







最近看论文,发现了一个新的概念“Deep memory network”,那么今天就来梳理一下这个框架的基本原理及使用场景。
其实从提出的时间上来讲,这个框架一点都不新,由Weston et al 在2014提出。这个框架描述是:“A memory network consists of a memory m m m and four components I , G , O I, G, O I,G,O and R R R, where m is an array of objects such as an array of vectors. Among these four components, I I I converts input to internal feature representation, G G G updates old memories with new input, O O O generates an output representation given a new input and the current memory state, R R R outputs a response based on the output representation.” 这些描述看起来确实非常的繁琐,但是其实如果抽象一下的话,memory network完全可以想象成一台计算机, m m m是内存, I I I是输入设备, R R R是输出设备,其他的步骤完全可以看出是CPU对内存数据的更新操作。而名称中的deep不过是指把多层这样的结构串联起来,构成了一个更深层次的网络结构。其实如果接触过深度学习的人都知道,RNN系列结构(LSTM、GRU)就属于“Deep memory network”下的一个具体的例子。下面我们从两篇论文出发,来讲解一下这种结构是如何在实际问题中应用的。
首先讲的是《Aspect Level Sentiment Classification with Deep Memory Network》2016 EMNLP。他的网络结构如下:
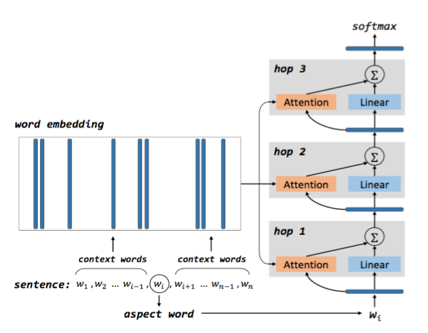
这里的hop就代表了层数,这里学习了LSTM中的权值共享的思想,各个hop中的参数也是共享的,大大减少了模型的复杂度。他假设了aspect word就是句子中的某一个词语。模型的初始输入是aspect词向量,这里的memory 中存放的是当前分析的一句话中所有的词语所对应的词向量,假设这些词向量为 m i m_i mi,一句话有 k k k个词, g i = t a n h ( W a t t . [ m i ; v a s p e c t ] + b a t t ) g_i=tanh(W_{att}.[m_i ; v_{aspect}]+b_{att}) gi=tanh(Watt.[mi;vaspect]+batt),根据这个式子我们可以得到 { g 1 , g 2 , . . . . . . . g k } \{g_1,g_2,.......g_k\} {g1,g2,.......gk}。然后,我们把这些 g g g向量送入到softmax中进行归一化, α i = e x p ( g i ) ∑ j = 1 k e x p ( g j ) \alpha_i=\frac{exp(g_i)}{\sum_{j=1}^k exp(g_j)} αi=∑j=1kexp(gj)exp(gi),可以得到系数 { α 1 , α 2 , . . . . . . α k } \{\alpha_1,\alpha_2,......\alpha_k\} {α1,α2,......αk}。那么最后模型的输出就是 v e c = ∑ i = 1 k α i . m i vec=\sum_{i=1}^k\alpha_i.m_i vec=∑i=1kαi.mi。接着这个vec被作为下一层的 v a s p e c t v_{aspect} vaspect 被输入到模型中,进行反复的变换。同时这篇论文还做了一个假设,即距离aspect词语更近的词语将会对该aspect有更大的贡献,于是他把这种距离关系也考虑进去了,整体的公式是: m i = e i ⨀ v i m_i=e_i \bigodot v_i mi=ei⨀vi, v i v_i vi中的所有元素都是一样的,由不同公式给出,总的来说就是离aspect词越近这个系数越大。
接下来要讲的是《End-To-End Memory Networks》2015 NIPS。他研究的领域是自动问答,即给出几句话的描述
{
x
1
,
x
2
,
.
.
.
.
.
.
x
n
}
\{x_1,x_2,......x_n\}
{x1,x2,......xn}和一个问题
q
q
q,然后自动根据问题回答出一个词语
a
a
a(或者几个词语)。这里用的模型也是“memory network”,网络结构如下:
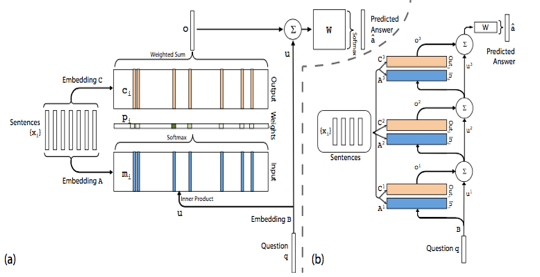
词表大小是
V
V
V。首先是输入转化矩阵A(
d
×
V
d \times V
d×V),需要注意的是这里的
{
x
1
,
x
2
,
.
.
.
.
.
.
x
n
}
\{x_1,x_2,......x_n\}
{x1,x2,......xn}都代表了一句话,而A的作用就是根据句子
x
i
x_i
xi中的每一个词语去生转化成为内部的memory中的向量
{
m
1
,
m
2
,
.
.
.
.
.
.
.
m
n
}
\{m_1,m_2,.......m_n\}
{m1,m2,.......mn},
m
i
=
∑
j
A
x
i
j
m_i=\sum_jAx_{ij}
mi=∑jAxij,其中的
x
i
j
x_{ij}
xij是一种one-hot的表示方式。同理我们用另一个转化矩阵B讲问题q转化成内部的表示u,
u
=
∑
j
B
q
j
u=\sum_j Bq_j
u=∑jBqj,那么就有
p
i
=
s
o
f
t
m
a
x
(
u
.
m
i
)
p_i=softmax(u.m_i)
pi=softmax(u.mi)。同时模型定义了,每个
x
i
x_i
xi都对应了一个output vector
c
i
c_i
ci,由另一个转化矩阵C生成,
c
i
=
∑
j
C
x
i
j
c_i=\sum_jCx_{ij}
ci=∑jCxij。那么定义
o
=
∑
p
i
.
c
i
o=\sum p_i.c_i
o=∑pi.ci,那么我们最后的预测为
a
=
s
o
f
t
m
a
x
(
W
(
o
+
u
)
)
a=softmax(W(o+u))
a=softmax(W(o+u)),其中
W
W
W的维度为
V
×
d
V \times d
V×d,即回答的结果为一个词。为了能够把不同的层次连接起来,定义
u
k
+
1
=
u
k
+
o
k
u^{k+1}=u^k+o^k
uk+1=uk+ok。
从上述描述中我们不难看出,对于每个i层有不同的参数矩阵,
A
i
B
i
C
i
A_i B_i C_i
AiBiCi,其实为了简化复杂度,通常有如下的方式:1
A
k
+
1
=
C
k
A^{k+1}=C^k
Ak+1=Ck ;2 采用类似RNN的方式,即
A
1
=
A
2
=
A
3
=
.
.
.
.
.
A
N
B
1
=
B
2
=
B
3
=
.
.
.
.
.
B
N
C
1
=
C
2
=
C
3
=
.
.
.
.
.
C
N
A^1 = A^2 = A^3 =..... A^N B^1 = B^2 = B^3 =..... B^N C^1 = C^2 = C^3 =..... C^N
A1=A2=A3=.....ANB1=B2=B3=.....BNC1=C2=C3=.....CN。其实我感觉就是约束参数的取值而已,其实我们自己也可以按照类似的思想进行构造。
总之,“deep memory network”代表了一种思想框架,指代了一种循环处理数据的逻辑结构。希望以后能在这方面做更加细致的研究和探索。















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









