






关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
获取论文:关注并回复“GD”
计算机视觉研究院专栏
作者:Edison_G
在传统的目标检测框架中,从图像识别模型继承的主干网络提取深度潜在特征,然后neck模块融合这些潜在特征以捕获不同尺度的信息。
01

前言

由于目标检测中的分辨率比图像识别中的分辨率大得多,因此主干的计算成本通常会主导总推理成本。
这种沉重的主干设计范式主要是由于将图像识别模型转移到目标检测时的历史遗留问题,而不是目标检测的端到端优化设计。在今天分享中,研究者表明这种范式确实导致了次优的目标检测模型。为此,研究者们提出了一种新的Heavy Neck范式GiraffeDet,这是一种用于高效目标检测的类似长颈鹿的网络。GiraffeDet使用极其轻量级的主干和非常深且大的neck部模块,它鼓励不同空间尺度之间的密集信息交换以及同时不同级别的潜在语义。
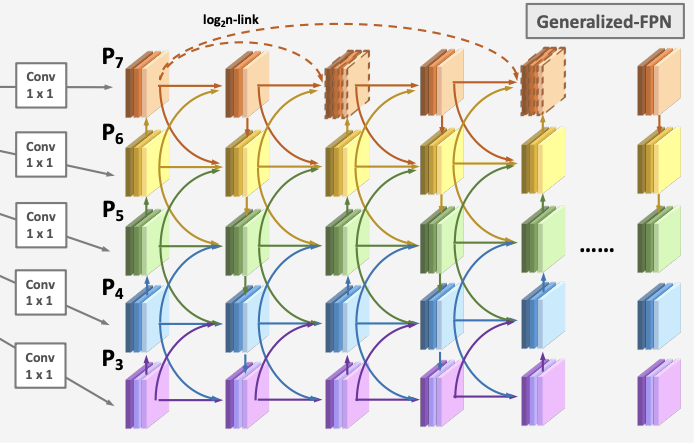
这种设计范式允许检测器即使在网络的早期阶段也能以相同的优先级处理高级语义信息和低级空间信息,使其在检测任务中更加有效。对多个流行的目标检测基准的数值评估表明,GiraffeDet在广泛的资源限制条件下始终优于以前的SOTA模型。
02

相关背景

为了缓解大规模变化带来的问题,一种直观的方法是使用多尺度金字塔策略进行训练和测试。(Singh & Davis, 2018【An analysis of scale invariance in object detection snip】)的工作在图像金字塔的相同尺度上训练和测试检测器,并选择性地反向传播不同大小的目标实例的梯度作为图像尺度的函数。尽管这种方法提高了大多数现有基于CNN的方法的检测性能,但它不是很实用,因为图像金字塔方法处理每个比例图像,这在计算上可能是昂贵的。此外,当使用预训练的分类主干时,分类和检测数据集之间的目标规模仍然是域转移的另一个挑战。或者,提出了特征金字塔网络来逼近具有较低计算成本的图像金字塔。
最近的方法仍然依赖于优越的主干设计,但高级特征和低级特征之间的信息交换不足。例如,一些工作通过自下而上的路径增强在较低层中使用准确的定位信号增强了整个特征层次结构,但是这种自下而上的路径设计可能缺乏高级语义信息和低级空间信息之间的交换。针对以上挑战,本任务提出以下两个问题:
Is the backbone of the image classification task indispensable in a detection model?
What types of multi-scale representations are effective for detection tasks?
03

新框架方法

尽管已经进行了广泛的研究来研究有效的目标检测,但大规模变化仍然是一个挑战。为了有效地实现充分的多尺度信息交换的目标,研究者提出了用于高效目标检测的GiraffeDet,“giraffe”由轻量级空间到深度链、广义FPN和预测网络组成。总体框架如下图所示,它在很大程度上遵循单阶段检测器范式。
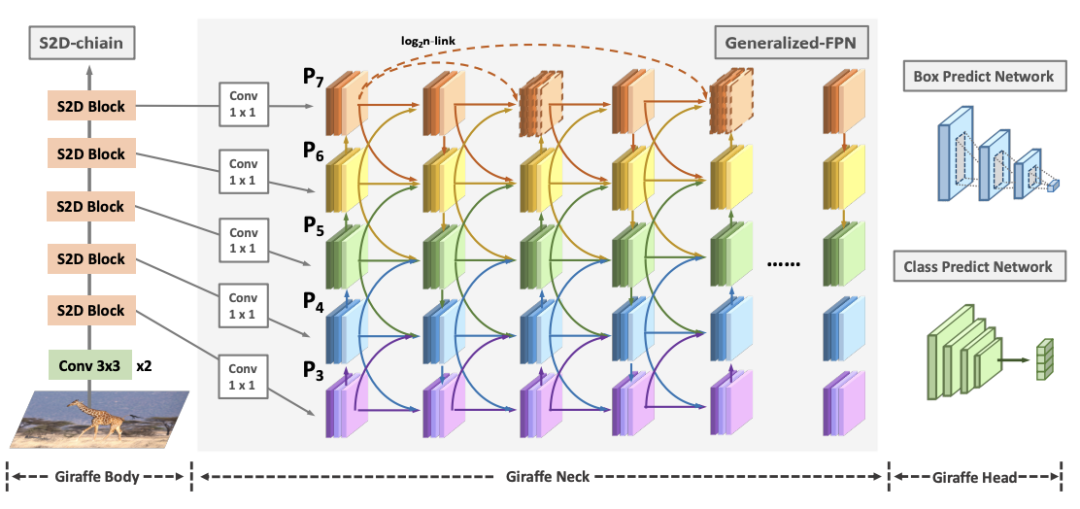
LIGHTWEIGHT SPACE-TO-DEPTH CHAIN
大多数特征金字塔网络都应用传统的基于CNN的网络作为主干来提取多尺度特征图,甚至学习信息交换。然而,随着CNN的发展,最近的主干变得更加沉重,使用它们的计算成本很高。
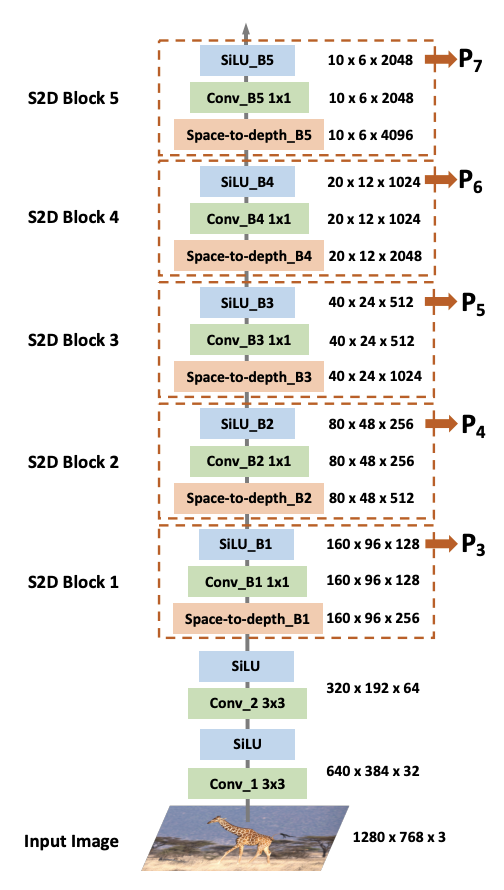
Space-to-depth chain
此外,最近应用的主干主要是在分类数据集上预训练的,例如ResNet50在ImageNet上预训练,我们认为这些预训练的主干不适合检测任务,仍然是域转移问题。或者FPN更强调高级语义和低级空间信息交换。因此,我们假设FPN在目标检测模型中比传统主干更重要。
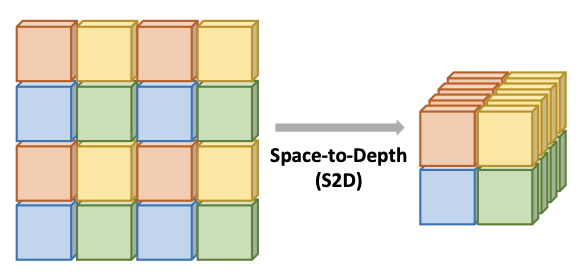
空间到深度转换的图示,S2D操作将激活从空间维度移动到通道维度
GENERALIZED-FPN
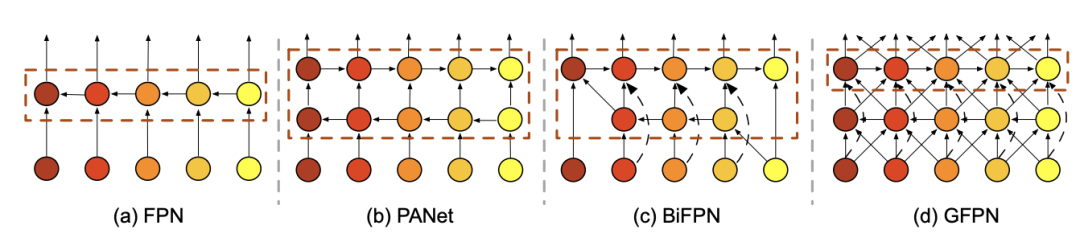
在特征金字塔网络中,多尺度特征融合旨在聚合从主干中提取的不同分辨率的特征。上图显示了特征金字塔网络设计的演变。传统的FPN引入了一种自上而下的路径来融合从第3级到第7级的多尺度特征。考虑到单向信息流的限制,PANet增加了一个额外的自下而上的路径聚合网络,但计算成本更高。此外BiFPN删除了只有一个输入边的节点,并在同一级别上从原始输入中添加额外的边。然而,我们观察到以前的方法只关注特征融合,但缺乏内部块连接。因此,我们设计了一种新的路径融合,包括跳层和跨尺度连接,如图(d) 所示。

跳层连接。与其他连接方法相比,跳跃连接在反向传播过程中特征层之间的距离较短。为了减少如此沉重的“长颈鹿”颈部的梯度消失,我们提出了两种特征链接方法:我们提出的GFPN中的Dense-Link和log2n-Link,如上图所示。
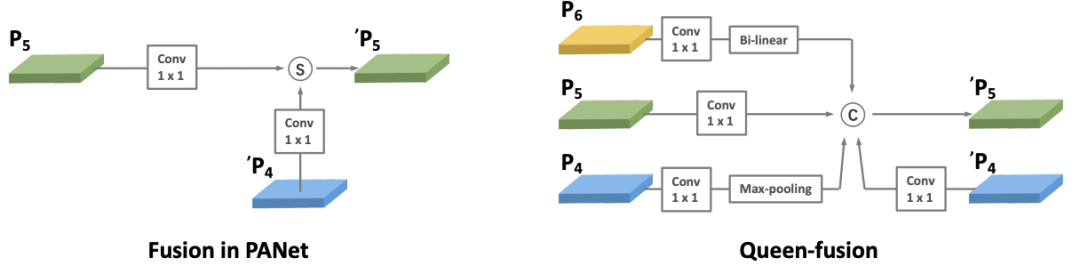
PANet与我们在GFPN中的Queen-fusion 之间的跨尺度连接示意图。S和C表示求和和级联融合风格,Pk表示下一层的节点。
04

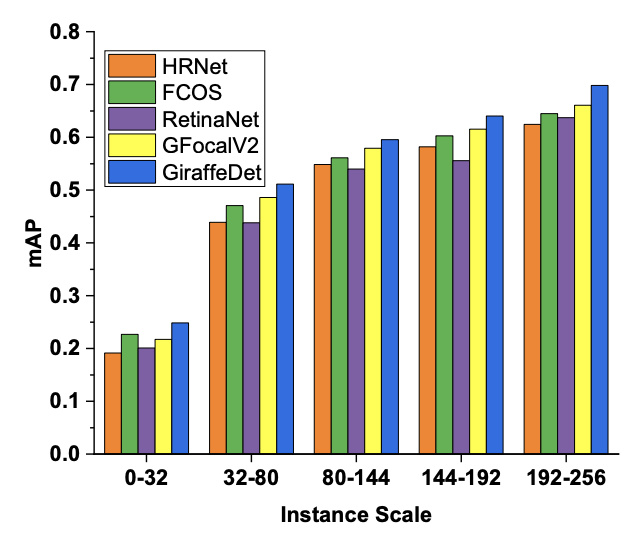
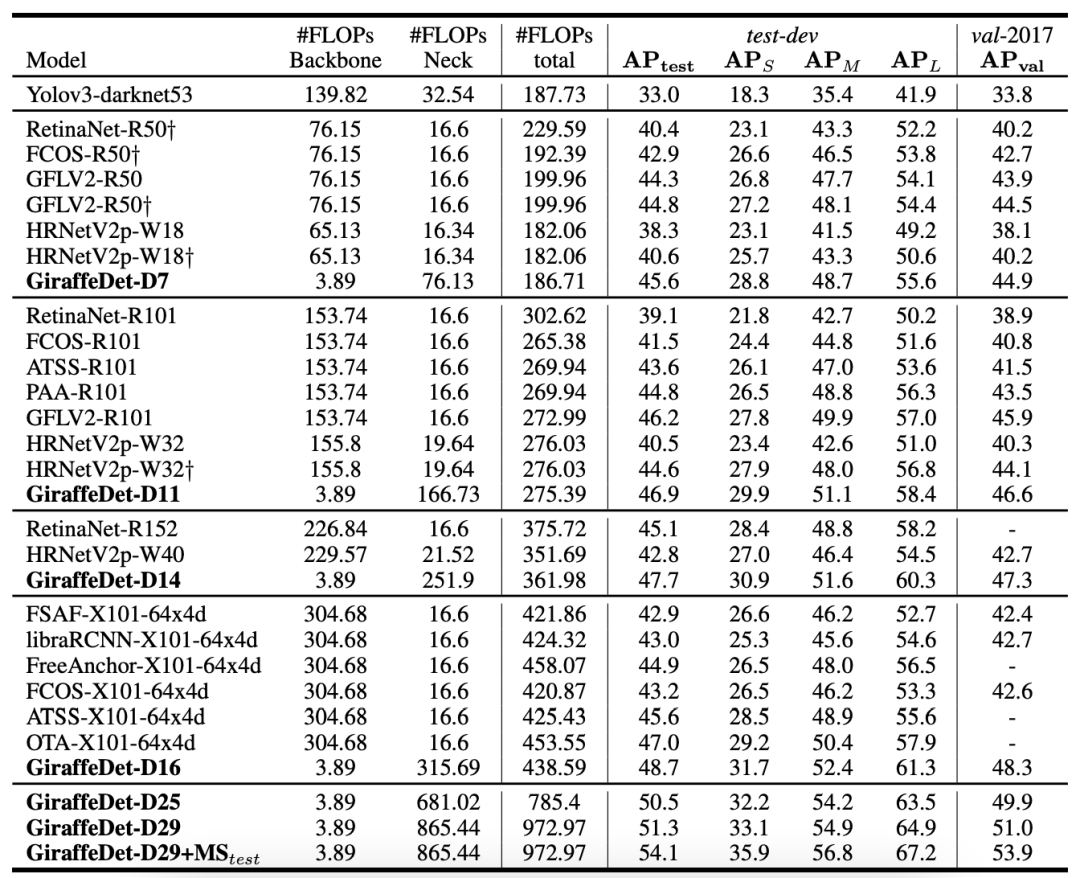
实验及可视化


© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗
















 849
849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











