








目标检测目前模型基本是Backbone+Neck+Head的一个结构,该文章介绍Neck模块。
🎏目录
🎈1 背景介绍
🎄1.1 原因
🎄1.2 Neck进化史
🎈2 Naive-Neck
🎈3 FPN
🎄3.1 图像金字塔
🎄3.2 FPN
🎃3.2.1 方案(a)
🎃3.2.2 方案(b)
🎃3.2.3 方案(c)
🎃3.2.4 方案(d)
🎈4 PAN
🎈5 YOLOF中的Neck
🎄5.1 分治
🎄5.2 问题分析
🎄5.3 匹配目标尺度问题
🎄5.4 正样本不均衡问题
1 ✨背景介绍
由于物体在图像中的大小和位置是不确定的,因此需要一种机制来处理不同尺度和大小的目标。
比如现在的很多网络都使用了利用单个高层特征(比如说Faster R-CNN利用下采样四倍的卷积层——Conv4,进行后续的物体的分类和bounding box的回归),但是这样做有一个明显的缺陷——即小物体本身具有的像素信息较少,在下采样的过程中极易被丢失。
1.1 🎃原因
出现上述问题的原因主要有两个:
- 高层网络/高层特征层虽然能响应语义特征,但是由于Feature Map的尺寸太小,拥有的几何信息并不多,不利于目标的检测。浅层网络/低层特征层虽然包含比较多的几何信息,但是图像的语义特征并不多,不利于图像的分类。这个问题在小目标检测中更为突出。
- 高层特征层,包含更多的语义信息,但是分辨率会降低,很容易忽略小目标。
因此,我们需要合并深层和浅层网络(Neck模块)解决这个问题。
1.2 🎈Neck进化史
Neck网络主要分为Naive-Neck以及FPN系列:
- Naive-Neck就是抽取网络在不同层级的输出,然后用不同层检测不同大小的目标。其典型代表是大家熟悉的SSD网络。
- FPN系列主要是FPN及其相关变种如PAN、BiFPN、GFPN、NAS-FPN等。
目前在 Neck 上的研究主流大多都是基于 FPN 的改进,所以后续我们也会主要就 FPN 系列进行展开
介绍。
✨2 Naive-Neck
SSD网络结构图:
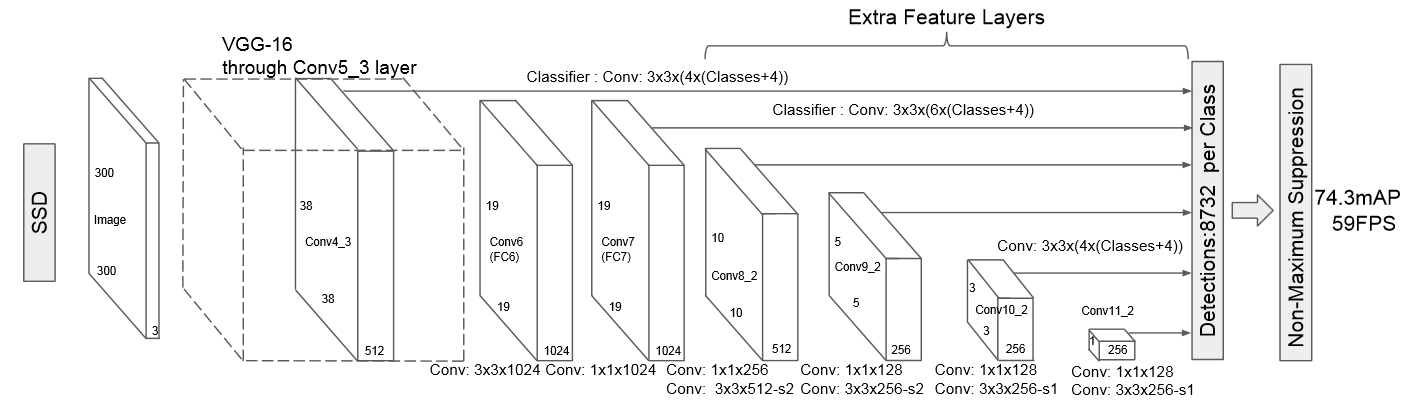
可以明显看到其就是抽取网络在不同层级的输出进行目标的检测。
这样做在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不用进行多余的前向操作),速度更快,又提高了算法的检测性能。但是由于很多的特征都是从较浅的层获得的,语义信息不足,对小物体的检测很差。
✨3 FPN
FPN借鉴了图像金字塔的思想,提出了四种方案。
🎈3.1 图像金字塔

图像金字塔是由一幅图像的多个不同分辨率的子图构成的图像集合。其实就相当于输入一张图像(第0层),通过缩放图像(不是下采样,提取特征)逐渐降低图像分辨率,最终形成如上图所示的“金字塔”。
🎃3.2 FPN

FPN提出了上述四种方案(最后一种称为FPN)
🍕3.2.1 方案(a)

上面这张图中,左侧部分可以称为一个图像金字塔,右侧称为特征金字塔。特征金字塔由图像金字塔生成。
上图中,对每一种尺度的图像进行特征提取,能够产生多尺度的特征表示,并且所有等级的特征图都具有较强的语义信息,甚至包括一些高分辨率的特征图。但是,缺点也很明显:
- 推理时间大幅度增加;
- 由于内存占用巨大,用图像金字塔的形式训练一个端到端的深度神经网络变得不可行;
- 如果只在测试阶段使用图像金字塔,那么,由于训练时,网络只是针对于某一个特点的分辨率进行训练,推理时运用图像金字塔,可能会在训练与推理时产生“矛盾”。
🎄3.2.2 方案(b)

不断利用卷积进行下采样。并采用了高层特征图进行分类和预测,没有和低层信息进行融合。
上图这样,速度快、内存少。但是,仅关注深层网络中最后一层的特征,却忽略了其它层的特征。
🍔3.2.3 方案(C)

SSD中使用的方案,具体见第二节。
✨3.2.4 方案(d)
该方案才是真正被称为FPN的结构。

为了解决上述问题,假设每一步中像素变化为2倍活1/2倍,上述算法中图像像素的变化如下:
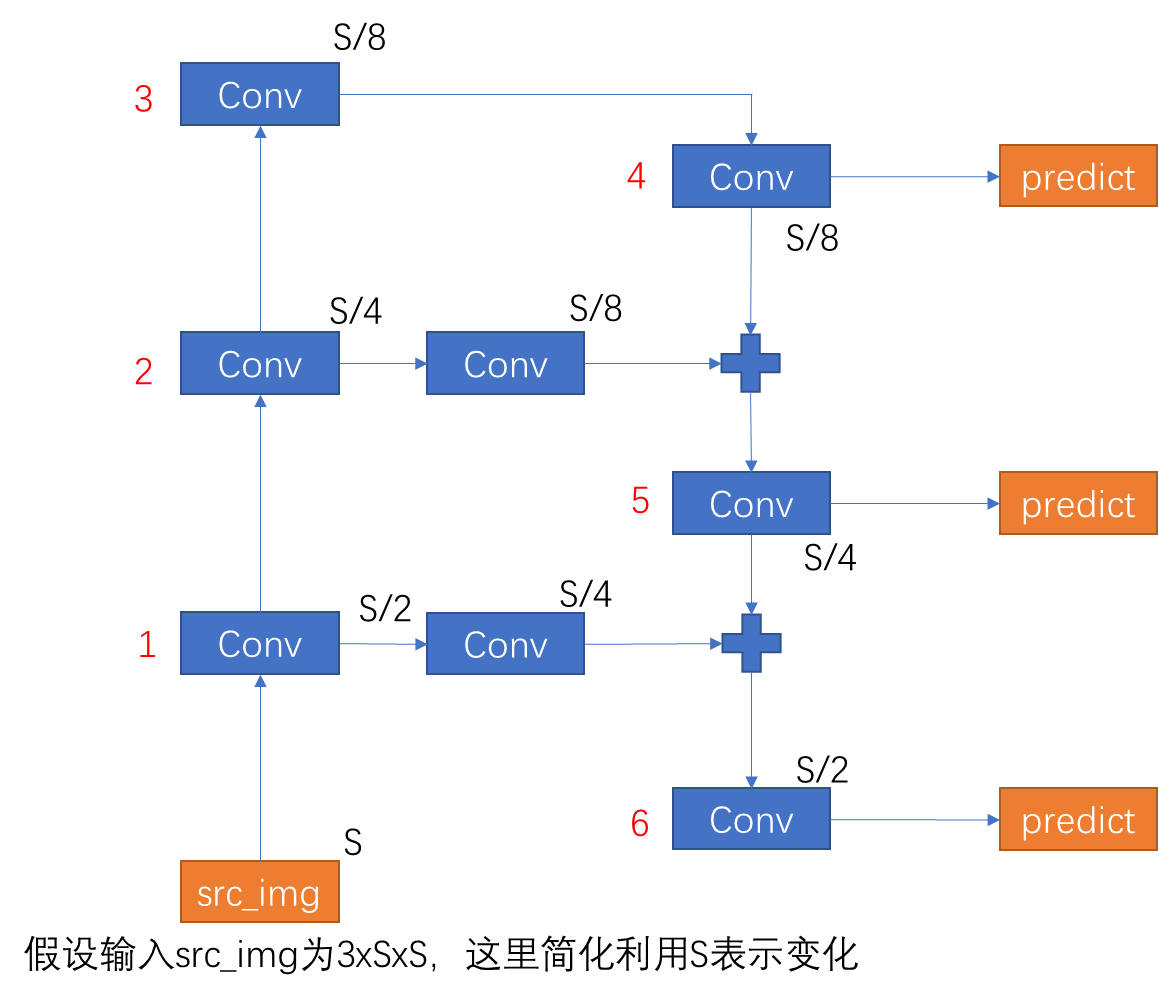
1步-3步进行三次特征提取,每次分辨率变成原来的1/2,3步-4步进行一次分辨率不变化的卷积操作,4步-5步是将2步的卷积操作至与5步的相同大小合并再进行卷积操作。5步-6步与4步-5步类似。
除此之外,FPN由许多的变种,下面总结一下
✨4 PAN
FPN是自上向下的一个特征金字塔,把高层的强语义特征传递下来,对整个金字塔进行增强。不过浅层获取的局部纹理、模式等信息却没有有效的传递到深层特征。
PAN针对这一点,在FPN的后面添加一个自下向上的金字塔,将低层的定位特征传递上去。这样形成的金字塔既结合了语义信息又拥有定位信息,“双杀”。
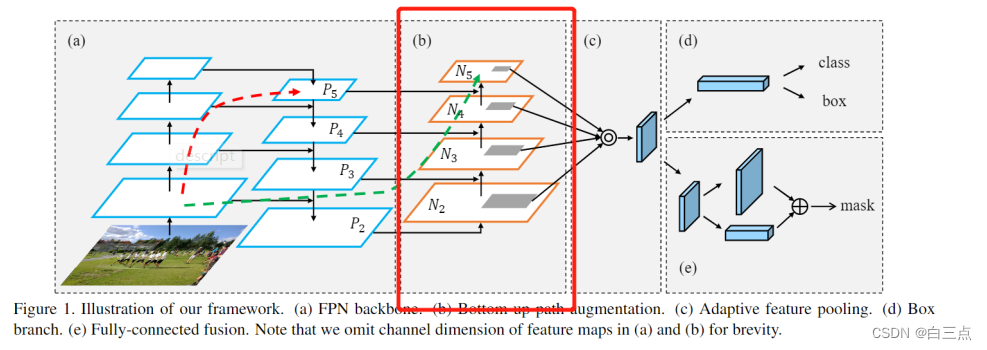
除此之外,我了解到的还有NAS-FPN和BiFPN。同时以YOLOF为代表,响起了不同的声音。
✨5 YOLOF中的Neck
论文地址
YOLOF与YOLO简称很像,但实际上没有什么关系。YOLOF主要针对FPN进行了改进:
作者认为,FPN最成功之处在于将优化问题分治而不是多尺度特征融合。但FPN为检测器带来了计算以及内存的额外开销并且让检测器结构变得复杂。
为了解决这些问题,从优化角度,提出了一种只利用一级特征进行检测的方法来替代复杂的特征金字塔解决这个问题。
🍔5.1 分治
分治即,输出不同层级的特征图,在不同层级的特征图上检测不同尺度的目标。
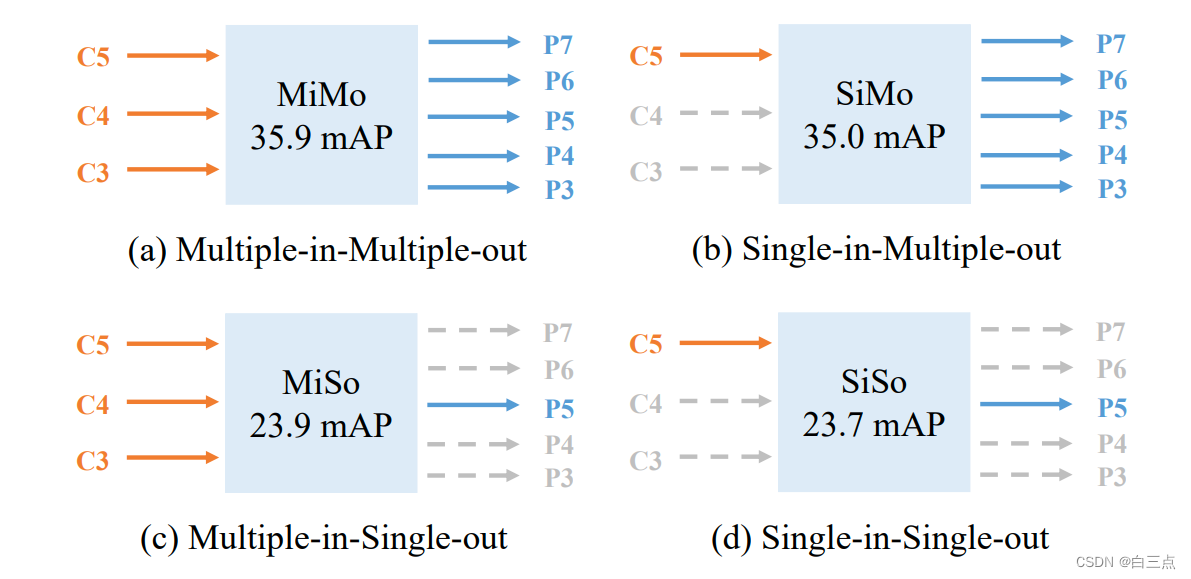
FPN视作一个多进多出(Multiple-in-Multiple-out,MiMo)编码器,如上图(a)。
为了验证自己的猜想,作者对MiMo(多进多出)、单进多出(SiMo)、多进单出(MiSo)和单进单出(SiSo)编码器进行了对比实验,结果是MiMo 与 SiMo 的 mAP 相差无几,但 MiSo 和 SiSo 性能却降低了很多。
🎄5.2 问题分析
上面提到,FPN相当于多进多出编译器,即MiMo。作者希望采用简洁的方式代替FPN,即只利用一级特征进行检测的方法,相当于上图SiSo,性能与MiMo有较大区别。
作者认为这种差异的主要原因有:
- 与C5特征图感受野匹配的目标尺度范围是有限的,这阻碍了不同尺度目标的检测表现
- 单级特征图上稀疏anchor生成策略造成的正样本不均衡问题
🎃5.3 匹配目标尺度问题
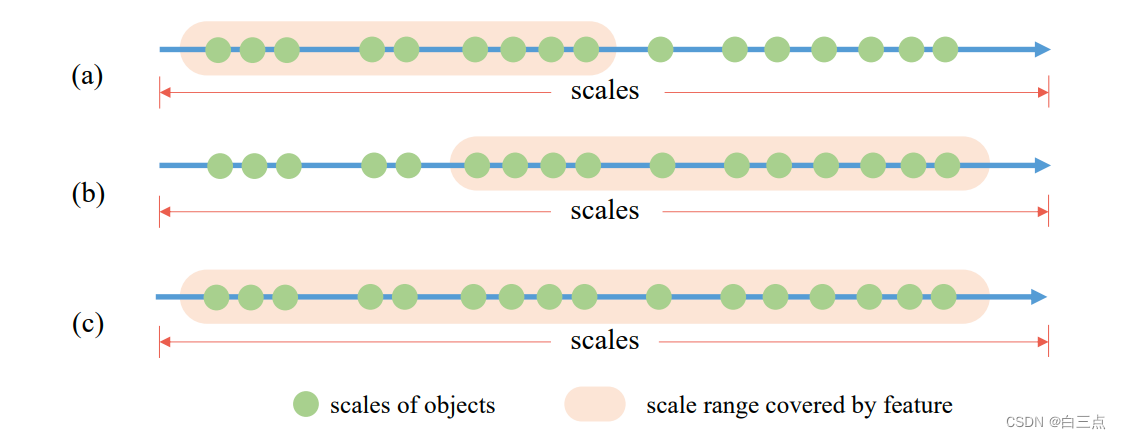
SiSo结构只能输出固定感受野单级别的特征图,如图(a)。为了解决这个问题,作者做了两次改进。
作者首先通过堆叠标准卷积和膨胀卷积增大感受野。但是,增大感受野过程相当于将一个大于1的因子乘以原来覆盖的所有尺度,该方案可视化后如图(b),仍不能覆盖所有目标尺度的特征图。
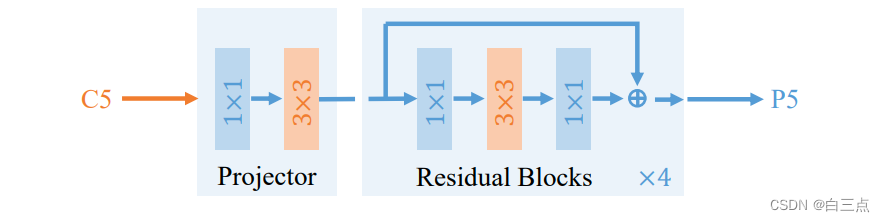
之后,作者将原始特征图和扩大感受野的特征图加到一起,即借鉴残差的思想。形成了最终的解决方案——Dilated Encoder:
🎆5.4 正样本不均衡问题
采用SiSo编码器时,由于特征图减少,anchor的数量比MiMo编码器中的anchor的数量减少了很多,从100k减少到5k,导致anchor非常稀疏。对稀疏的Anchor采用Max-IoU匹配,大的GT会比小的GT产生更多的Anchor,从而造成正样本不均衡的问题。
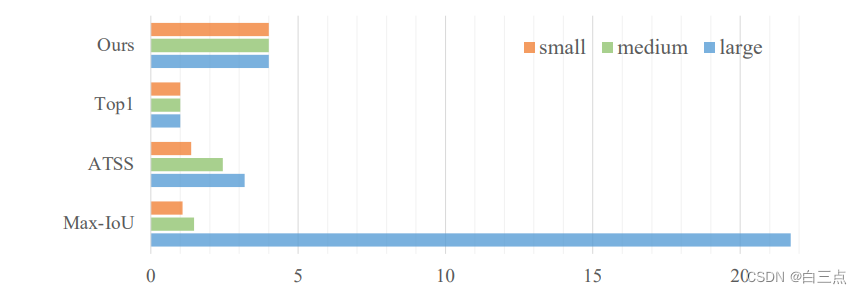
上述正样本不均衡的问题会导致,网络更多的关注大目标,从而忽略小目标。为此,作者设计Uniform Matching的方法:
- 为了确保对大样本和小样本取得相同数量的Anchor,对每个GT,取距离其最近的k个anchor作为正 anchor
- 然后再设置阈值来过滤大IoU的负样本和小IoU的正样本

















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











