









由于时间原因,只学了部分,先整理一下,原文链接
1.本文首先讲述了K近邻算法,然后讲述了相关的距离度量表示法
2.讲K近邻算法的实现–KD树,和KD树的插入,删除,最近邻查找等操作
第一部分、K近邻算法
1.1、什么是K近邻算法
K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,是用于解决分类问题的算法,当K=1时,算法便成了最近邻算法。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。根据这个说法,咱们来看下引自维基百科上的一幅图:
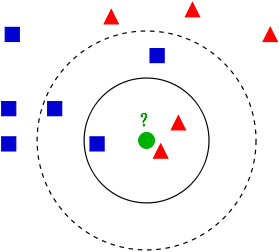
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手,所谓观其友,而识其人。我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?从上图中,你还能看到:
如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。
1.2、近邻的距离度量表示法
上文第一节,我们看到,K近邻算法的核心在于找到实例点的邻居,这个时候,问题就接踵而至了,如何找到邻居,邻居的判定标准是什么,用什么来度量。这一系列问题便是下面要讲的距离度量表示法。但有的读者可能就有疑问了,我是要找邻居,找相似性,怎么又跟距离扯上关系了?
这是因为特征空间中两个实例点的距离可以反应出两个实例点之间的相似性程度。K近邻模型的特征空间一般是n维实数向量空间,使用的距离可以使欧式距离,也是可以是其它距离,既然扯到了距离,下面就来具体阐述下都有哪些距离度量的表示法,权当扩展
1. 欧氏距离,最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中,如点 x = (x1,…,xn) 和 y = (y1,…,yn) 之间的距离为:
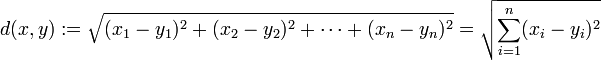
也可以用表示成向量运算的形式:
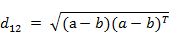
2. 曼哈顿距离,我们可以定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1, y1)的点P1与坐标(x2, y2)的点P2的曼哈顿距离为: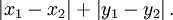 要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
通俗来讲,想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。而实际驾驶距离就是这个“曼哈顿距离”,此即曼哈顿距离名称的来源, 同时,曼哈顿距离也称为城市街区距离(City Block distance)。两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离为:
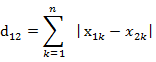
3. 切比雪夫距离,若二个向量或二个点p 、and q,其座标分别为
pi
及
qi
,则两者之间的切比雪夫距离定义如下: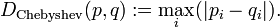 ,
,
这也等于以下Lp度量的极值: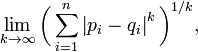 因此切比雪夫距离也称为L∞度量。
因此切比雪夫距离也称为L∞度量。
以数学的观点来看,切比雪夫距离是由一致范数(uniform norm)(或称为上确界范数)所衍生的度量,也是超凸度量(injective metric space)的一种。
在平面几何中,若二点p及q的直角坐标系坐标为及,则切比雪夫距离为: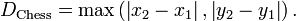 。
。
4. 闵可夫斯基距离(Minkowski Distance),闵氏距离不是一种距离,而是一组距离的定义。两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为: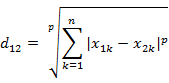
其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离
5. 标准化欧氏距离 (Standardized Euclidean distance ),标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。至于均值和方差标准化到多少,先复习点统计学知识。
假设样本集X的数学期望或均值(mean)为m,标准差(standard deviation,方差开根)为s,那么X的“标准化变量”X*表示为:(X-m)/s,而且标准化变量的数学期望为0,方差为1。
即,样本集的标准化过程(standardization)用公式描述就是:
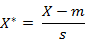
标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差
经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:
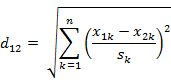
如果将方差的倒数看成是一个权重,这个公式可以看成是一种加权欧氏距离(Weighted Euclidean distance)。
1. 夹角余弦(Cosine) ,几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦
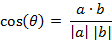
类似的,对于两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度,即: 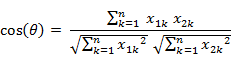
夹角余弦取值范围为[-1,1]。夹角余弦越大表示两个向量的夹角越小,夹角余弦越小表示两向量的夹角越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。
1.3、K值的选择
除了上述1.2节如何定义邻居的问题之外,还有一个选择多少个邻居,即K值定义为多大的问题。不要小看了这个K值选择问题,因为它对K近邻算法的结果会产生重大影响。如李航博士的一书「统计学习方法」上所说:
1. 如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
2. 如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
3. K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用信息。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
第二部分、K近邻算法的实现:KD树
特征点匹配和数据库查、图像检索本质上是同一个问题,都可以归结为一个通过距离函数在高维矢量之间进行相似性检索的问题,如何快速而准确地找到查询点的近邻,不少人提出了很多高维空间索引结构和近似查询的算法。
一般说来,索引结构中相似性查询有两种基本的方式:
- 一种是范围查询,范围查询时给定查询点和查询距离阈值,从数据集中查找所有与查询点距离小于阈值的数据
- 另一种是K近邻查询,就是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,它就是最近邻查询。
同样,针对特征点匹配也有两种方法:
- 最容易的办法就是线性扫描,也就是我们常说的穷举搜索,依次计算样本集E中每个样本到输入实例点的距离,然后抽取出计算出来的最小距离的点即为最近邻点。此种办法简单直白,但当样本集或训练集很大时,它的缺点就立马暴露出来了,举个例子,在物体识别的问题中,可能有数千个甚至数万个SIFT特征点,而去一一计算这成千上万的特征点与输入实例点的距离,明显是不足取的。
- 另外一种,就是构建数据索引,因为实际数据一般都会呈现簇状的聚类形态,因此我们想到建立数据索引,然后再进行快速匹配。索引树是一种树结构索引方法,其基本思想是对搜索空间进行层次划分。根据划分的空间是否有混叠可以分为Clipping和Overlapping两种。前者划分空间没有重叠,其代表就是k-d树;后者划分空间相互有交叠,其代表为R树。
2.1、什么是KD树
Kd-树是K-dimension tree的缩写,是对数据点在k维空间(如二维(x,y),三维(x,y,z),k维(x1,y,z..))中划分的一种数据结构,主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。
首先必须搞清楚的是,k-d树是一种空间划分树,说白了,就是把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。想像一个三维(多维有点为难你的想象力了)空间,kd树按照一定的划分规则把这个三维空间划分了多个空间,如下图所示:
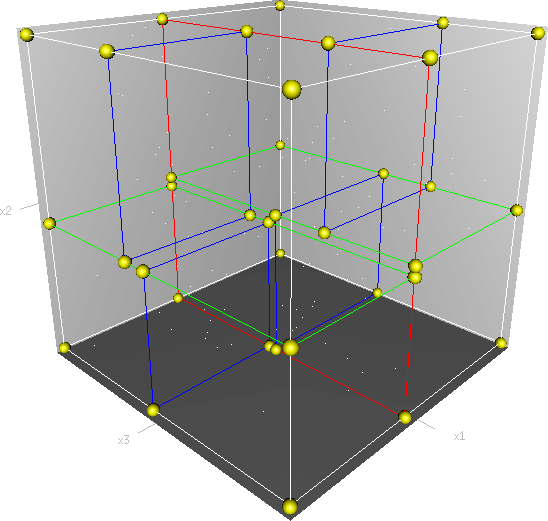
2.2、KD树的构建
Kd-树是一个二叉树,每个节点表示的是一个空间范围。下表表示的是Kd-树中每个节点中主要包含的数据结构。Range域表示的是节点包含的空间范围。Node-data域就是数据集中的某一个n维数据点。分割超面是通过数据点Node-Data并垂直于轴split的平面,分割超面将整个空间分割成两个子空间。令split域的值为i,如果空间Range中某个数据点的第i维数据小于Node-Data[i],那么,它就属于该节点空间的左子空间,否则就属于右子空间。Left,Right域分别表示由左子空间和右子空间空的数据点构成的Kd-树。
| 域名 | 数据类型 | Cool |
|---|---|---|
| Node-Data | 数据矢量 | 数据集中某个数据点,是n维矢量 |
| Range | 空间矢量 | 该节点所代表的空间范围 |
| Split | 整数 | 垂直于分割超面的方向轴序号 |
| Left | Kd-tree | 由位于该节点分割超面左子空间内所有数据点构成的Kd-树 |
| Right | Kd-tree | 由位于该节点分割超面左子空间内所有数据点构成的Kd-树 |
| Parent | Kd-tree | 父节点 |
构建Kd-树的伪码为:
算法:构建Kd-tree
输入:数据点集Data_Set,和其所在的空间。
输出:Kd,类型为Kd-tree
1 if data-set is null ,return 空的Kd-tree
2 调用节点生成程序
(1)确定split域:对于所有描述子数据(特征矢量),统计他们在每个维度上的数据方差,挑选出方差中最大值,对应的维就是split域的值。数据方差大说明沿该坐标轴方向上数据点分散的比较开。这个方向上,进行数据分割可以获得最好的分辨率。
(2)确定Node-Data域,数据点集Data-Set按照第split维的值排序,位于正中间的那个数据点 被选为Node-Data,Data-Set` =Data-Set\Node-data
3 dataleft = {d 属于Data-Set` & d[:split]<=Node-data[:split]}
Left-Range ={Range && dataleft}
dataright = {d 属于Data-Set` & d[:split]>Node-data[:split]}
Right-Range ={Range && dataright}
4 :left =由(dataleft,LeftRange)建立的Kd-tree
设置:left的parent域(父节点)为Kd
:right =由(dataright,RightRange)建立的Kd-tree
设置:right的parent域为kd。
再举一个简单直观的实例来介绍k-d树构建算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内,如下图所示。为了能有效的找到最近邻,k-d树采用分而治之的思想,即将整个空间划分为几个小部分,首先,粗黑线将空间一分为二,然后在两个子空间中,细黑直线又将整个空间划分为四部分,最后虚黑直线将这四部分进一步划分。
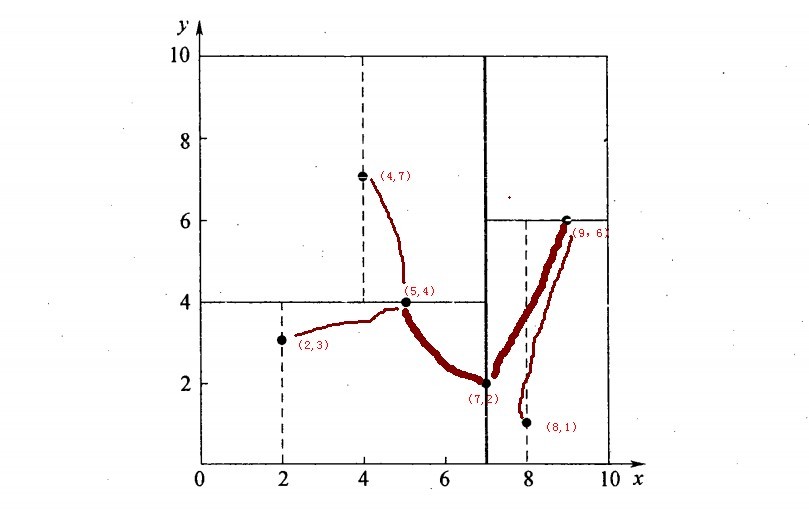
6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}构建kd树的具体步骤为:
确定:split域=x。具体是:6个数据点在x,y维度上的数据方差分别为39,28.63,所以在x轴上方差更大,故split域值为x;
确定:Node-data = (7,2)。具体是:根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以Node-data域位数据点(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:split=x轴的直线x=7;
确定:左子空间和右子空间。具体是:分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)};
如上算法所述,kd树的构建是一个递归过程,我们对左子空间和右子空间内的数据重复根节点的过程就可以得到一级子节点(5,4)和(9,6),同时将空间和数据集进一步细分,如此往复直到空间中只包含一个数据点。
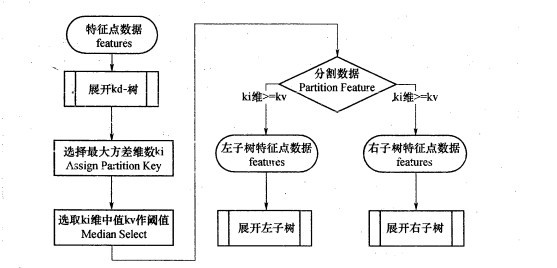
与此同时,经过对上面所示的空间划分之后,我们可以看出,点(7,2)可以为根结点,从根结点出发的两条红粗斜线指向的(5,4)和(9,6)则为根结点的左右子结点,而(2,3),(4,7)则为(5,4)的左右孩子(通过两条细红斜线相连),最后,(8,1)为(9,6)的左孩子(通过细红斜线相连)。如此,便形成了下面这样一棵k-d树:
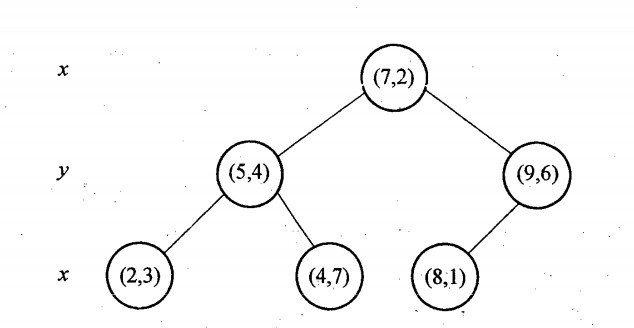
也就是说,如之前所述,kd树中,kd代表k-dimension,每个节点即为一个k维的点。每个非叶节点可以想象为一个分割超平面,用垂直于坐标轴的超平面将空间分为两个部分,这样递归的从根节点不停的划分,直到没有实例为止。经典的构造k-d tree的规则如下:
- 随着树的深度增加,循环的选取坐标轴,作为分割超平面的法向量。对于3-d tree来说,根节点选取x轴,根节点的孩子选取y轴,根节点的孙子选取z轴,根节点的曾孙子选取x轴,这样循环下去。
- 每次均为所有对应实例的中位数的实例作为切分点,切分点作为父节点,左右两侧为划分的作为左右两子树。
2.3、KD树的插入
元素插入到一个K-D树的方法和二叉检索树类似。本质上,在偶数层比较x坐标值,而在奇数层比较y坐标值。当我们到达了树的底部,(也就是当一个空指针出现),我们也就找到了结点将要插入的位置。生成的K-D树的形状依赖于结点插入时的顺序。
2.4、KD树的删除
KD树的删除可以用递归程序来实现。我们假设希望从K-D树中删除结点(a,b)。如果(a,b)的两个子树都为空,则用空树来代替(a,b)。否则,在(a,b)的子树中寻找一个合适的结点来代替它,譬如(c,d),则递归地从K-D树中删除(c,d)。一旦(c,d)已经被删除,则用(c,d)代替(a,b)。假设(a,b)是一个X识别器,那么,它得替代节点要么是(a,b)左子树中的X坐标最大值的结点,要么是(a,b)右子树中x坐标最小值的结点。
也就是说,跟普通二叉树(包括如下图所示的红黑树)结点的删除是同样的思想:用被删除节点A的左子树的最右节点或者A的右子树的最左节点作为替代A的节点(比如,下图红黑树中,若要删除根结点26,第一步便是用23或28取代根结点26)。

当(a,b)的右子树为空时,找到(a,b)左子树中具有x坐标最大的结点,譬如(c,d),将(a,b)的左子树放到(c,d)的右子树中,且在树中从它的上一层递归地应用删除过程(也就是(a,b)的左子树) 。
下面来举一个实际的例子(来源:中国地质大学电子课件,原课件错误已经在下文中订正),如下图所示,原始图像及对应的kd树,现在要删除图中的A结点,请看一系列删除步骤:
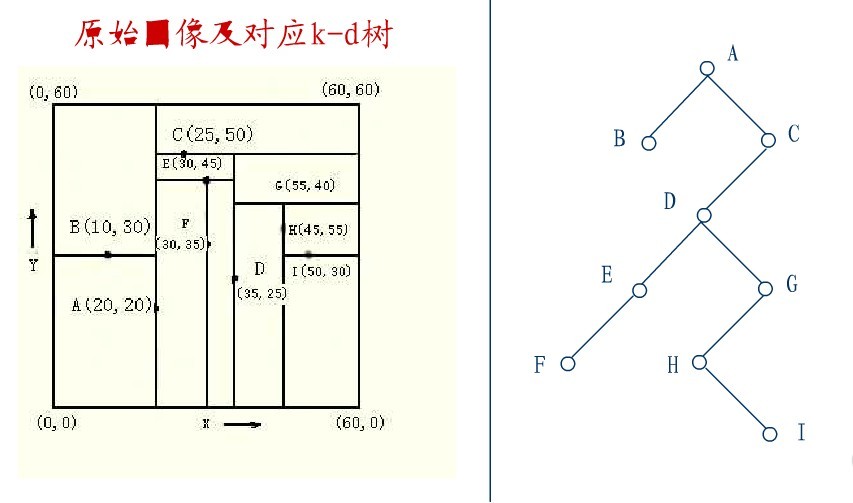
要删除上图中结点A,选择结点A的右子树中X坐标值最小的结点,这里是C,C成为根,如下图:
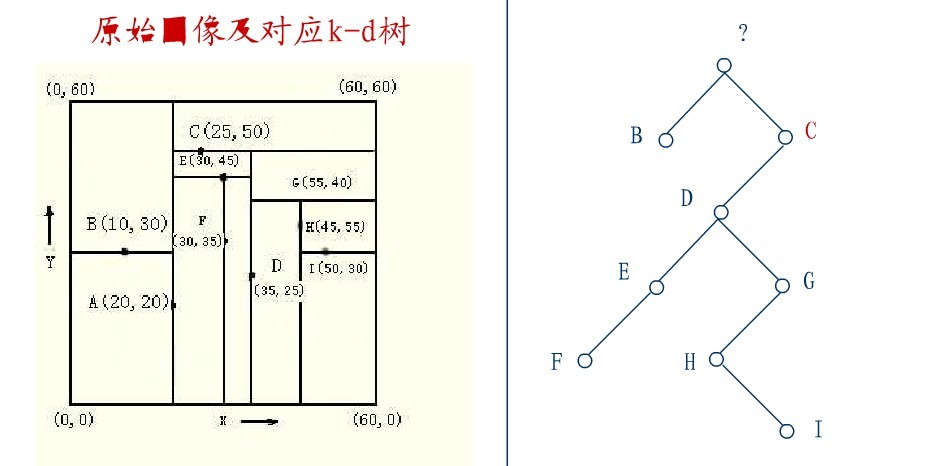
从C的右子树中找出一个结点代替先前C的位置,
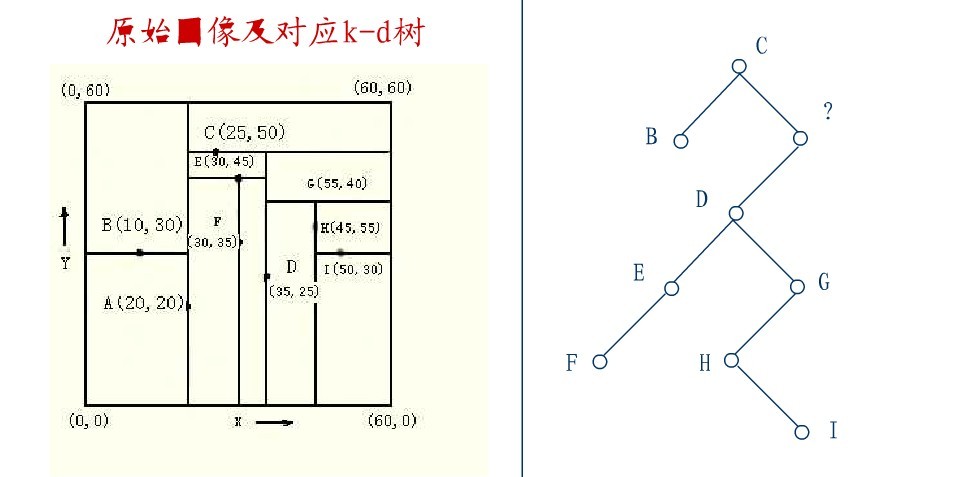
这里是D,并将D的左子树转为它的右子树,D代替先前C的位置,如下图:
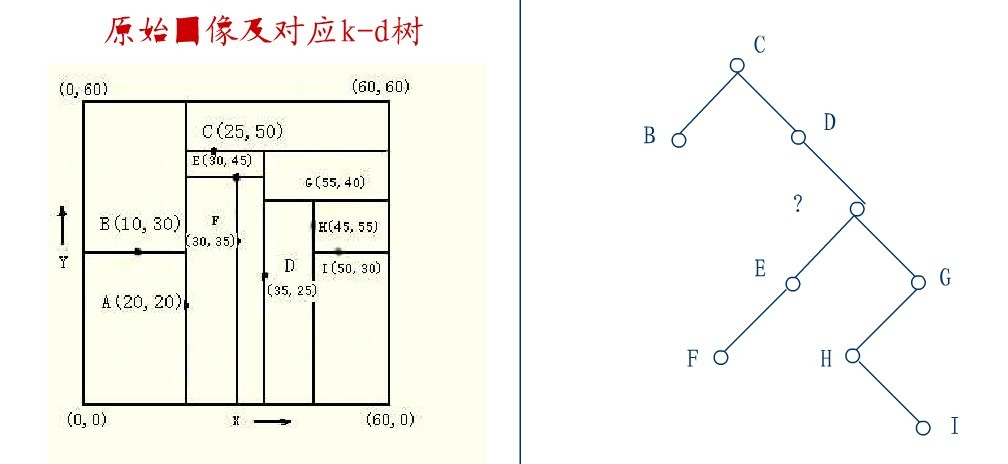
在D的新右子树中,找X坐标最小的结点,这里为H,H代替D的位置,
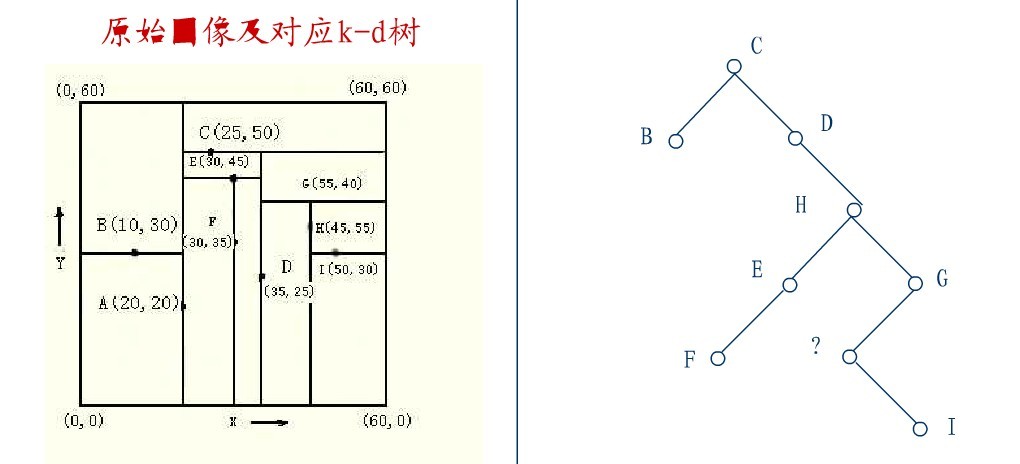
在D的右子树中找到一个Y坐标最小的值,这里是I,将I代替原先H的位置,从而A结点从图中顺利删除,如下图所示:
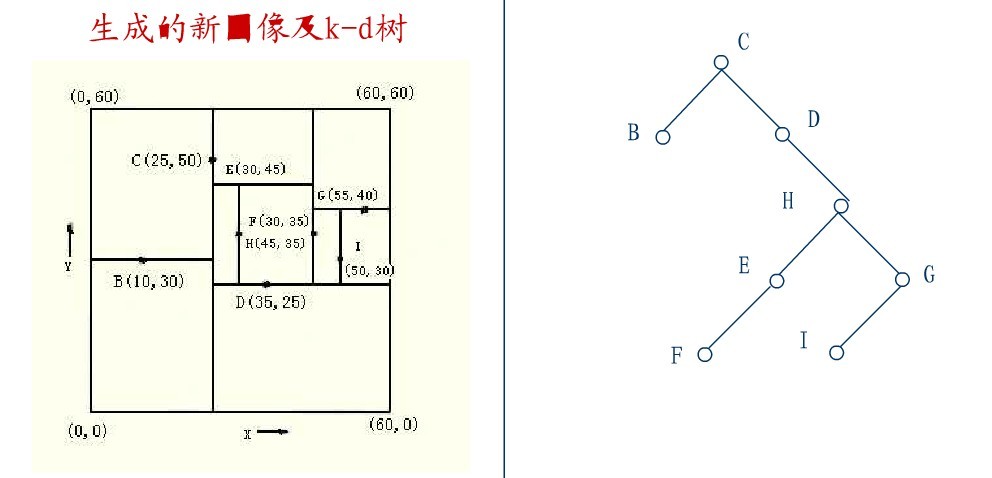
从一个K-D树中删除结点(a,b)的问题变成了在(a,b)的子树中寻找x坐标为最小的结点。不幸的是寻找最小x坐标值的结点比二叉检索树中解决类似的问题要复杂得多。特别是虽然最小x坐标值的结点一定在x识别器的左子树中,但它同样可在y识别器的两个子树中。因此关系到检索,且必须注意检索坐标,以使在每个奇数层仅检索2个子树中的一个。
从K-D树中删除一个结点是代价很高的,很清楚删除子树的根受到子树中结点个数的限制。用TPL(T)表示树T总的路径长度。可看出树中子树大小的总和为TPL(T)+N。 以随机方式插入N个点形成树的TPL是O(N*log2N),这就意味着从一个随机形成的K-D树中删除一个随机选取的结点平均代价的上界是O(log2N) 。
2.5、KD树的最近邻搜索算法
现实生活中有许多问题需要在多维数据的快速分析和快速搜索,对于这个问题最常用的方法是所谓的kd树。在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。在一个N维的笛卡儿空间在两个点之间的距离是由下述公式确定:
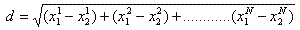
2.5.1、k-d树查询算法的伪代码
k-d树查询算法的伪代码如下所示:
算法:k-d树最邻近查找
输入:Kd, //k-d tree类型
target //查询数据点
输出:nearest, //最邻近数据点
dist //最邻近数据点和查询点间的距离
- If Kd为NULL,则设dist为infinite并返回
- //进行二叉查找,生成搜索路径
Kd_point = &Kd; //Kd-point中保存k-d tree根节点地址
nearest = Kd_point -> Node-data; //初始化最近邻点
while(Kd_point)
push(Kd_point)到search_path中; //search_path是一个堆栈结构,存储着搜索路径节点指针
If Dist(nearest,target) > Dist(Kd_point -> Node-data,target)
nearest = Kd_point -> Node-data; //更新最近邻点
Min_dist = Dist(Kd_point,target); //更新最近邻点与查询点间的距离 ***/
s = Kd_point -> split; //确定待分割的方向
If target[s] <= Kd_point -> Node-data[s] //进行二叉查找
Kd_point = Kd_point -> left;
else
Kd_point = Kd_point ->right;
End while
- //回溯查找
while(search_path != NULL)
back_point = 从search_path取出一个节点指针; //从search_path堆栈弹栈
s = back_point -> split; //确定分割方向
If Dist(target[s],back_point -> Node-data[s]) < Max_dist //判断还需进入的子空间
If target[s] <= back_point -> Node-data[s]
Kd_point = back_point -> right; //如果target位于左子空间,就应进入右子空间
else
Kd_point = back_point -> left; //如果target位于右子空间,就应进入左子空间
将Kd_point压入search_path堆栈;
If Dist(nearest,target) > Dist(Kd_Point -> Node-data,target)
nearest = Kd_point -> Node-data; //更新最近邻点
Min_dist = Dist(Kd_point -> Node-data,target); //更新最近邻点与查询点间的距离的
End while 2.5.2、举例:查询点(2,4.5)
一个复杂点了例子如查找点为(2,4.5),具体步骤依次如下:
- 同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但(4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点;
- 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;
- 回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
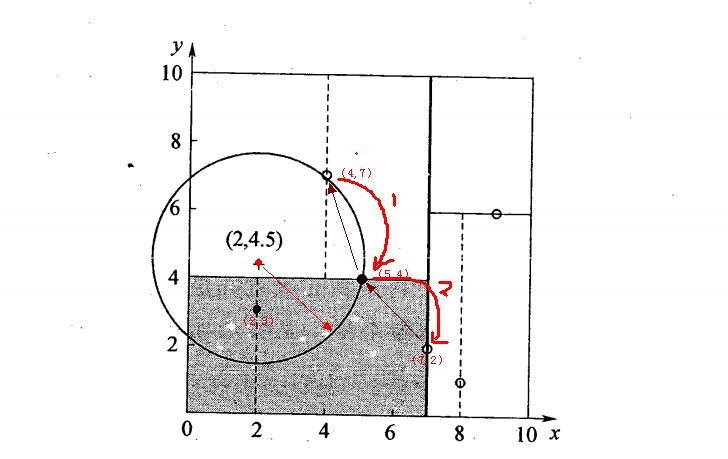
上述两次实例表明,当查询点的邻域与分割超平面两侧空间交割时,需要查找另一侧子空间,导致检索过程复杂,效率下降。















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









