







基于tkinter搭建gridworld强化学习环境🤔
更多代码: Gitee主页:https://gitee.com/GZHzzz
博客主页: CSDN:https://blog.csdn.net/gzhzzaa
写在前面
- 作为一个新手,写这个强化学习-基础知识专栏是想和大家分享一下自己强化学习的学习历程,希望大家互相交流一起进步!😁在我的gitee收集了强化学习经典论文:强化学习经典论文,搭建了基于pytorch的典型智能体模型,大家一起多篇多交流,互相学习啊!😊

show me code, no bb
"""
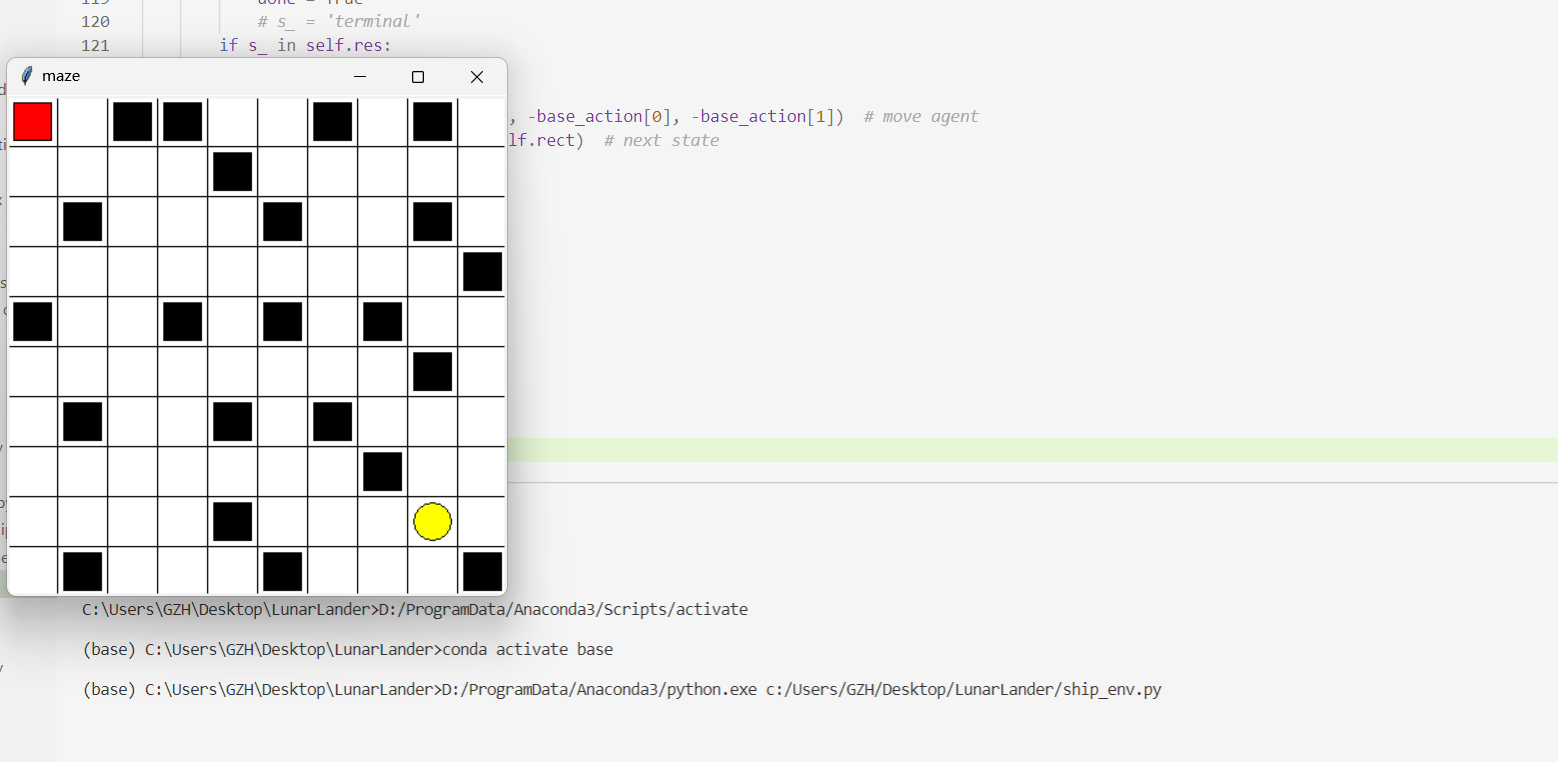
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
"""
import numpy as np
import pandas as pd
import numpy as np
import time
import sys
import tkinter as tk
UNIT = 40 # pixels 像素
MAZE_H = 10 # grid height
MAZE_W = 10 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r'] #行为
self.n_actions = len(self.action_space) #行为数
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_W * UNIT
self.canvas.create_line(x0, y0, x1, y1) #画一条从(x0,y0)到(x1,y1)的线
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell #画第黑色正方形
x = [
1, 8, 5, 9, 2, 4, 3, 9, 8, 7, 5, 3, 1, 0, 4, 5,7, 9, 1,7,4,6,6,8]
y = [
2, 2, 9, 3, 0, 6, 0, 9, 0, 4, 4, 4, 9, 4 , 1, 2,4, 3, 6,7,8,0,6,5]
self.res = []
for i in range(24):
oval_center= origin+np.array([x[i]*UNIT,y[i]*UNIT])
self.rec = self.canvas.create_rectangle(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='black')
self.res.append(self.canvas.coords(self.rec))
# create oval #画黄色
oval_center = origin + UNIT * 8
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect #画红色的正方形
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
# self.update()
# time.sleep(0.1)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
reward = 0
done = False
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT #减40
else:
reward = -5
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT #加40
else:
reward = -5
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT #右移40
else:
reward = -5
elif action == 3: # left
if s[0] > UNIT: #左移40
base_action[0] -= UNIT
else:
reward = -5
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 100
done = True
# s_ = 'terminal'
if s_ in self.res:
reward = -5
self.canvas.move(self.rect, -base_action[0], -base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# s_ = 'terminal'
return s_, reward, done
def render(self):
time.sleep(0.1)
# time.sleep(10)
self.update()
if __name__ == "__main__":
env = Maze()
while True:
# fresh env
env.render()
env.render()
- 代码全部亲自跑过,你懂的!😝
结果展示
- reward与状态转移可以由任务自适应改变
写在最后
十年磨剑,与君共勉!
更多代码:Gitee主页:https://gitee.com/GZHzzz
博客主页:CSDN:https://blog.csdn.net/gzhzzaa
- Fighting!😎
基于pytorch的经典模型:基于pytorch的典型智能体模型
强化学习经典论文:强化学习经典论文

while True:
Go life
















 1993
1993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











