









今天的博客主要参考了论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。这篇paper是Google公司下几个研究员发表的,而且在NLP领域引起了很大的轰动(在多个NLP任务集上都打破了之前最好的记录)。
其实,这个Bert利用了迁移学习的思想,把针对语言模型任务设计出的网络参数进行预训练,然后迁移到了下层的任务中进行进一步的fine-tuning。只不过在进行训练语言模型的时候,利用的是自己提出的子结构Transformer layer+ feed forward layer(详情参看论文《Attention is all you need》)。最终模型参数是12个Transformer layer+ feed forward 层,head个数是12,hidden state维度是768。
在进行词语Embedding表征的时候,每个词语都提取了三个维度的信息,如下图所示:
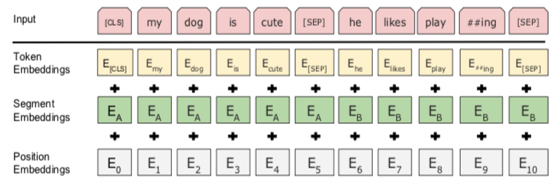
其中Token Embedding就是原始概念中对应的词向量,其中的
E
C
L
S
E_{CLS}
ECLS标识了每一个句子的开始信息,
E
S
E
P
E_{SEP}
ESEP标识了两个句子的分割信息;Segment Embedding是为进行sentence pair任务的训练,其中
E
A
E_A
EA和
E
B
E_B
EB会随着模型进行训练,如果是针对只有一个句子的下游任务,那么只会有
E
A
E_A
EA;Position Embedding是用来标识词向量位置信息.三者相加构成了模型的输入部分。
接下来,通过Masked LM和Next Sentence Prediction对模型进行预训练。
所谓Masked LM就是按照一定的概率(15%)随机的把一个句子中的某些词语用mask进行替换,然后任务是预测这些被mask掉的词语,相当于完形填空的任务。比方说:my dog is hairy → my dog is [MASK]。这些 [MASK]也会对应一个Embedding,并随着模型一起训练。其实在实做的时候,大约有80%的情况会使用 [MASK]替换,剩下的10%词语会被随机选出的其他词语进行替换,10%词语保持词语不动。
所谓Next Sentence Prediction就是为了应对下游任务利用Sentence pair之间相互关联的任务而设定的,比方说问答任务,推理任务等。这个sentence pair中有50%的是真正的在原始语料中是连续存在的两个句子,有50%是随机挑选的没有关联关系的两个句子。有关联关系的句子被标注为1类,没有关联关系的句子被标注为0。
需要注意的是,如果是利用sentece level的表征,那么就使用模型最后一层针对
E
C
L
S
E_{CLS}
ECLS表征来作为整个句子的代表。在训练好了这些语言模型之中用到的参数之后,就会很方便的迁移到下游的任务中去,如下图所示:
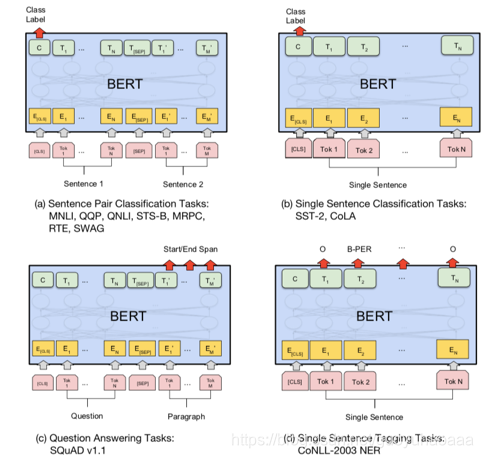
需要注意的是,如果下游任务只是针对一个句子的任务,比方说单独句子的分类,那么就不需要构造Next Sentence Prediction,只需要使用Masked LM即可;如果下游任务需要利用到两个句子之间的相关关系,比方说阅读理解,自动问答等,就需要同时使用Masked LM和Next Sentence Prediction。
作者通过一系列在各个任务和数据集上的实验,充分地说明了Bert模型的有效性;有时候即使下游任务不fine tune上游的任务网络参数,直接把上游的输出作为feature输入到下层任务的网络中去,最终的结果依然会比之前所有模型要好。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









