







Page
Linux中有个getpagesize的API,得到kernel的内存page大小,页的大小一般由处理器架构决定,通常是4KB。管理内存时,就以页为单位。
Page也叫memory page,或virtual page(因为对运行程序可见的内存使用都是virutal page)。
进程逻辑地址空间
但这里有两种内存地址,一种是进程使用的逻辑地址,一种是实际物理地址。
原来Linux中,创建进程时,每个进程都有自己独立的地址空间。比如32位的系统下,实际物理内存是2GB,而进程内部的可用空间是4GB的线性空间,逻辑地址超过2GB也没关系,会经过一次转换,转换后是物理内存地址。
需要分配内存时,使用的是逻辑地址,再映射到物理地址上。而映射关系用一个页映射表/页交换表的数据结构来表示。每个进程都有自己的页表。
一页是4KB,对于一个32位的逻辑地址,那高20位表示的就是page号,低12位表示page内偏移地址。
比如,一个程序中给一个变量分配了空间0xAD89E010,那这个逻辑地址,0xAD89E就是page的号码,要在页交换表里把这个page号码换成实际物理地址,比如是0x12345,然后实际这个变量的地址就是0x12345010。
这个页交换表,一共是2^20个,每个需要分配一个字来存储,就是4字节,那一个进程就要占用4MB的空间来存储这个页交换表。
MMU
在操作系统工作中,使用的逻辑地址和物理地址的转换,要由硬件来完成,这个硬件叫做MMU,Memory Management Unit。MMU 的作用有两点:地址翻译、内存保护。
所以有的嵌入式系统没有MMU,所以就不支持Linux,而只支持uCLinux,就是因为内存管理上的不同。
MMU 根据内存中的地址翻译表存来进行地址翻译功能,地址翻译表的表项是一个虚拟地址对应一个物理地址,那么会占用太多的内存空间,为此,需要修改翻译方式,常用的有三种:页式、段式、段页式,这也是三种不同的内存管理方式。
就是说如果一个地址对应一个地址的来翻译,那是不可能的,光这个表就把内存用光了,所以上面举的例子,是分成页来映射,只翻译页号,后面的偏移量是不变的。
第一种,如上所说,页式内存管理将虚拟内存、物理内存空间划分为大小固定的块,每一块称之为一页,以页为单位来分配、管理、保护内存。此时 MMU 中的地址翻译表称为页表(Page Table ),每个任务或进程对应一个页表,页表由若干个页表项( PTE : Page Table Entry )组成,每个页表项对应一个虚页,比如在0xAD89E这个索引处,使用4字节保存了0x12345这个物理内存的页号,这就是地址翻译信息,还有一些控制信息,因为20位用完,还剩12位呢。在页式内存管理方式中地址由页号和页内位移两部分组成。
第二种,段式内存管理将虚拟内存、物理内存空间划分为段进行管理,段的大小取决于程序的逻辑结构,可长可短,一般将一个具有共同属性的程序代码和数据定义在一个段中。每个任务和进程对应一个段表( Segment Table ),段表由若干个段表项( STE: Segment Table Entry )组成,内含地址映像信息(段基址和段长度)等内容。在段式虚拟存储器中,地址分为段号、段内位移两部分,使用段表进行地址翻译的过程与使用页表进行地址翻译的过程是相似的。
第三种,段页式内存管理是在内存分段的基础上再分页,即每段分成若干个固定大小的页。每个任务或进程对应有一个段表,每段对应有自己的页表。在访问存储器时,由CPU 经页表对段内存储单元进行寻址。
MMU 除了具有地址翻译的功能外,还提供了内存保护功能。采用页式内存管理时可以提供页粒度级别的保护,允许对单一内存页设置某一类用户的读、写、执行权限,比如:一个页中存储代码,并且该代码不允许在用户模式下执行,那么可以设置该页的保护属性,这样当处理器在用户模式下要求执行该页的代码时, MMU 会检测到并触发异常,从而实现对代码的保护。
MMU在现代操作系统中的必要性或优点
使用这种逻辑地址或者虚拟地址的好处,是每个进程的内存互不干扰,增强了安全性,降低了出错的可能性。如果没有页面级的内存访问管理,而是像最简单那种单片机一样,程序执行时所有任务都可直接访问公用的内存空间,对系统的安全性和稳定性的控制就很难。
而且使用映射后,进程使用的是逻辑地址,和物理地址脱钩,则不会出现内存不足情况,需要申请内存可以直接分配逻辑地址空间,先给你再说,当你真正使用这个地址空间时,才会映射到物理地址上。
比如像Linux中malloc分配地址空间,用的都是虚拟内存,如果虚拟内存没耗尽,是不会分配失败的。要注意的是,使用malloc本身也要有一定开销overhead,就像上面的每个进程的页交换表页也要占用4MB空间呢。
使用MMU来帮助分配内存,不再需要复杂的内存分配算法,因为当分配内存空间时,任何一个空闲的物理内存页都可以使用,程序里使用的空间也不是一定连续的,也不会产生内存碎片(或者说内存碎片控制在4KB一个内存页以内)。
但当真的物理内存不足怎么办?
获取内存的几个常见方法:内存压缩、直接回收以及触发内存不足错误而杀掉部分进程。
还有一种,内存不够,外存补。
操作系统将物理内存页中的内容拷贝到硬盘上交换空间(Swap Space)以释放内存,在需要时再将数据从硬盘上拷贝回来, 这就是Swapping机制。
物理内存和硬盘上的交换分区组成了操作系统上可用的虚拟内存。
我们使用电脑时,有时切换到某个程序时突然很卡,这是有原因的。
触发 Swapping 的进程可能会遇到性能损失,同一个页面的频繁换入换出会导致极其明显的性能抖动。
在 SSD 中随机访问 4KB 数据所需要的时间是访问主存的 1,500 倍,机械磁盘的寻道时间是访问主存的 100,000 倍
我们可以了解一下Swapping 解决的问题、触发入口和执行路径。
解决问题:
* Swapping 可以直接将进程中使用相对较少的页面换出内存,立刻给正在执行的进程分配内存;
* Swapping 可以将进程中的闲置页面换出内存,为其他进程未来使用内存做好准备;
触发入口:
第一种,直接内存回收。
当系统需要的内存超过了可用的物理内存时,内核会将内存中不常使用的内存页(比如缓存)交换到磁盘上为当前进程让出内存,保证正在执行的进程的可用性,这个内存回收的过程是强制的直接内存回收(Direct Page Reclaim)。
第二种,根据条件判断,自动回收。
除了直接内存回收,还有一个专门的内核线程用来定期回收内存,也就是 kswapd0。kswapd0 是 Linux 负责页面置换(Page replacement)的守护进程,它也是负责交换闲置内存的主要进程。
应用程序在启动阶段使用的大量内存在启动后往往都不会使用,通过后台运行的守护进程,我们可以将这部分只使用一次的内存交换到磁盘上为其他内存的申请预留空间。
为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。
剩余内存,则使用 pages_free 表示。
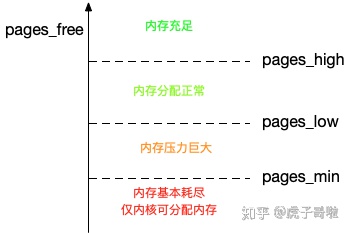
它会在空闲内存低于一定水位时,回收内存页中的空闲内存保证系统中的其他进程可以尽快获得申请的内存。
剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。会触发上面提到的内存直接回收.
剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。
剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
这个页低阈值,其实可以通过内核选项 /proc/sys/vm/min_free_kbytes 来间接设置。min_free_kbytes 设置了页最小阈值,而其他两个阈值,都是根据页最小阈值计算生成的,计算方法如下:
pages_low = pages_min*5/4
pages_high = pages_min*3/2
Linux 操作系统采用最近最少使用(Least Recently Used、LRU)算法置换内存中的页面,系统中的每个区都会在内存中持有 active_list 和 inactive_list 两种链表,其中前者包含活跃的内存页,后者中存储的内存页都是回收的候选页面,除此之外,Linux 还会在将 lru_list 根据内存页的特性分成如下几种:
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
其中包含 ANON 的表示匿名内存页,这些内存页存储了与文件无关的进程堆栈等内容,而包含 FILE 的表示与文件相关的内存,也就是程序文件或者数据对应的内存,而最后的 LRU_UNEVICTABLE 表示禁止回收的内存页。
在内存资源紧张时,Linux 通过直接内存回收和定期扫描的方式,来释放文件页和匿名页,以便把内存分配给更需要的进程使用。
文件页的回收比较容易理解,直接清空,或者把脏数据写回磁盘后再释放。
而对匿名页的回收,需要通过 Swap 换出到磁盘中,下次访问时,再从磁盘换入到内存中。

每当内存页被访问时,Linux 都会将被访问的内存页移到链表的头部,所以在活跃链表末尾的是链表中“最老的”内存页,守护进程 kswapd 的作用是平衡两个链表的长度,将活跃链表末尾的内存页移至不活跃链表的队首等待回收,而函数 shrink_zones 会负责回收 LRU 链表中的不活跃内存页。
既然有两种不同的内存回收机制,那么在实际回收内存时,到底该先回收哪一种呢?
其实,Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整使用 Swap 的积极程度。swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。虽然 swappiness 的范围是 0-100,不过要注意,这并不是内存的百分比,而是调整 Swap 积极程度的权重,即使你把它设置成 0,当剩余内存 + 文件页小于页高阈值时,还是会发生 Swap。
比如在Ubuntu中查看这个值,我的电脑的值是60.
Linux系统中的内存分配
Linux的虚拟地址空间范围为0~4G(intel x86架构32位),Linux内核将这4G字节的空间分为两部分,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF)供内核使用,称为“内核空间”。而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF)供各个进程使用,称为“用户空间”。
用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间虚拟地址。只有用户进程进行系统调用(代表用户进程在内核态执行)等时刻可以访问到内核空间。
因为每个进程可以通过系统调用进入内核,因此,Linux内核空间由系统内的所有进程共享。
用户空间对应进程,所以每当进程切换,用户空间就会跟着变化;而内核空间是由内核负责映射,它并不会跟着进程改变,是固定的。内核空间地址有自己对应的页表,用户进程各自有不同的页表。
如果你要查看某个进程占用的内存区域,可以使用命令cat /proc/<pid>/maps获得,pid是进程号。
通过/proc/<pid>/status可以查看进程的内存使用情况,包括虚拟内存大小(VmSize),物理内存大小(VmRSS),数据段大小(VmData),栈的大小(VmStk),代码段的大小(VmExe),共享库的代码段大小(VmLib)等等。
多级页表 multi-level paging
如果每个进程创建一个页表,每个页表项直接使用逻辑内存页号码作为索引,存储的是物理内存页号码,就是一级页表, 需要4MB。
一个进程的虚拟地址空间是4GB,假如进程只使用4MB内存空间。对于一级页表,我们需要4M空间来存放这4GB虚拟地址空间对应的页表,然后可以找到进程真正使用的4M内存空间。也就是说,虽然进程实际上只使用了4MB的内存空间,但是为了访问它们我们需要为所有的虚拟地址空间建立页表。这就比较浪费。
使用多级页表可以节省页表内存,多级页表通过只为进程实际使用的那些虚拟地址内存区请求页表来减少内存使用量。
以使用二级页表为例:

对于32位处理器来说,32位的线性地址被分成三部分,如下图。其中,最低12位表示偏移量,中间的10位表示页表项,最高10位表示页目录项。由线性地址转换成物理地址经过两步,也就是所谓的二级页表。
控制寄存器cr3中存放了页目录的物理地址,通过cr3寄存器可以找到页目录,而线性地址中的Directory部分决定页目录中的目录项,而页目录项中存放了要找的页表的物理基地址,再结合线性地址中的中间10位(Page Table部分),就可以找到页框的物理地址。一个页框大小为4096字节,线性地址中的Offset部分占12位,因此页框的物理地址结合线性地址Offset部分就可以找到页框中的任何一个字节。
使用多级页表可以使得页表在内存中离散存储。多级页表实际上是增加了索引。
如果使用二级页表的话,一个页目录项可以定位4M内存空间,存放一个页目录项占4K,还需要一页用于存放进程使用的4M(4M=1024*4K,也就是用1024个页表项可以映射4M内存空间)内存空间对应的页表,总共需要4K(页表)+4K(页目录)=8K来存放进程使用的这4M内存空间对应页表和页目录项,这比使用一级页表节省了很多内存空间。当然,在这种情况下,使用多级页表确实是可以节省内存的。但是,我们需要注意另一种情况,如果进程的虚拟地址空间是4GB,而进程真正使用的内存也是4GB,如果是使用一级页表,则只需要4MB连续的内存空间存放页表,我们就可以寻址这4GB内存空间。而如果使用的是二级页表的话,我们需要4MB内存存放页表,还需要4KB内存来存放页目录项,此时多级页表反倒是多占用了内存空间。注意在大多数情况都是进程的4GB虚拟地址空间都是没有使用的,实际使用的都是小于4GB的,所以我们说多级页表可以节省页表内存。
那么使用多级页表比使用以及页表有没有什么劣势呢?
当然是有的。比如:使用以及页表时,读取内存中一页内容需要2次访问内存,第一次是访问页表项,第二次是访问要读取的一页数据。但如果是使用二级页表的话,就需要3次访问内存了,第一次访问页目录项,第二次访问页表项,第三次访问要读取的一页数据。访存次数的增加也就意味着访问数据所花费的总时间增加。
总结:
多级页表优势:
1.可以离散存储页表。
2.在某种意义上节省页表内存空间。
多级页表劣势:
增加寻址次数,从而延长访存时间。
参考:
https://en.wikipedia.org/wiki/Page_table
https://en.wikipedia.org/wiki/Memory_management_unit
https://stackoverflow.com/questions/14133209/why-is-virtual-memory-needed-in-embedded-systems
https://en.wikipedia.org/wiki/Intel_5-level_paging
https://blog.51cto.com/u_15009384/2567614
















 2704
2704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











