面描述了函数f的形式,以及权重向量w的意义,模型求解的意思就是把权重向量w的每个特征的计算出来,能依赖东西只有一大堆的x和这个x对应的用户的反馈。
数学家们也对这样的问题有了很好的办法。且看怎么构建一个最优化问题。
数学家认为总体的历史展示与点击数据符合一个伯努利分布,训练过程称为是拟合这个分布的过程。一次广告的展示是否被点击(每次展示被点击的概率可能不一样)是一个伯努利试验,用户点击这个广告表示伯努利试验成功,否则表示伯努利试验失败;对多个用户展示多个广告的过程是一个伯努利过程,每次伯努利试验成功的概率就是上面的f(user,ad)的值。为了方便描述,改变一下f的写法,用下面的方式表示
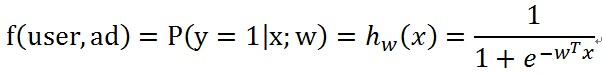
其中y=1表示这个展示被点击了,y=0表示这个展示没有被点击。
到这个时候,就要出动极大似然估计了。极大似然估计的意思是已经出现的情况,发生的概率是最大的。怎么理解呢?三个人去打靶,打中的概率分别是p1、p2、p3。用二进制的方式表示是否打中,如010表示中间那个人打中,那么可能会发生8种情况:000,001,010,011,100,101,110,111。这8种情况发生的概率分别是(1-p1)*(1-p2)*(1-p3),(1-p1)*(1-p2)*(p3), (1-p1)*(p2)*(1-p3), (1-p1)*(p2)*(p3), (p1)*(1-p2)*(1-p3), (p1)*(1-p2)*(p3),(p1)*(p2)*(1-p3), (p1)*(p2)*(p3)。假如这8个概率中p1*(1-p2)*(1-p3)最大,让人去预估打靶的结果,各位都应该认为是100这种情况,因为最符合常识的。
极大似然就是把这种情况反过来用了,意思是:打靶的结果是100这样的情况,但是p1、p2、p3还在估计中,那么无论p1、p2、p3估计出来什么值,都要保证p1*(1-p2)*(1-p3)最大。
那么在上面这种情况下,很自然地用极大似然构建最优化问题了。用似然函数表示上面的那个伯努利试验过程,得到整个伯努利试验的似然函数(也就是事情发生的联合概率)
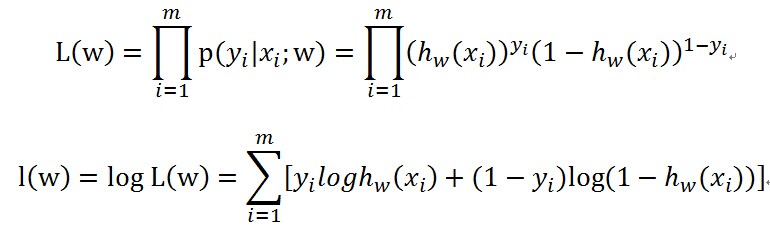
下面的那个式子是对数似然,是为了方便计算加上的。
回到打靶的那个说法,要保证已经发生的事件那个概率最大,在这里就变成让似然函数取得最大值了,这样最优化问题的优化目标就有了,就是求似然函数的最大值,刚好每个x对应的h(x)都带着w,那么就可以把w当成要求解的变量。
就这样,优化目标有了,要求解的变量有了,整个最优化问题就建立了。
有人可能会注意到有可能同一个x(特征完全相同)的情况下可能会出现两个不同的点击结果(一次点击,一次不点击),这个情况就类似抛硬币一样,假如这个硬币正面向上的概率是0.6,抛出去,依然会有若干次会反面朝上。
这个会不会影响模型的构建呢?这时候就该统计分布的知识出马了,注意极大似然的目标依然是进行分布的拟合,算的依然是概率,一个事件的发生是按照概率来判断的,极大似然估计计算的依据其实是概率,而不是某一次伯努利试验是否成功,所以对于模型的构建来说是没有问题的。哪怕这个问题推到极致,所有x都一样,那么得到的结果就是h(x)刚好接近总体点击率,这依然是一个好的模型,只是,可能用其他方法也能得到同样的结果罢了。
拟合分布跟计算一个分类器(判别模型的决策面)不一样,对于一些构建分类决策面的模型来说,如果同一个向量同时落在决策面的两边,有可能会让模型的训练变得有问题。这个问题等具体想清楚了,再来解释。
剩下的就是求解的方法了,这个就是最优化的知识了,具体可以看其他博文。
这整个问题就是logisticregression的问题构建和求解过程。有关logistic regression,很多大神都刷了无数博文了,就不多献丑了。
1.3.1正则化
正则化是一个机器学习通用的技术,目的是让w的每一个特征都不能太大,同时保证整个w所有特征都的绝对值都不特别大,总的来说就是避免产生特别不好的模型。
加完L2正则的优化目标如下
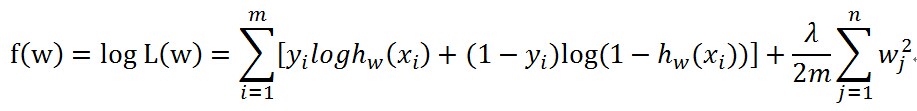
加完L1正则的优化目标如下
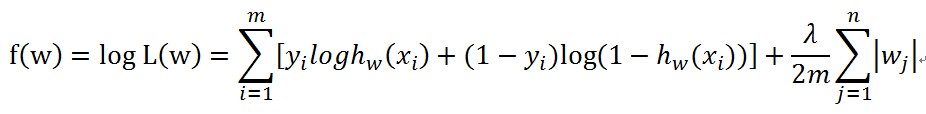
其中L2和L1是两种不同的正则化技术,区别具体可以看其他博文。
1.3.2求解工具
这个是多出来的东西,因为解上面的最优化问题可以有通用的解法SGD和BFGS。
但是前面的博文说过,找一个工具是很重要的,我们用过的比较好的工具就是vw。
Vw这个工具有几个优点如下
1、Vw这个工具可以前期先用SGD跑出一个接近最优解的解,再用BFGS进行微调,得到尽可能的最优解。
2、vw可以直接在Hadoop集群上进行并行训练,避免了很多数据转移的工作。
3、vw非常快,几亿的训练样本一般一个小时以内就完成,网络开销也不大,因为传输的东西很少。
1.3.3在线学习
在线学习就是把模型在线上实时更新,投放了一个广告,就马上得到一个样本,利用这个样本去更新模型(SGD的方式)。
这样的话,模型是在线上训练的,所以也叫在线学习。
1.4模型架构
从模型视角看,系统架构是下面的样子的。
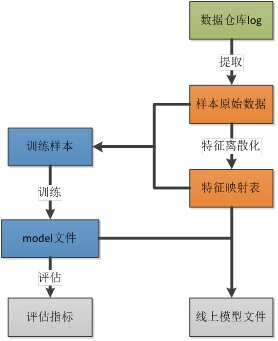
1.5优点
除了logisticregression,还有很多其他的模型可以选择的,如random forest、gbdt。这些模型应用起来可能会有一定的效果提升,但是相比logistic regression来说,还是没有具备那么高的扩展性。
下面列些优点看看。
和逻辑回归算法本身的很多特点有关的,例如:
1、变量范围是[-∞ ,+∞];同时和其他“广义线性回归”相比,值域是[0,1],因此形式上类似一个概率函数,适合分类问题;
2、可扩展性好,适合海量的特征;训练工具多样、可选
3、online learning,能够进行增量学习;
4、线性模型,解释性强。
这些优点都让logisticregression在做ctr预估的时候特别有优势,尤其是可扩展性,可以简单地增加特征,不需要太多的工作。
1.6评估
评估模型效果的方法有很多,如:
1. AUC,从排序的角度评估模型预估效果;
2. MAE(Mean Absolute Error)/MSE(Mean Squared Error),从准确率的角度评估模型预估效果;
3.OE比,就是预估的平均ctr与真实的ctr的比值,越接近1越准
致谢
多位互联网博主如@Rickjin等。
多位同事的指点。
参考文献
[1] Computational Advertising:The LinkedIn Way. Deepak Agarwal, LinkedIn Corporation CIKM
[2] Ad ClickPrediction: a Viewfrom the Trenches. H. Brendan McMahan, Gary Holt et al,Google的论文
[3] http://www.flickering.cn/uncategorized/2014/10/%E8%BD%AC%E5%8C%96%E7%8E%87%E9%A2%84%E4%BC%B0-2%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92%E6%8A%80%E6%9C%AF/腾讯的广点通的技术博客《逻辑回归技术》















 9751
9751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









