







今天的博客主要参考了2014年facebook在会议SIGSAC上发表的paper《Uncovering Large Groups of Active Malicious Accounts in Online Social Networks》。主要讲解了facebook应用机器学习方法在OSN(online social network)反团伙欺诈方面的解决方案。由于有部分读者对于facebook在OSN场景下的团伙欺诈不是特别熟悉,我这里先讲2个针对facebook应用欺诈的案例方式:1 刷粉丝(国内的新浪微博也存在这种现象),某些博主通过购买黑产服务拥有大量粉丝,进而提升账号的价值;2 海量上传垃圾photo,众多黑产账号一起行动,同时上传大量垃圾photo,对整个平台生态造成破坏。
首先作者大致说明了一下在此之前,业界针对该场景下使用的一般方法:
1 利用用户账号之间的关联关系进行判断。其假设前提是,在社交网络中,正常账户肯定会和其他账号之间有很多关联关系,而黑产账号的关联关系是比较少的。这种方法的缺点显而易见,一方面有些不活跃的正常用户的关联关系也是比较稀疏的,另一方面,随着黑产欺诈手段的提升,他们之间也会存在复杂的关联关系。
2 使用传统基于的机器学习方法,就是提取特征训练有监督模型,这种方法最大的缺点就是黑产的欺诈模式在不断变化,如果改变了欺诈模式,而提取的特征又没有及时反馈到这些信息,模型的效果就会显著下降。
基于此,作者提出了paper中的算法模型。其motivation是非常直观明了的:一般来说在OSN场景下黑产作案的团伙特征是比较明显的,而要找团伙其实就是找账号之间的关联关系,构建网络模型进行处理。而账号之间的关联关系一般是通过其他的实体关联起来的,这和具体的应用场景是强相关的。比方说在“刷粉丝”场景下,两个黑产账号如果在短时间内关注了一个follower账号,他们就是有关系的,在“上传垃圾photo”场景下,两个黑产账号在短时间内登录同一个IP上传了photo,他们就是有关系的。

上述就是paper对于用户某一笔操作的抽象,其实就是几个关键字段。需要提前说明一点的是,APPID的作用是为了区分应用场景(比方说对抗“刷粉丝”还是对抗“上传垃圾photo”),因为facebook的应用场景非常丰富,各个场景的数据量又十分巨大,区分了应用计算场景,才能显著降低模型的计算复杂度。接下来,作者定义了用户action match的概念,即用户的两个action是匹配的,形式化的定义如下:
(
U
i
,
T
i
,
C
i
)
≈
(
U
j
,
T
j
,
C
j
)
(U_i,T_i,C_i)\approx(U_j,T_j,C_j)
(Ui,Ti,Ci)≈(Uj,Tj,Cj) if
C
i
=
C
j
C_i=C_j
Ci=Cj and
∣
T
i
−
T
j
∣
<
=
T
s
i
m
|T_i-T_j|<=T_{sim}
∣Ti−Tj∣<=Tsim
也就是说两个账号
U
i
U_i
Ui和
U
j
U_j
Uj,在时间窗口
T
s
i
m
T_{sim}
Tsim内关联同一个实体
C
i
C_i
Ci(相同IP,followed ID等)就认为它们是匹配的。
有了匹配的定义,下面就有了两个节点相似度的定义:
S
i
m
(
U
i
,
U
j
,
C
k
)
=
∣
A
i
k
⋂
A
j
k
∣
∣
A
i
k
⋃
A
j
k
∣
Sim(U_i,U_j,C_k)=\frac{|A_i^k \bigcap A_j^k|}{|A_i^k\bigcup A_j^k|}
Sim(Ui,Uj,Ck)=∣Aik⋃Ajk∣∣Aik⋂Ajk∣即是账号
U
i
U_i
Ui和账号
U
j
U_j
Uj在关联实体
C
k
C_k
Ck 上的相似度.
那么,
S
i
m
(
U
i
,
U
j
)
=
∣
A
i
⋂
A
j
∣
∣
A
i
⋃
A
j
∣
=
∑
k
∣
A
i
k
⋂
A
j
k
∣
∑
k
∣
A
i
k
⋃
A
j
k
∣
Sim(U_i,U_j)=\frac{|A_i \bigcap A_j|}{|A_i \bigcup A_j|}=\frac{\sum_k|A_i^k \bigcap A_j^k|}{\sum_k|A_i^k\bigcup A_j^k|}
Sim(Ui,Uj)=∣Ai⋃Aj∣∣Ai⋂Aj∣=∑k∣Aik⋃Ajk∣∑k∣Aik⋂Ajk∣即
U
i
U_i
Ui和
U
j
U_j
Uj的全局相似度,是它们在所有关联属性上的相似度的和。
其实当定义完了相似度之后,直接计算就可以了,但由于facebook每日的记录量是十分大的,直接计算一段时间范围内的用户相似度基本上是工程上不可行的。
假设要计算的时间区间是[t,t+5],作者利用分治法的思想提出了一种工程上的解决方法,具体过程如下所示:

即以天为单位进行计算,然后把每天的计算结果进行合并,合并公式如下所示:
S
i
m
(
U
i
,
U
j
,
C
k
)
=
∣
A
i
k
⋂
A
j
k
∣
∣
A
i
k
⋃
A
j
k
∣
=
∣
A
i
k
⋂
A
j
k
∣
∣
A
i
k
∣
+
∣
A
j
k
∣
−
∣
A
i
k
⋂
A
j
k
∣
=
∑
t
∣
A
i
,
t
k
⋂
A
j
,
t
k
∣
∑
t
∣
A
i
,
t
k
∣
+
∑
t
∣
A
j
,
t
k
∣
−
∑
t
∣
A
i
,
t
k
⋂
A
j
,
t
k
∣
Sim(U_i,U_j,C_k)=\frac{|A_i^k \bigcap A_j^k|}{|A_i^k\bigcup A_j^k|}=\frac{|A_i^k \bigcap A_j^k|}{|A_i^k|+|A_j^k|-|A_i^k\bigcap A_j^k|}=\frac{\sum_t|A_{i,t}^k \bigcap A_{j,t}^k|}{\sum_t|A_{i,t}^k|+\sum_t|A_{j,t}^k|-\sum_t|A_{i,t}^k \bigcap A_{j,t}^k|}
Sim(Ui,Uj,Ck)=∣Aik⋃Ajk∣∣Aik⋂Ajk∣=∣Aik∣+∣Ajk∣−∣Aik⋂Ajk∣∣Aik⋂Ajk∣=∑t∣Ai,tk∣+∑t∣Aj,tk∣−∑t∣Ai,tk⋂Aj,tk∣∑t∣Ai,tk⋂Aj,tk∣
这里说一点细节,在进行一天内的账号之间的关联关系计算的时候,作者并没有针对一天内的所有记录进行shuffle操作,而是把一天内的数据划分以
2
T
s
i
m
2T_{sim}
2Tsim为窗口的很多数据片,因为只有时间间隔在
T
s
i
m
T_{sim}
Tsim内的用户记录才有可能是匹配的。具体滑窗的示意图如下所示:
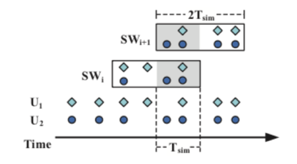
可以发现窗口的长度为
2
T
s
i
m
2T_{sim}
2Tsim,而移动的距离每次为
T
s
i
m
T_{sim}
Tsim,这样两个窗口之间就会有重叠区域,为了避免重复计算,在进行match数统计的时候,一方面考虑到两个账号行为之间的时间间隔是否小于
T
s
i
m
T_{sim}
Tsim,还要看是否同时处于
2
T
s
i
m
2T_{sim}
2Tsim窗口中的前半部分还是后半部分(每次只计算前半部分或者后半部分中的一半就可以避免重复计算)。
当计算完了账号两两之间的相似度之后,就可以构建出一个账号关系图出来,图中的点代表了账号,边就是账号产生了关系,边的权重就是账号之前计算出来的相似度,如下图所示:
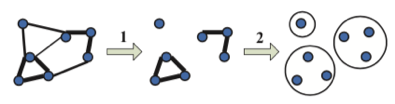
这里作者想采用single-linkage层次化的聚类算法,进行节点间的聚类操作。但是发现当节点的规模很大的时候,算法的执行效率非常低。这里作者采用技巧把问题进行了巧妙的转化,即通过设定阈值将权重小于某一阈值的所有边删除掉,然后计算剩余部分图的全联通子图,处于同一子图中的节点就被划分到了同一团伙中。这样就在保证工程能够实现的情况下,确保了模型的正确运行。
接下来作者通过大量实验证明了该算法挖掘出团伙的准确率往往能达到90%以上,而且团伙中的账号越多,该团伙为黑产的概率越高。















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









