







工业界模型综述
下面介绍一些模型,选取标准是:
- 由工业界提出的实战模型
- 经发表即引发大量关注的”明星模型“
- 经过工业界考验,大家普遍认可的
文中提到的模型基本都是召回和排序的模型,计算广告领域的其他业务,如定价、匹配、流量分发等等,用到的技术会有区别。大体上来讲,神经网络大体有如下几个山头(并不严格正交):
DNN / Wide and Deep / 加入Attention 的 model / Multi-task 的 model
具体地,现在主流使用的模型和方法包括(部分久经考验、不需介绍的经典模型省略介绍):
-
传统机器学习模型:
- LR:机器学习经典模型,详略。
- FM、FFM:机器学习经典模型,详略。
- GBDT+LR[1]:GBDT+LR是小公司、少数据、和对DNN有畏惧心理的公司和业务中应用最广泛的模型。它的非线性不需要人手工构造,由树模型学到,降低了特征工程的复杂度。模型结构简洁,加上近几年树模型开发充分,拥有xgboost和lightgbm这样训练速度和精度都惊人的工具,所以训练成本极低,是很强的baseline。
-
深度学习模型:
-
纯DNN模型:DNN在CNN制霸ImageNet后,就不断有NN在排序模型的尝试,在Google放出自己youtube的排序模型是纯粹的DNN[2]之前,DNN就已经成为主流了,这篇工作放出来后,就更少有人和神经网络过不去了。

Youtube DNN(2016),简单的vector pooling加上手工特征工程concat直接送入DNN,是大多数工业界早期尝试DNN的通用做法 -
双塔系列模型:
- DSSM及变种[3][4]:DSSM模型是微软发表的一篇工作,本用于语义匹配,后被移植至排序模型–这个intuition是很自然的,毕竟语义匹配本质上也是一类排序问题。双塔模型的最大特点就是user和item是独立的两个子网络,对工业界十分友好,两个塔可以各自缓存,线上infer只需要取出缓存做有限的运算即可。

朴素的DSSM双塔模型(2015),每个塔互相独立,可各自缓存
- DSSM及变种[3][4]:DSSM模型是微软发表的一篇工作,本用于语义匹配,后被移植至排序模型–这个intuition是很自然的,毕竟语义匹配本质上也是一类排序问题。双塔模型的最大特点就是user和item是独立的两个子网络,对工业界十分友好,两个塔可以各自缓存,线上infer只需要取出缓存做有限的运算即可。
-
Wide and Deep 系列模型[5]:
Wide and Deep及后续的模型家族是现在业界应用最广泛的深度学习模型,其主要原因在于模型结构就融合了传统机器学习模型和DNN,从而能够既有LR的记忆性,又有DNN的泛化性,加上模型复杂度加强,其上限是远高于LR的。对于有DNN PTSD的人来说,有一个LR在模型中,也显得可靠许多。- Wide and Deep[5]:原始WDL,Deep部分是DNN,Wide部分是LR,WDL的开山之作,这篇文章和工作给后面的研究者非常大的启发,即机器学习和深度学习是可以在一个模型中共存,从而可以同时吸收两者的优势,后面的诸多工作灵感和原形皆出于此。
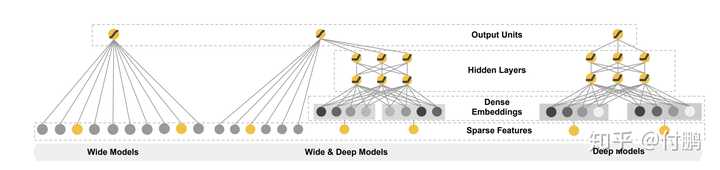
Wide and Deep(2016),清晰明了的模型图。有一说一,Google的网络结构图都画得很漂亮
- Wide and Deep[5]:原始WDL,Deep部分是DNN,Wide部分是LR,WDL的开山之作,这篇文章和工作给后面的研究者非常大的启发,即机器学习和深度学习是可以在一个模型中共存,从而可以同时吸收两者的优势,后面的诸多工作灵感和原形皆出于此。
-
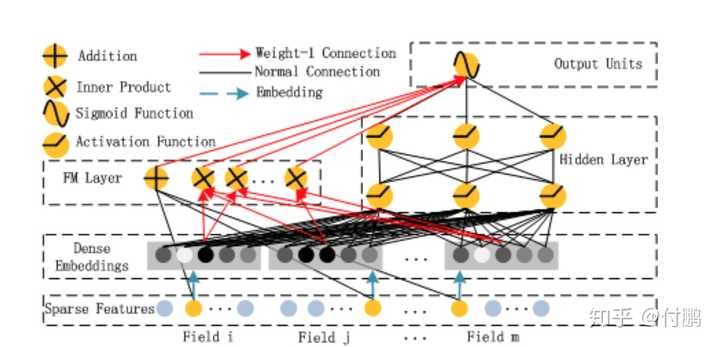
DeepFM[6]:源自Wide and Deep,Wide端改成FM。以此文引申出去,在wide和deep两端各可做任意的修改,以达到增加模型拟合能力和自动特征工程能力的目的。
-
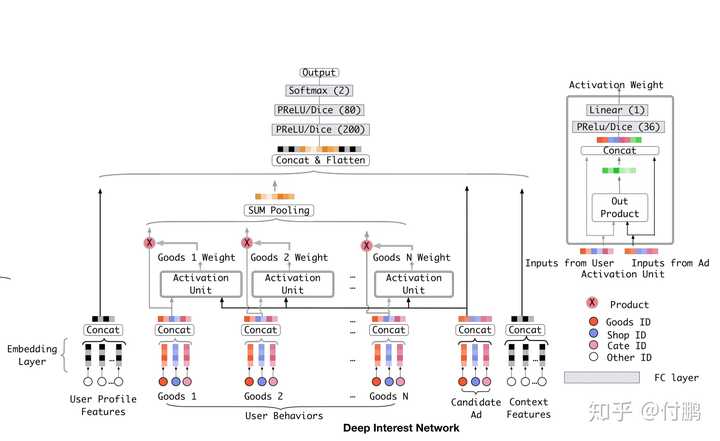
Deep Interest Network(DIN)[7]:阿里妈妈的工作,是Attention风行以来较热门的一篇,简单地说,把DNN中的sum pooling/mean pooling的工作换成了自己的Attention实现。
-
其他:下面罗列一些思想值得借鉴,但因种种原因尚未广泛被采纳的模型
- Deep Cross Network(DCN)[8]:我很喜欢这篇文章的创意,源自Wide and Deep,deep端引入了类似resnet的残差结构,以及无限的特征交叉,带来了理论上任意高阶的特征交叉能力,但工作本身算不上经典,故不放图了,有兴趣可去参考文献自寻。
- Deep Interest Evolution Network(DIEN)[9]:阿里妈妈在DIN上的后续工作把DIN中的attention + sum pooling部分换成了sequential model + attention,然而一个问题是,RNN是不能并行的,且参数量巨大的,所以截止2019年底,几乎所有的RNN based paper都沦为paper work,并没有大规模上线的能力,故不放图。
- BST[10]:阿里手淘工作,Transformer 引入 recsys,详略。
- 强化学习模型:强化学习是不好评价的,在强化学习的一些工作中,我们无法明确,究竟是模型起了作用,还是精心构造的reward起了作用,更多的工作甚至无法说服自己满足MDP的基本假设。
- Youtube的强化学习(2019)[11]:号称youtube近年最大提升,使用强化学习,网络结构十分简单。在bilibili上有youtube相关人员的分享,可以参考:https://www.bilibili.com/video/av47720781/,但是建议思考一下为什么Youtube的交互场景能够使用强化学习,自己的场景是否能够使用强化学习?
以上模型和工作,如果让我只挑选最经典的话,我选择:GBDT+LRDSSMWide and Deep这三篇。对工业界而言,这三个模型依次适用于从小到大的业务规模。
- Youtube的强化学习(2019)[11]:号称youtube近年最大提升,使用强化学习,网络结构十分简单。在bilibili上有youtube相关人员的分享,可以参考:https://www.bilibili.com/video/av47720781/,但是建议思考一下为什么Youtube的交互场景能够使用强化学习,自己的场景是否能够使用强化学习?
阿里巴巴
淘宝线上搜索推荐算法:LR, XGBoost已经是很简单的Baseline了,不管线上线下都可以非常快的做一个初步验证。Wide & Deep model,DeepFM之类的,经典但是也比较老了。具体模型还是根据业务场景来的。主搜那边一些DIN,DIEN都是阿里最新提出的一些深度模型。除了主搜,淘宝还有各种各样的业务场景。比如,淘宝首页的Internt Recommendation,去年上了2个基于GNN的方法(MEIRec和IntentGC)。大公司的算法模型发展是很快的紧跟最新的学术前沿,一方面很多算法研究人员的不断尝试迭代,另一方面会招很多Research Intern一起合作发论文。

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









