





Meta-RL是针对强化学习任务的元学习。在对任务分布进行训练后,agent能够通过开发一种新的具有内部活动动态的RL算法解决新任务。这篇文章从meta-RL的起源开始,然后深入研究meta-RL的三个关键组成部分。
在之前关于元学习的文章中,这个问题主要是在 few-shot 分类的背景下定义的。在这里,我想探讨更多的案例,当我们试图通过开发一个 agent 来“元学习”强化学习(RL)任务,可以快速有效地解决看不见的任务。
总结一下,一个好的元学习模型应该能够推广到训练中从未遇到过的新任务或新环境中。adaption 过程,本质上是一个小型的学习过程,在测试中进行的是对新配置的有限接触。即使没有任何显式的 fine-tuning (在可训练变量上没有梯度反向传播),元学习模型也会自动调整内部隐藏状态进行学习。
训练RL算法有时是出了名的困难。如果元学习代理能够变得如此聪明,使得可解决的、看不见的任务的分布变得极其广泛,那么我们就朝着通用方法的方向迈进了——本质上就是构建一个“大脑”,它可以解决各种各样的RL问题,而无需太多的人为干预或人工特征工程。听起来很神奇,对吧?💖
目录
On the Origin of Meta-RL
Back in 2001
在阅读Wang et al., 2016时,我遇到了Hochreiter et al.在2001年写的一篇论文。虽然这个想法是为监督学习而提出的,但它与当前的元学习学习方法有很多相似之处。
 图1所示。元学习系统包括监督系统和隶属系统。从属系统是一个循环神经网络,以当前时间步长的观测值xt和上一个时间步长的标号yt−1作为输入。(图像来源:Hochreiter等人,2001)
图1所示。元学习系统包括监督系统和隶属系统。从属系统是一个循环神经网络,以当前时间步长的观测值xt和上一个时间步长的标号yt−1作为输入。(图像来源:Hochreiter等人,2001)
Hochreiter的元学习模型是一个带有LSTM单元的循环网络。LSTM是一个很好的选择,因为它可以内在化输入历史,并通过BPTT有效地调优自己的权重。训练数据包含K个序列,每个序列由目标函数fk(.)生成的N个样本组成,K =1,…,K,
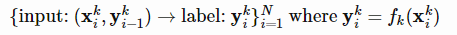
注意,最后一个标签yki−1也作为辅助输入提供,以便函数可以学习所给出的映射。
在二维二次函数的译码实验中,
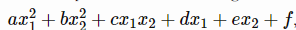
随机从[- 1,1]中选取系数a-f,该元学习系统在只看到~35个示例后就可以逼近函数。
Proposal in 2016
在DL的现代,Wang et al.(2016)和Duan et al.(2017)同时提出了非常相似的Meta-RL的思想(在第二篇论文中称为RL^2)。元rl模型是通过mdp的分布进行训练的,在测试时,它能够快速学会解决新任务。元rl的目标是雄心勃勃的,向通用算法又迈进了一步。
Define Meta-RL
元强化学习,简而言之,就是在强化学习领域做元学习。通常,训练和测试任务是不同的,但来自同一个问题系列;即,论文中的实验包括不同奖励概率的多臂强盗、不同布局的迷宫、模拟器中相同但物理参数不同的机器人等。
Formulation
假设我们有一个任务分布,每个任务都定义为MDP(马尔可夫决策过程),Mi∈M。MDP由一个4元组决定,Mi= = S, a,Pi,Ri⟩:
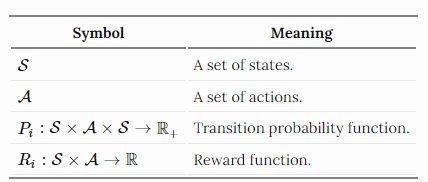
(RL^2论文在MDP元组中增加了一个额外的时间参数T,以强调每个MDP都应该有一个有限的视界。)
注意,上面使用了公共状态S和动作空间A,因此(随机)策略πθ:S×A→R+可以得到不同任务间兼容的输入。测试任务从相同的分布M或稍作修改的版本中抽样。

图2所示。元rl的说明,包含两个优化循环。外层循环在每次迭代中对新环境进行采样,并调整决定代理行为的参数。在内部循环中,代理与环境相互作用,并优化以获得最大的回报。(图像来源:Botvinick等人,2019年)
Main Differences from RL
meta-RL的整体配置与普通的RL算法非常相似,除了当前状态st之外,最后一个奖励rt−1和在−1处的最后一个动作也被纳入策略观察。
在RL中:πθ(st)→a上的分布
在元rl中:πθ(at−1,rt−1,st)→a上的分布
此设计的目的是将历史记录输入到模型中,以便策略能够内化当前MDP中状态、奖励和行动之间的动态,并相应地调整其策略。这与Hochreiter系统中的设置是一致的。meta-RL和RL^2都实现了LSTM策略,LSTM的隐藏状态作为轨迹跟踪特征的内存。因为策略是周期性的,所以不需要显式地将最后一个状态作为输入。
培训流程如下:
- 采样一个 MDP : Mi∈M;
- 重置模型的隐藏状态;
- 收集多个轨迹,更新模型权重;
- 重复步骤1。

图3所示。在meta-RL论文中,不同的演员-评论家体系结构都使用了一个循环模型。最后的奖励和最后的行动是额外的输入。观察结果要么作为一个one-hot vector,要么通过编码器模型后作为一个嵌入向量输入LSTM。(图片来源:Wang et al., 2016)

图4所示。如RL^2论文所述,说明了模型在训练时间内与一系列MDP交互的过程。(图片来源:Duan等人,2017)
Key Components
在Meta-RL中有三个关键组件:
⭐A Model with Memory
递归神经网络保持一种隐状态。因此,它可以通过在rollout过程中更新隐藏状态来获取和记忆当前任务的知识。如果没有Memory,meta-RL将无法工作。
⭐Meta-learning Algorithm
元学习算法指的是我们如何更新模型权值来优化,以便在测试时快速解决一个看不见的任务。在Meta-RL和RL^2两篇论文中,元学习算法都是LSTM的普通梯度下降更新,在MDPs的切换之间隐藏状态重置。
⭐A Distribution of MDPs
虽然 agent 在训练期间暴露于各种环境和任务中,但它必须学会如何适应不同的MDP。
根据Botvinick等人(2019),RL训练缓慢的一个原因是弱归纳偏差(=“学习者在没有遇到输入的情况下预测输出的一组假设”)。作为一般的ML规则,一个具有较弱的归纳偏差的学习算法将能够掌握更大范围的方差,但通常会较低的样本效率。因此,缩小归纳偏差较大的假设有助于提高学习速度。
在meta-RL中,我们从任务分配中施加某些类型的归纳偏差,并将它们存储在记忆中。在测试时采用哪种归纳偏差取决于算法。这三个关键组成部分共同描述了meta-RL的一个引人注目的观点:调整循环网络的权值是缓慢的,但它允许模型通过在其内部活动动态中实现自己的RL算法快速计算出一个新任务。
有趣的是,Meta-RL与Jeff Clune(2019)的AI-GAs(“ai生成算法”)论文中的想法相符。他提出,构建通用人工智能的一个有效方法是让学习尽可能自动化。AI-GAs方法涉及三个支柱:(1)元学习架构,(2)元学习算法,(3)自动生成有效学习环境。
设计良好的循环网络架构的主题有点太宽泛了,不能在这里讨论,所以我将跳过它。接下来,让我们进一步研究另外两个组件:在元rl上下文中的元学习算法,以及如何获取各种训练mdp。
Meta-Learning Algorithms for Meta-RL
我上一篇关于元学习的文章介绍了几种经典的元学习算法。这里我将包括更多与RL相关的内容。
Optimizing Model Weights for Meta-learning
MAML (Finn, et al. 2017)和Reptile (Nichol et al., 2018)都是更新模型参数的方法,以便在新任务上获得良好的泛化性能。请参阅之前关于MAML和Reptile的文章。
Meta-learning Hyperparameters
RL问题中的 return 函数G(n)t或Gλt,涉及到一些经常启发式设置的超参数,如折扣因子γ和 bootstarpping 参数λ。元梯度RL (Xu et al., 2018)将它们视为元参数,η={γ,λ},可以在agent与环境交互时在线调整和学习。因此,返回值成为η的函数,并随着时间的推移动态地适应特定的任务。
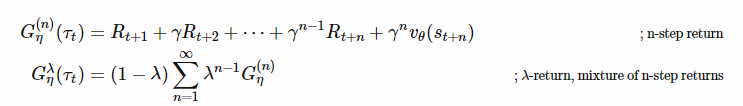
在训练过程中,我们希望将梯度作为手头所有信息的函数来更新政策参数,θ ’ =θ+f(τ,θ,η),其中θ为当前模型权值,τ为轨迹序列,η为元参数。
同时,假设我们有一个元目标函数J(τ,θ,η)作为绩效衡量指标。训练过程遵循在线交叉验证的原则,使用一系列连续的经验:
- 从参数θ开始,对第一批样本τ更新策略πθ,得到θ '。
- 然后我们继续运行政策πθ '来收集一组新的经验τ ',只是在时间上连续跟随τ。用一个固定的元参数η¯来测量J(τ ',θ ',η¯)。
- 利用元目标J(τ ',θ ',η¯)w.r.t. η的梯度来更新η:

其中β为η的学习速率。
元梯度RL算法通过将二级梯度项设置为0,I+∂g(τ,θ,η)/∂θ=0简化了计算,这种选择更倾向于元参数η对参数θ的直接影响。最终我们得到:
本文实验采用与TD(λ)算法相同的元目标函数,使逼近值函数vθ(s)与λ-return之间的误差最小:
Meta-learning the Loss Function
在策略梯度算法中,通过向估计的梯度方向更新政策参数θ,使期望总回报最大化(Schulman et al., 2016)。
其中Ψt的候选值包括轨迹返回Gt、Q值Q(st,at)或优势值A(st,at)。对应的策略梯度的替代损失函数可以逆向工程:
这个损失函数是轨迹历史的度量,(s0,a0,r0,…,st,at,rt,…)进化策略梯度(EPG;Houthooft等人,2018)更进一步,将策略梯度损失函数定义为agent过去经验的时间卷积(1-D卷积),Lϕ。loss function network的参数φ经过改进,使代理能够获得更高的回报。
与许多元学习算法相似,EPG有两个优化循环:
- 在内部循环中,agent学习改进其策略πθ。
- 在外部循环中,模型更新loss函数lφ的参数φ。由于没有明确的方法写出收益和损失之间的可微分方程,EPG转向了进化策略(Evolutionary Strategies, ES)。
一般的想法是训练N个agent的种群,使用loss function lφ +σϵi对每个agent进行训练,其中φ参数化,并添加标准差σ的小高斯噪声ϵi ~ N(0,I)。在内环的培训中,EPG跟踪经验历史,并根据每个代理的loss function Lϕ+σϵi更新策略参数:
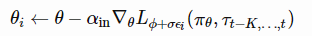
其中,αin为内环的学习率,τt−K,…,t为到当前时间步长t的M个跃迁序列。
一旦内环策略足够成熟,将通过多个随机采样轨迹的平均返回G¯φ +σϵi来评估该策略。最终,我们能够根据NES数值估计φ的梯度(Salimans等人,2017)。在重复这个过程时,同时更新策略参数θ和损失函数权重φ,以实现更高的回报。

其中αout是外环的学习率。
在实践中,损失Lϕ是通过一个普通的策略梯度(例如REINFORCE或PPO)替代损失Lpg来启动的,L^=(1−α)Lϕ+αLpg。weight α在训练过程中逐渐从1到0退火。在测试时,损失函数参数φ保持固定,并在历史经验中计算损失值,以更新策略参数θ。
Meta-learning the Exploration Strategies
exploitation vs exploration的两难困境是研究开发中的一个关键问题。进行探索的常见方法包括ϵ-greedy,行动的随机干扰,或带有行动空间随机性的随机策略。
MAESN (Gupta et al, 2018)是一种算法,可以从之前的经验中学习结构化的动作噪声,以便更好、更有效的探索。简单地在行动中添加随机噪音并不能捕捉到依赖于任务或与时间相关的探索策略。对于第i个任务Mi, MAESN将策略改变为单任务随机变量zi ~ N(μi,σi),得到策略a ~ πθ(a∣s,zi)。潜变量zi只采样一次,在一段时间内固定。从直观上看,潜在变量决定了一种类型的行为(或技能),应该在推出之初进行更多探索,代理将相应地调整其行动。对策略参数和潜在空间进行优化,使总任务报酬最大化。同时,政策也学会了如何利用潜变量进行探索。
损失函数包含学习潜变量和单位高斯先验之间的KL发散,即DKL(N(μi,σi)∥N(0,I))。一方面,它将习得的潜空间限制在与共同先验距离不远的地方。另一方面,它为奖励函数创建了变分证据下界(ELBO)。有趣的是,本文发现每个任务的(μi,σi)通常在收敛时接近先验

图5所示。该策略以潜伏变量zi ~ N(μ,σ)为条件,每集采样一次。每个任务具有不同的潜变量分布超参数(μi,σi),并在外环进行优化。(图片来源:Gupta等人,2018年)
Episodic Control
RL的一个主要问题是它的样本效率低。在RL中,参数调整需要大量的样本和较小的学习步骤,以最大化泛化和避免早期学习的灾难性遗忘(Botvinick et al., 2019)。
情景控制(Lengyel & Dayan, 2008)被提出作为一种解决方案,以避免遗忘和提高泛化,同时训练速度更快。它部分受到基于实例的海马体学习假设的启发。
情景记忆保留了对过去事件的明确记录,并将这些记录直接用作做出新决定的参考点(就像基于度量的元学习一样)。MFEC(无模型情景控制;Blundell et al., 2016),memory被建模为一个大表格,存储状态-动作对(s,a)作为键,对应的Q-value QEC(s,a)作为值。当接收到一个新的观测s时,用非参数的方式估计Q值,取顶部k个最相似样本的平均Q值:
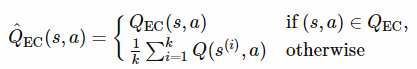
其中s(i),i=1,…,k是到状态s距离最小的top k个状态,然后选择估计Q值最高的动作。然后根据在st收到的返回值更新memory表:
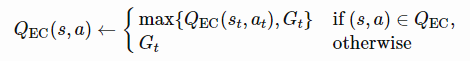
作为一种表格式的RL方法,MFEC的缺点是内存消耗大,并且缺乏在相似状态之间进行泛化的方法。第一个问题可以通过LRU缓存来解决。受基于度量的元学习,特别是匹配网络(Vinyals等人,2016)的启发,泛化问题在后续算法NEC(神经情景控制;Pritzel等人,2016)。
NEC的情景记忆是一个可微分神经字典(DND),其关键是输入图像像素的卷积嵌入向量,值存储估计的Q值。给定一个查询键,输出是顶部相似键值的加权和,其中权重是查询键和字典中所选键之间的标准化内核度量。这听起来像是一种硬注意力机制。

图6 NEC的情景记忆模块图示及可微神经字典的两种操作。(图片来源:Pritzel等人,2016年)
此外,情景性LSTM (Ritter等人,2018)通过DND情景记忆增强了基本的LSTM架构,它将任务上下文嵌入存储为键,而LSTM单元状态存储为值。存储的隐藏状态通过LSTM中相同的门控机制被检索并直接添加到当前的细胞状态:

图7所示。情景LSTM架构的说明。情景记忆的附加结构用粗体标出。(图片来源:Ritter等人,2018年)
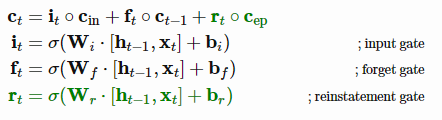
其中ct和ht为隐式,t时刻的细胞状态;它、ft和rt分别为输入门、遗忘门和恢复门;Cep是从情景记忆中提取的细胞状态。新添加的情景记忆组件用绿色标记。
该体系结构通过基于上下文的检索提供了获取先前体验的捷径。同时,显式地将任务依赖体验保存在外部记忆中,以避免遗忘。在本文中,所有的实验都手工设计了上下文向量。如何为更自由的任务构建有效的任务上下文嵌入格式将是一个有趣的话题。
总的来说,情景控制的能力受到环境复杂性的限制。在真实世界的任务中,代理很少会重复访问完全相同的状态,因此正确编码这些状态至关重要。学习后的嵌入空间将观测数据压缩到一个更低维的空间中,同时该空间中两种接近的状态预计需要类似的策略。
Training Task Acquisition
在三个关键组成部分中,如何设计一个适当的任务分配是研究较少的,可能是最具体的元rl本身。如上所述,每个任务都是一个MDP: Mi= =< S, a,Pi,Ri>∈M。我们可以通过修改来构建一个mdp的distribution版:
- 奖励配置:在不同的任务中,相同的行为在Ri看来可能会得到不同的奖励。
- 或者,环境:过渡函数Pi可以通过初始化环境在不同状态之间的变化来重新定义。
Task Generation by Domain Randomization
在模拟器中随机化参数是一种通过修改过渡函数来获得任务的简单方法。如果有兴趣进一步学习,请查看我上一篇关于领域随机化的文章。
Evolutionary Algorithm on Environment Generation
进化算法是一种基于自然选择的无梯度启发式优化方法。解决方案的种群遵循评估、选择、繁殖和突变的循环。最终,好的解决方案会存活下来并被选中。
POET (Wang et al, 2019)是一个基于进化算法的框架,试图在问题本身得到解决的同时生成任务。POET的实现只是专门为简单的2D双足步行环境设计的,但它指出了一个有趣的方向。值得注意的是,进化算法在深度学习中有一些引人注目的应用,如EPG和PBT(基于人口的训练;Jaderberg等人,2017)。

图8所示。一个双足行走环境的例子(上)和POET的概述(下)。(图片来源POET博客)
2D双足行走环境正在演变:从简单的平面到更加困难的小道,有潜在的缝隙、树桩和粗糙的地形。POET将环境挑战的产生和主体的优化结合在一起,以便(a)选择能够解决当前挑战的主体,(b)将环境演化为可解决的。该算法维护一个环境-agent对列表,并重复如下内容:
- 突变:从当前活动的环境中生成新的环境。请注意,这里的突变操作类型只是为双足行走者创建的,而新的环境将需要一组新的配置。
- 优化:在各自的环境中训练成对的代理。
- 选择:定期尝试将当前代理从一个环境转移到另一个环境。为每个环境复制和更新性能最好的代理。直觉是,在一个环境中学习到的技能可能对另一个环境有帮助。
上面的过程与PBT非常相似,但是PBT突变并演化出超参数。POET在一定程度上是在进行域随机化,因为所有的空隙、树桩和地形粗糙度都是由一些随机化概率参数控制的。与DR不同的是,agent不会一下子暴露在完全随机的困难环境中,而是按照进化算法设置的课程逐步学习。
Learning with Random Rewards
没有奖励函数R的MDP称为受控马尔可夫过程(Controlled Markov process, CMP)。给定预定义的CMP, S, a,P⟩,我们可以通过生成一组奖励函数R来获得各种任务,这些函数R鼓励训练有效的元学习策略。
Gupta等人(2018)提出了两种无监督方法来增加CMP背景下的任务分配。假设每个任务都有一个潜在变量z ~ p(z),它参数化/决定一个奖励函数:rz(s)=logD(z|s),其中一个“鉴别器”函数D(.)被用来从状态中提取潜在变量。本文描述了两种构造鉴别函数的方法:
-
样本随机加权鉴别器的ϕrand(z∣s)。
-
学习一个鉴别器函数来鼓励多样性驱动的探索。该方法在另一篇姐妹论文“DIAYN”(Eysenbach et al., 2018)中有更详细的介绍。
DIAYN是“多样性就是你所需要的”的缩写,是一个鼓励学习有用技能的框架,而没有奖励功能。它将潜变量z明确地建模为一种技能嵌入,并使策略条件为z,加上状态s πθ(a∣s,z)。(好吧,这部分与MAESN相同,这并不令人意外,因为这两篇论文来自同一组。)DIAYN的设计是基于以下假设: -
技能应该是多样化的,并引导玩家访问不同的州。→最大化状态与技能之间的相互信息,I(S;Z)
-
技能应该通过状态而不是行动来区分。→以状态I(A;Z∣S)为条件,最小化动作和技能之间的相互信息。
最大化的目标函数如下所示,其中也加入了政策熵,以鼓励多样性:
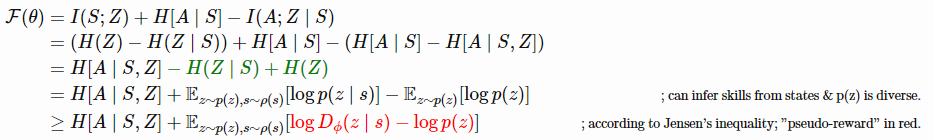
可以从状态和p(z)推断技能是多样的。根据Jensen不等式;“pseudo-reward”红色。
式中I(.)为互信息,H[。是熵的度量。我们不能对所有的状态积分来计算p(z∣s),所以用dn (z∣s)近似它——那是多样性驱动的鉴别函数。

图9所示。DIAYN算法。(图片来源:Eysenbach等人,2019)
一旦学习了鉴别器函数,就可以直接对新的MDP进行采样以进行训练:首先,对潜在变量z ~ p(z)进行采样,并构造一个奖励函数rz(s)=log(D(z|s))。将奖励函数与预定义的CMP配对将创建一个新的MDP。
References
[1] Richard S. Sutton. “The Bitter Lesson.” March 13, 2019.
[2] Sepp Hochreiter, A. Steven Younger, and Peter R. Conwell. “Learning to learn using gradient descent.” Intl. Conf. on Artificial Neural Networks. 2001.
[3] Jane X Wang, et al. “Learning to reinforcement learn.” arXiv preprint arXiv:1611.05763 (2016).
[4] Yan Duan, et al. “RL 2 ^ 2 2: Fast Reinforcement Learning via Slow Reinforcement Learning.” ICLR 2017.
[5] Matthew Botvinick, et al. “Reinforcement Learning, Fast and Slow” Cell Review, Volume 23, Issue 5, P408-422, May 01, 2019.
[6] Jeff Clune. “AI-GAs: AI-generating algorithms, an alternate paradigm for producing general artificial intelligence” arXiv preprint arXiv:1905.10985 (2019).
[7] Zhongwen Xu, et al. “Meta-Gradient Reinforcement Learning” NIPS 2018.
[8] Rein Houthooft, et al. “Evolved Policy Gradients.” NIPS 2018.
[9] Tim Salimans, et al. “Evolution strategies as a scalable alternative to reinforcement learning.” arXiv preprint arXiv:1703.03864 (2017).
[10] Abhishek Gupta, et al. “Meta-Reinforcement Learning of Structured Exploration Strategies.” NIPS 2018.
[11] Alexander Pritzel, et al. “Neural episodic control.” Proc. Intl. Conf. on Machine Learning, Volume 70, 2017.
[12] Charles Blundell, et al. “Model-free episodic control.” arXiv preprint arXiv:1606.04460 (2016).
[13] Samuel Ritter, et al. “Been there, done that: Meta-learning with episodic recall.” ICML, 2018.
[14] Rui Wang et al. “Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions” arXiv preprint arXiv:1901.01753 (2019).
[15] Uber Engineering Blog: “POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments and their Solutions through the Paired Open-Ended Trailblazer.” Jan 8, 2019.
[16] Abhishek Gupta, et al.“Unsupervised meta-learning for Reinforcement Learning” arXiv preprint arXiv:1806.04640 (2018).
[17] Eysenbach, Benjamin, et al. “Diversity is all you need: Learning skills without a reward function.” ICLR 2019.
[18] Max Jaderberg, et al. “Population Based Training of Neural Networks.” arXiv preprint arXiv:1711.09846 (2017).















 5502
5502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









