







计算机视觉研究院专栏
作者:Edison_G
目前的anchor-free目标检测器非常简单和有效,但缺乏精确的标签分配方法,这限制了它们与经典的基于Anchor的模型竞争的潜力
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式

1
简要
目前的anchor-free目标检测器非常简单和有效,但缺乏精确的标签分配方法,这限制了它们与经典的基于Anchor的模型竞争的潜力,这些模型由基于IoU度量的精心设计的分配方法支持。

今天分享中,研究者提出了伪IoU:一个简单的度量,带来更标准化和准确的分配规则到anchor-free目标检测框架没有任何额外的计算成本或额外的训练和测试参数,通过利用训练样本质量良好的有效分配规则使它可以进一步提高anchor-free目标检测,之前已经应用于基于anchor的方法。通过将伪IoU度量合并到端到端单阶段anchor-free目标检测框架中,研究者观察到它们在pascal一般目标检测基准上的性能和MSCOCO的一致。新提出的方法(单模型和单尺度)与其他最近最先进的anchor-free的方法比较,也取得了类似的性能。
2
背景
目标检测之anchor
anchor字面意思是锚,指固定船的工具,anchor在计算机视觉中有锚点或锚框,目标检测中常出现的anchor box是锚框,表示固定的参考框。
目标检测是"在哪里有什么"的任务,在这个任务中,目标的类别不确定、数量不确定、位置不确定、尺度不确定,传统非深度学习方法如VJ和DPM,和早期深度学习方法如OverFeat,都要金字塔多尺度+遍历滑窗的方式,逐尺度逐位置判断"这个尺度的这个位置处有没有认识的目标",非常笨重耗时。
近期顶尖(SOTA)的目标检测方法几乎都用了anchor技术。首先预设一组不同尺度不同位置的固定参考框,覆盖几乎所有位置和尺度,每个参考框负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标,anchor技术将问题转换为"这个固定参考框中有没有认识的目标,目标框偏离参考框多远",不再需要多尺度遍历滑窗,真正实现了又好又快,如在Faster R-CNN和SSD两大主流目标检测框架及扩展算法中anchor都是重要部分。
当然也有不用anchor的检测算法:2016 ECCV的YOLO是全局回归,但很快在YOLOv2就替换为anchor方法;2018 ECCV的CornerNet是角点预测,但论文用了非常庞大的hourglass-104速度比较慢,关键点与anchor技术没有明确的公平对比,孰优孰劣尚不清楚。
IoU(Interp over Union)
Interp over Union是一种测量在特定数据集中检测相应物体准确度的一个标准。我们可以在很多物体检测挑战中,例如PASCAL VOC challenge中看多很多使用该标准的做法。
通常我们在 HOG + Linear SVM object detectors 和 Convolutional Neural Network detectors (R-CNN, Faster R-CNN, YOLO, etc.)中使用该方法检测其性能。注意,这个测量方法和你在任务中使用的物体检测算法没有关系。
IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。为了可以使IoU用于测量任意大小形状的物体检测,我们需要:
ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围)
我们的算法得出的结果范围
也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。

最近,目标检测方法的另一个流行分支是anchor-free模型,它们在整个训练过程中不假设预定义的anchor,这减少了许多需要启发式调优的锚的超参数。anchor-free模型直接预测从GT真实框的左、右、顶部和底部的边界框,如FCOS和FSAF。然而,由于缺乏准确的分配,他们都使用其他方法来弥补性能差距。对于FCOS,它将收缩GT内的所有点视为正样本,并增加了一个中心分支来重新权衡检测中减少一些假阳性的输出。对于FSAF,它采用了在线特征选择和无锚点和基于锚的方法的组合。
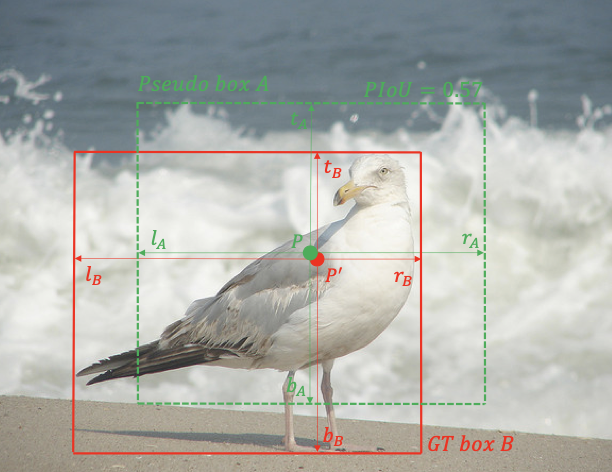
对于GT真实框内的每个特征映射点,在映射到原始输入图像后,我们假设一个相应的伪框为中心,与GT真实框的相同大小。然后我们可以很容易地计算中心伪框和GT真实框之间的单位。由于IoU是基于一个分配给每个点的伪框,我们命名伪IoU度量。在伪IoU计算之后,每个点可以被分配一个伪IoU值v,就像每个锚的IoU一样,用基于锚的方法进行分配。
从上图中显示,边界框边附近的一些点被指定为负样本。如果以这些低伪单位为阳性样本,会导致更多的假阳性和不准确的边界框。
3
新框架分析

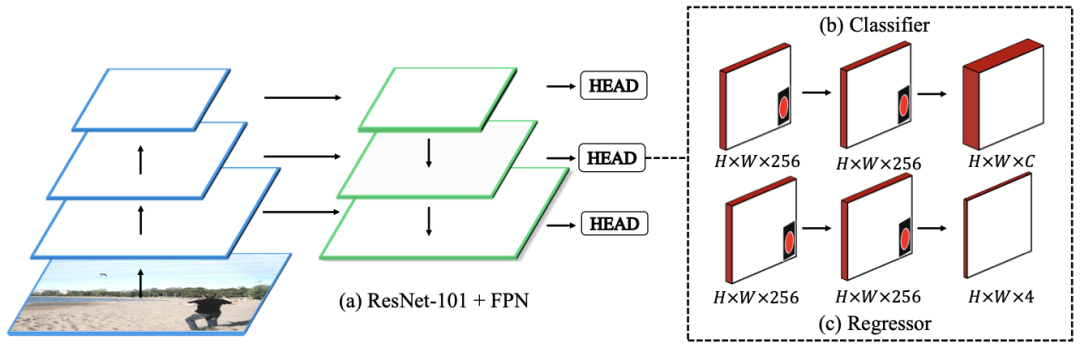
RetinaNet后,我们采用ResNet-101作为骨干来提取特征,并使用FPN通过自上而下的路径和横向连接增强特征图,使丰富的多尺度特征金字塔与单一分辨率输入图像,被证明是一个强大的检测组件,如上图(a)所示。
检测头是一个FCN,它附加到来自FPN的每个输出特征映射上,它包含两个子集:一个分类器和一个回归器。对于上图(b)中所示的分类器子网络,它遵循四个具有256个滤波器的堆叠3×3卷积层,最后附加一个具有C个滤波器的3×3卷积层。C是用来在每个点上进行最终分类的类数。对于回归器子网络,在上图(c)中,它还遵循四个堆叠的3×3卷积层和256个卷积层,最后附加了每个空间位置具有4个滤波器的3×3卷积层。
损失函数
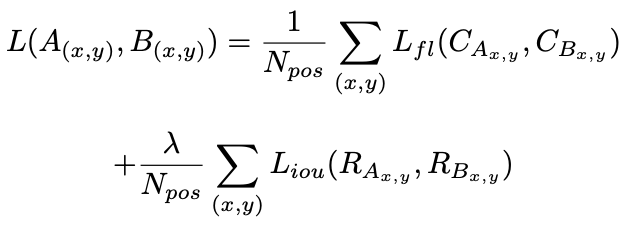
4
实验及可视化
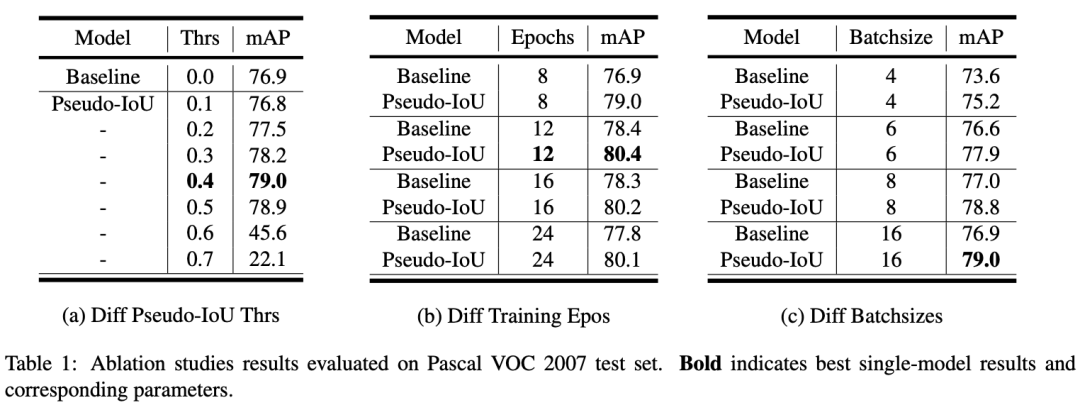
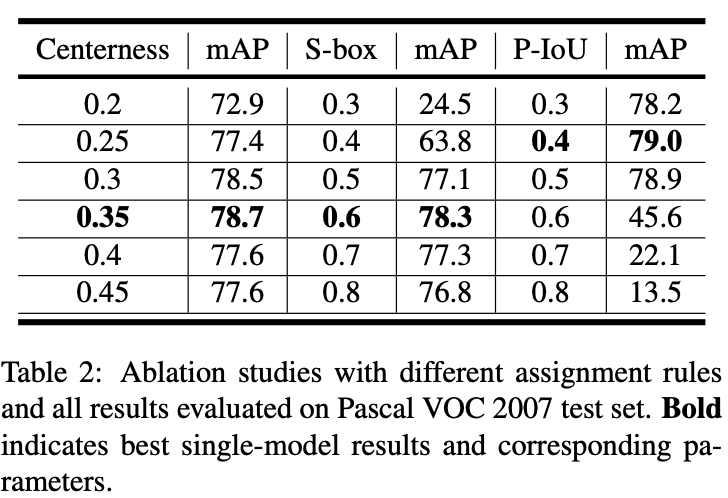
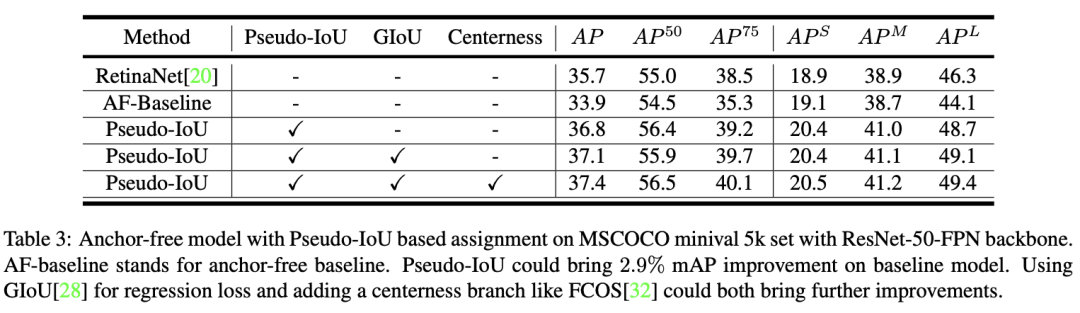
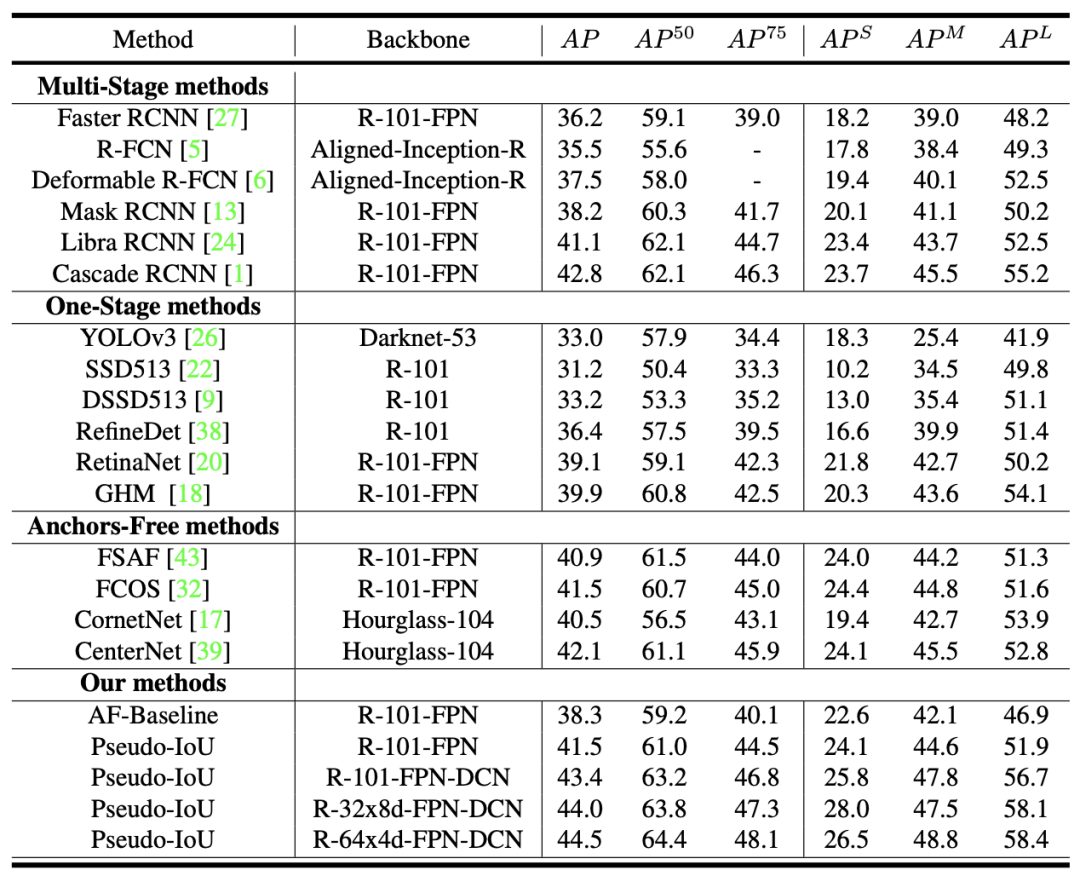

一些检测结果的可视化。第一和第三行图像是Anchor-Free基线的检测结果;第二和第四行图像是Anchor-Free基线,且基于0.5阈值的PIoU度量进行采样的检测结果。如检测结果所示,新提出的方法产生的假阳性更少,定位更准确。
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
源码下载| 回复“PIOU”获取源码下载
往期推荐
????
















 2975
2975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











