






一、背景介绍
YOLO(You Only Look Once: Unified, Real-Time Object Detection),是Joseph Redmon和Ali Farhadi等人于2015年提出的基于单个神经网络的目标检测系统。在2017年CVPR上,Joseph Redmon和Ali Farhadi又发表的YOLO 2,进一步提高了检测的精度和速度。本博仅学习YOLO!
// 论文下载地址
https://pjreddie.com/media/files/papers/yolo.pdf下边简单说一下目标检测( Object detection)发展:
早期的目标检测方法通常是通过提取图像的一些 robust 的特征(如 Haar、SIFT、HOG 等),使用 DPM (Deformable Parts Model)模型,用滑动窗口(silding window)的方式来预测具有较高 score 的 bounding box。这种方式非常耗时,而且精度又不怎么高。
后来出现了object proposal方法(其中selective search为这类方法的典型代表),相比于sliding window这中穷举的方式,减少了大量的计算,同时在性能上也有很大的提高。利用 selective search的结果,结合卷积神经网络的R-CNN出现后,Object detection 的性能有了一个质的飞越。基于 R-CNN 发展出来的 SPPnet、Fast R-CNN、Faster R-CNN 等方法,证明了 “Proposal + Classification” 的方法在 Objection Detection 上的有效性。
相比于 R-CNN 系列的方法,本论文提供了另外一种思路,将 Object Detection 的问题转化成一个 Regression 问题。给定输入图像,直接在图像的多个位置上回归出目标的bounding box以及其分类类别。
YOLO是一个可以一次性预测多个Box位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。事实上,目标检测的本质就是回归,因此一个实现回归功能的CNN并不需要复杂的设计过程。YOLO没有选择滑动窗口(silding window)或提取proposal的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用proposal训练方式的Fast-R-CNN常常把背景区域误检为特定目标。
二、论文摘要
下图所示是YOLO检测系统流程:
- 将图像Resize到448*448;
- 运行CNN;
- 非极大抑制优化检测结果。

YOLO是基于Pascal VOC2012数据集的目标检测系统。它能够检测到20种Pascal的目标类别,包括:
- 人
- 鸟,猫,牛,狗,马,羊
- 飞机,自行车,船,汽车,摩托车,火车
- 瓶子,椅子,桌子,盆栽植物,沙发,电视或者显示器
YOLO的总体框架示意图如下:
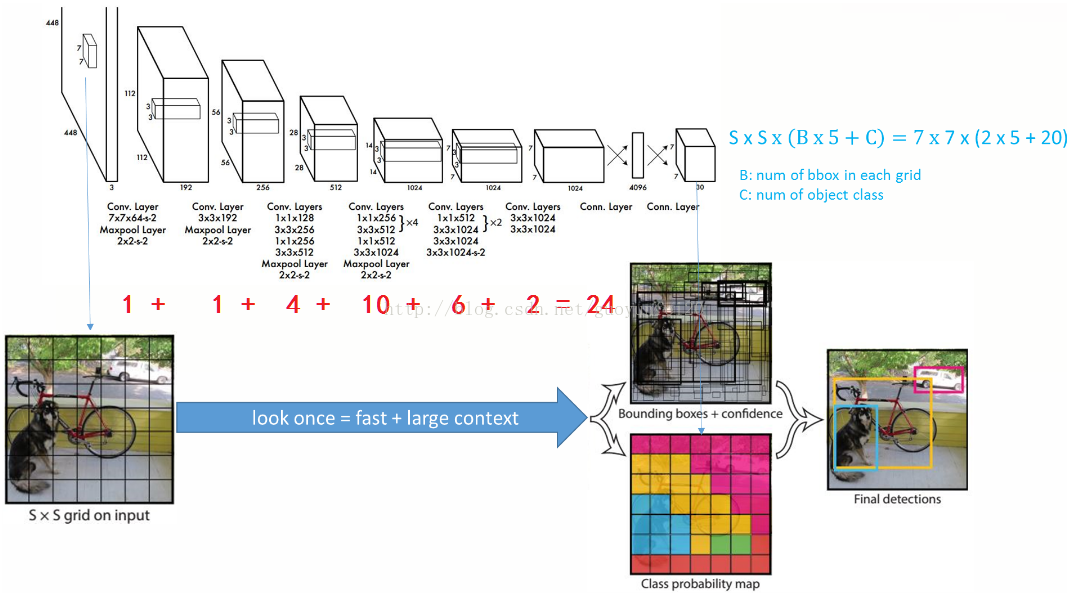
一体化的设计方案:
YOLO的设计理念遵循端到端训练和实时检测。YOLO将输入图像划分为S*S个网格,如果一个物体的中心落在某网格(cell)内,则相应网格负责检测该物体。
在训练和测试时,每个网络预测B个bounding boxes,每个bounding box对应5个预测参数:
- bounding box的中心点坐标(x,y),宽高(w,h)
- 和置信度评分(confidence)
这个置信度评分:
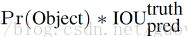
综合反映了:
- 当前bounding box中含有object的置信度Pr(Object)
- 当前bounding box预测目标位置的准确性IOU(pred|truth)
如果bouding box内不存在物体,则Pr(Object)=0。如果存在物体,则根据预测的bounding box和真实的bounding box计算IOU,同时会预测存在物体的情况下该物体属于某一类的后验概率Pr(Class_i|Object)。
假定一共有C类物体,那么每一个网格只预测一次C类物体的条件类概率Pr(Class_i|Object), i=1,2,...,C;每一个网格预测B个bounding box的位置。即这B个bounding box共享一套条件类概率Pr(Class_i|Object), i=1,2,...,C。基于计算得到的Pr(Class_i|Object),在测试时可以计算某个bounding box类相关置信度:Pr(Class_i|Object)*Pr(Object)*IOU(pred|truth)=Pr(Class_i)*IOU(pred|truth)。如果将输入图像划分为7*7网格(S=7),每个网格预测2个bounding box (B=2),有20类待检测的目标(C=20),则相当于最终预测一个长度为S*S*(B*5+C)=7*7*30的向量,从而完成检测+识别任务,整个流程可以通过下图理解。

















 1541
1541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









