







 本文探讨了一种使用元梯度算法来学习强化学习超参数的方法,尤其是折扣因子γ和自举参数λ。通过在线调整这些参数,智能体能在与环境交互中适应具体问题并应对变化的学习环境。实验表明,这种方法在Atari游戏中取得了SOTA性能,证明了元梯度算法在动态调整超参数方面的有效性。该算法不仅限于γ和λ,还可应用于其他与回报相关的超参数,为强化学习的超参数优化提供了一种新途径。
本文探讨了一种使用元梯度算法来学习强化学习超参数的方法,尤其是折扣因子γ和自举参数λ。通过在线调整这些参数,智能体能在与环境交互中适应具体问题并应对变化的学习环境。实验表明,这种方法在Atari游戏中取得了SOTA性能,证明了元梯度算法在动态调整超参数方面的有效性。该算法不仅限于γ和λ,还可应用于其他与回报相关的超参数,为强化学习的超参数优化提供了一种新途径。
这篇文章是用元学习算法去学习RL的超参数 η = { γ , λ } \eta=\{\gamma,\lambda\} η={γ,λ}。当然不仅限于这2个超参数,还可以是和回报相关的超参数。
本文的核心思想:我们之前接触过Meta-Learning参数的初始化(MAML、Reptile)以及Meta-Learning参数的更新优化(L2L-by-gd-by-gd、Opt as a model for few-shot learning),那么这篇就是能否Meta-Learning到 η = { γ , λ } \eta=\{\gamma,\lambda\} η={γ,λ}这两个超参数。
这篇文章教会了我们如何去meta-learning超参数,为后续Meta-Learning的发展奠定了基础。可惜的是,作者并没有给出源码。
参考列表:
①Meta-RL系列论文简介
②元梯度强化学习算法
③IMPALA
Meta-Gradient Reinforcement Learning
Abstract
- 对于强化学习而言,最重要的信息就是Agent收到的回报信息,因此作者主要想探究就是最优的回报形式是怎么样的,将回报看成是meta参数 η \eta η的函数,然后用基于梯度的方式来优化、在线调整 η \eta η,从而在智能体与环境的交互中,使得回报既能适应具体问题,又能随着时间动态调整以适应不断变化的学习环境。
- 关于meta参数 η = { γ , λ } \eta=\{\gamma,\lambda\} η={γ,λ},其中 γ \gamma γ是折扣因子, λ \lambda λ是自举参数。
- 作者将本文所产生的新算法在57个Atari游戏上进行实验,最后可以达到sota的表现。从而证明了元梯度强化学习算法可以适用于DRL任务。
1 Meta-Gradient Reinforcement Learning Algorithms
定义更新规则为
f
(
τ
,
θ
,
η
)
f(\tau,\theta,\eta)
f(τ,θ,η),其中
τ
\tau
τ为强化学习中的一条episode:
τ
t
=
{
S
t
,
A
t
,
R
t
+
1
,
⋯
}
\tau_t=\{S_t,A_t,R_{t+1,\cdots}\}
τt={St,At,Rt+1,⋯};
θ
\theta
θ为值函数网络和策略网络的参数(其实个人觉得还是分开来说比较好,但是作者可能为了简便说明,统一用
θ
\theta
θ表示);
η
\eta
η为meta参数。
Meta-Learning有2个角色:Meta-Learner和Learner,我们分别用
θ
\theta
θ和
θ
′
\theta'
θ′表示,因此参考类似于MAML的做法,fast-weights的获得如下所示:
θ
′
=
θ
+
f
(
τ
,
θ
,
η
)
(1)
\theta'=\theta+f(\tau,\theta,\eta)\tag{1}
θ′=θ+f(τ,θ,η)(1)Note:
- 更新规则 f ( ⋅ ) f(\cdot) f(⋅)一般指代学习率 α \alpha α和梯度 ∇ \nabla ∇的乘积。
那么式(1)是如何训练的呢?
作者提出主要是基于在线交叉验证(Sutton,1992)的方式:具体的,RL算法从参数
θ
\theta
θ出发,在first-sample上进行训练,利用采样得到的经验以及式(1)获得fast-weights——
θ
′
\theta'
θ′;然后在subsequent-sample上对
θ
′
\theta'
θ′的表现进行评估验证,然后对参数
η
\eta
η进行更新。整一套流程其实和监督学习里的交叉验证没啥区别。
- First-sample就相当于Meta-Learning中的Support-set;Subsequent-sample就相当于Query-set。
- 2个sample集是互相独立的,分别记为 τ \tau τ和 τ ′ \tau' τ′。
- 训练目标和评价指标分别记为 J ( τ , θ , η ) J(\tau,\theta,\eta) J(τ,θ,η)和 J ′ ( τ ′ , θ ′ , η ′ ) J'(\tau',\theta',\eta') J′(τ′,θ′,η′)。需要注意是RL中一般 J J J都是回报函数,且由于本论文提出的是一种gradient-based算法,故 J J J必须是可微分的,因此值函数的形式不宜采用定义式,而应该是policy-based形式。
- η ′ \eta' η′采用固定的值来做参考。
评估:
由Meta-Learning的评估函数对Meta-Learner参数的更新一般都是建立在Query-set上的:
∂
J
′
(
τ
′
,
θ
′
,
η
′
)
∂
η
=
∂
J
′
(
τ
′
,
θ
′
,
η
′
)
∂
θ
′
⋅
d
θ
′
d
η
(2)
\frac{\partial{J'(\tau',\theta',\eta')}}{\partial{\eta}}=\frac{\partial{J'(\tau',\theta',\eta')}}{\partial{\theta'}}\cdot\frac{\mathrm{d}\theta'}{\mathrm{d}\eta}\tag{2}
∂η∂J′(τ′,θ′,η′)=∂θ′∂J′(τ′,θ′,η′)⋅dηdθ′(2)Note:
- 由于我们现在是为了meta-learning参数 η \eta η,而不是 θ \theta θ,否则就成了MAML了,所以偏导的对象是我们的超参数 { γ , λ } \{\gamma,\lambda\} {γ,λ}。和MAML的还有一个区别是,MAML对于 θ \theta θ的训练并不是online的(具体可查看MAML论文的Algorithm 3第十行,注意这里指的是online而不是on-policy),而本文的元梯度算法对于 η \eta η的训练是online的,即每一个step下,都会在线做出应有的调整。
- d θ ′ d η \frac{\mathrm{d}\theta'}{\mathrm{d}\eta} dηdθ′表明meta参数 η \eta η对fast-weights的影响。
求出式(2)的关键在于求出
d
θ
′
d
η
\frac{\mathrm{d}\theta'}{\mathrm{d}\eta}
dηdθ′:
d
θ
′
d
η
=
d
(
θ
+
f
(
τ
,
θ
,
η
)
)
d
η
=
d
θ
d
η
+
∂
f
(
τ
,
θ
,
η
)
∂
θ
⋅
d
θ
d
η
+
∂
f
(
τ
,
θ
,
η
)
∂
η
=
(
I
+
∂
f
(
τ
,
θ
,
η
)
∂
θ
)
d
θ
d
η
+
∂
f
(
τ
,
θ
,
η
)
∂
η
(3)
\frac{\mathrm{d}\theta'}{\mathrm{d}\eta}=\frac{\mathrm{d}(\theta+f(\tau,\theta,\eta))}{\mathrm{d}\eta}=\frac{\mathrm{d}\theta}{\mathrm{d}\eta}+\frac{\partial{f(\tau,\theta,\eta)}}{\partial{\theta}}\cdot\frac{\mathrm{d}\theta}{\mathrm{d}\eta}+\frac{\partial{f(\tau,\theta,\eta)}}{\partial{\eta}}\\ =(I+\frac{\partial{f(\tau,\theta,\eta)}}{\partial{\theta}})\frac{\mathrm{d}\theta}{\mathrm{d}\eta}+\frac{\partial{f(\tau,\theta,\eta)}}{\partial{\eta}}\tag{3}
dηdθ′=dηd(θ+f(τ,θ,η))=dηdθ+∂θ∂f(τ,θ,η)⋅dηdθ+∂η∂f(τ,θ,η)=(I+∂θ∂f(τ,θ,η))dηdθ+∂η∂f(τ,θ,η)(3)令
μ
=
I
+
∂
f
(
τ
,
θ
,
η
)
∂
θ
z
′
=
d
θ
′
d
η
z
=
d
θ
d
η
\mu=I+\frac{\partial{f(\tau,\theta,\eta)}}{\partial{\theta}}\\ z'=\frac{\mathrm{d}\theta'}{\mathrm{d}\eta}\\ z=\frac{\mathrm{d}\theta}{\mathrm{d}\eta}
μ=I+∂θ∂f(τ,θ,η)z′=dηdθ′z=dηdθ则
z
′
=
μ
z
+
∂
f
(
τ
,
θ
,
η
)
∂
η
(4)
z'=\mu z+\frac{\partial{f(\tau,\theta,\eta)}}{\partial{\eta}}\tag{4}
z′=μz+∂η∂f(τ,θ,η)(4)
当选择让
μ
=
0
\mu=0
μ=0的时候,意味着不用去求二阶偏导数了,求出了
d
θ
′
d
η
\frac{\mathrm{d}\theta'}{\mathrm{d}\eta}
dηdθ′之后,我们就可以使用SGD(Adma等)对
η
\eta
η进行参数更新了:
η
←
η
+
Δ
η
,
Δ
η
=
−
β
⋅
∂
J
′
(
τ
′
,
θ
′
,
η
′
)
∂
θ
′
z
′
(5)
\eta\gets\eta+\Delta\eta,\Delta\eta=-\beta\cdot\frac{\partial{J'(\tau',\theta',\eta')}}{\partial{\theta'}}z'\tag{5}
η←η+Δη,Δη=−β⋅∂θ′∂J′(τ′,θ′,η′)z′(5)Note:
- Δ η \Delta\eta Δη就是表示目标函数对参数的梯度。
- 详细推导如下

1.1 Applying Meta-Gradient to Returns
接下来就要做一些直接结合RL的具体的公式,而不仅限于上面这些符号。
首先需要将回报
g
η
(
τ
t
)
g_\eta(\tau_t)
gη(τt)表示成以meta参数
η
\eta
η为变量的函数的形式,根据我们在value-based系列中的知识,可以写成n-step或者
λ
\lambda
λ-return的形式。
n-step:
g
η
(
τ
t
)
=
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
⋯
γ
n
−
1
+
γ
n
v
θ
(
s
t
+
n
)
(6)
g_\eta(\tau_t)=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots\gamma^{n-1}+\gamma^nv_\theta(s_{t+n})\tag{6}
gη(τt)=Rt+1+γRt+2+γ2Rt+3+⋯γn−1+γnvθ(st+n)(6)
λ
\lambda
λ-return:
g
η
(
τ
t
)
=
R
t
+
1
+
γ
(
1
−
λ
)
v
θ
(
s
t
+
1
)
+
γ
λ
g
η
(
τ
t
+
1
)
(7)
g_\eta(\tau_t)=R_{t+1}+\gamma(1-\lambda)v_\theta(s_{t+1})+\gamma\lambda g_\eta(\tau_{t+1})\tag{7}
gη(τt)=Rt+1+γ(1−λ)vθ(st+1)+γλgη(τt+1)(7)
1.2 Meta-Gradient Prediction
预测其实就是求出估计出值函数的过程,不一定要最优,但是要尽量精确估计。本篇论文采用TD(
λ
\lambda
λ)来做预测。
对于值函数估计一般通过最小二乘损失来表示:
J
(
τ
,
θ
,
η
)
=
1
2
(
g
η
(
τ
)
−
v
θ
(
s
)
)
2
J(\tau,\theta,\eta)=\frac{1}{2}(g_\eta(\tau)-v_\theta(s))^2
J(τ,θ,η)=21(gη(τ)−vθ(s))2,其对
θ
\theta
θ的梯度为:
∂
J
(
τ
,
θ
,
η
)
∂
θ
=
(
g
η
(
τ
)
−
v
θ
(
s
)
)
⋅
∂
v
θ
(
s
)
∂
θ
(8)
\frac{\partial{J(\tau,\theta,\eta)}}{\partial{\theta}}=(g_\eta(\tau)-v_\theta(s))\cdot\frac{\partial{v_\theta(s)}}{\partial{\theta}}\tag{8}
∂θ∂J(τ,θ,η)=(gη(τ)−vθ(s))⋅∂θ∂vθ(s)(8)然后定义
f
(
⋅
)
f(\cdot)
f(⋅):
f
(
τ
,
θ
,
η
)
=
−
α
⋅
∂
J
(
τ
,
θ
,
η
)
∂
θ
(9)
f(\tau,\theta,\eta)=-\alpha\cdot\frac{\partial{J(\tau,\theta,\eta)}}{\partial{\theta}}\tag{9}
f(τ,θ,η)=−α⋅∂θ∂J(τ,θ,η)(9)更新规则
f
f
f我们需要借助SGD去求得,其中
α
\alpha
α为学习率。很自然的,我们接下去一定会回到
Δ
η
\Delta\eta
Δη上:
∂
f
(
τ
,
θ
,
η
)
∂
η
=
−
α
∂
g
η
(
τ
)
∂
η
⋅
∂
v
θ
(
s
)
∂
θ
(10)
\frac{\partial{f(\tau,\theta,\eta)}}{\partial{\eta}}=-\alpha\frac{\partial{g_\eta(\tau)}}{\partial{\eta}}\cdot\frac{\partial{v_\theta(s)}}{\partial{\theta}}\tag{10}
∂η∂f(τ,θ,η)=−α∂η∂gη(τ)⋅∂θ∂vθ(s)(10)预测的核心思想就是通过调整meta参数
η
\eta
η来做到最精确的预测。接下来观察公式(5)和公式(10),还差一部分:
J
′
(
τ
′
,
θ
′
,
η
′
)
=
1
2
(
g
η
′
(
τ
′
)
−
v
θ
′
(
s
′
)
)
2
∂
J
′
(
τ
′
,
θ
′
,
η
′
)
∂
θ
′
=
(
g
η
′
(
τ
′
)
−
v
θ
′
(
s
′
)
)
⋅
∂
v
θ
′
(
s
′
)
∂
θ
′
(11)
J'(\tau',\theta',\eta')=\frac{1}{2}(g_{\eta'}(\tau')-v_{\theta'}(s'))^2\\ \frac{\partial{J'(\tau',\theta',\eta')}}{\partial{\theta'}}=(g_{\eta'}(\tau')-v_{\theta'}(s'))\cdot\frac{\partial{v_{\theta'}(s')}}{\partial{\theta'}}\tag{11}
J′(τ′,θ′,η′)=21(gη′(τ′)−vθ′(s′))2∂θ′∂J′(τ′,θ′,η′)=(gη′(τ′)−vθ′(s′))⋅∂θ′∂vθ′(s′)(11)Note:
- 这里 s ′ s' s′不是下个状态的意思,而是指subsequent-sample上的状态。
- 对于 η ′ \eta' η′通常采用固定形式做reference,如 η ′ = { γ ′ = 1 , λ ′ = 1 } \eta'=\{\gamma'=1,\lambda'=1\} η′={γ′=1,λ′=1}。
总结一下预测的流程:
- 首先在first-sample上使用公式(8)以及公式(10)去求得相关梯度。
- 然后在subsequent-sample上使用公式(11)去求得相关梯度。
- 最后使用公式(5)对 η \eta η进行更新。
1.3 Meta-Gradient Control
规划的另一部分就是控制,说白了就是求最优值,通常我们称预测为策略评估,而控制则是策略提升。
RL常见的比如Q-Learning就是典型的控制算法。这里作者采用了policy-based系列算法中的A2C,这是一种将预测和控制结合在一个更新式子中的Actor-Critic算法,往往我们将策略梯度上述看成是policy-improvement的一种方式。
控制:
目标函数仍是值函数:
−
∂
J
(
τ
,
θ
,
η
)
∂
θ
=
(
g
η
(
τ
)
−
v
θ
(
s
)
)
∂
log
π
θ
(
a
∣
s
)
∂
θ
+
b
(
g
η
(
τ
)
−
v
θ
(
s
)
)
∂
v
θ
(
s
)
∂
θ
+
c
∂
H
(
π
θ
(
⋅
∣
s
)
)
∂
θ
(12)
-\frac{\partial{J(\tau,\theta,\eta)}}{\partial\theta}=(g_\eta(\tau)-v_\theta(s))\frac{\partial{\log\pi_\theta(a|s)}}{\partial{\theta}}+b(g_\eta(\tau)-v_\theta(s))\frac{\partial{v_\theta(s)}}{\partial{\theta}}+c\frac{\partial{H(\pi_\theta(\cdot|s))}}{\partial{\theta}}\tag{12}
−∂θ∂J(τ,θ,η)=(gη(τ)−vθ(s))∂θ∂logπθ(a∣s)+b(gη(τ)−vθ(s))∂θ∂vθ(s)+c∂θ∂H(πθ(⋅∣s))(12)Note:
- 一共分为三部分:第一部分是控制目标;第二部分是预测目标(这里也是我不解的地方,个人认为没必要再做一次预测吧);第三部分是熵,用于增加策略的随机性。
- 参数 b , c b,c b,c表示各个部分在目标函数中的占比。
和预测一样的流程,接下去就是求更新规则及其对meta参数的梯度:
f
(
τ
,
θ
,
η
)
=
−
α
⋅
∂
J
(
τ
,
θ
,
η
)
∂
θ
∂
f
(
τ
,
θ
,
η
)
∂
η
=
α
∂
g
η
(
τ
)
∂
η
[
∂
log
π
θ
(
a
∣
s
)
∂
θ
+
b
∂
v
θ
(
s
)
∂
θ
]
(13)
f(\tau,\theta,\eta)=-\alpha\cdot\frac{\partial{J(\tau,\theta,\eta)}}{\partial{\theta}}\\ \frac{\partial{f(\tau,\theta,\eta)}}{\partial\eta}=\alpha\frac{\partial{g_\eta(\tau)}}{\partial{\eta}}[\frac{\partial{\log\pi_\theta(a|s)}}{\partial{\theta}}+b\frac{\partial{v_\theta(s)}}{\partial{\theta}}]\tag{13}
f(τ,θ,η)=−α⋅∂θ∂J(τ,θ,η)∂η∂f(τ,θ,η)=α∂η∂gη(τ)[∂θ∂logπθ(a∣s)+b∂θ∂vθ(s)](13)Note:
- 同样也是通过
SGD去求得梯度值。
控制的核心思想就是通过调整meta参数
η
\eta
η来最大化提升值函数。接下来观察公式(5)和公式(13),还差一部分:
∂
J
′
(
τ
′
,
θ
′
,
η
′
)
∂
θ
′
=
(
g
η
′
(
τ
′
)
−
v
θ
′
(
s
′
)
)
∂
log
π
θ
′
(
a
∣
s
)
∂
θ
′
(14)
\frac{\partial{J'(\tau',\theta',\eta')}}{\partial\theta'}=(g_{\eta'}(\tau')-v_{\theta'}(s'))\frac{\partial{\log\pi_{\theta'}(a|s)}}{\partial{\theta'}}\tag{14}
∂θ′∂J′(τ′,θ′,η′)=(gη′(τ′)−vθ′(s′))∂θ′∂logπθ′(a∣s)(14)
总结一下控制的流程:
- 首先在first-sample上使用A2C算法公式(12)以及公式(13)去求得相关梯度。
- 然后在subsequent-sample上使用公式(14)去求得相关梯度。
- 最后使用公式(5)对 η \eta η进行更新。
- 另外需要注意的是,控制和预测在文中用了一个字母 J J J表示,但实际上是不一样的。
1.4 Conditioned Value and Policy Functions
这一节主要是将meta参数嵌入到值函数网络和策略网络中,从而来增加回报的稳定性,使得预测也更加准确,对于训练稳定性的增加很有帮助。
为何回报会不稳定呢?
因为我们meta参数是直接和回报挂钩的,而参数的更新是在线更新的。举个例子,比如你在
γ
=
0
\gamma=0
γ=0的时候,有一个不错的回报,但是当
γ
\gamma
γ更新到
γ
=
1
\gamma=1
γ=1之后,你可能会发现接下来的回报值很低,一方面是之前的短视(
γ
=
0
\gamma=0
γ=0)行为造成的。另一方面,
η
∈
[
0
,
1
]
\eta\in[0,1]
η∈[0,1],直接输入网络的话,会造成一定的稀疏性,因此我们可以通过Embedding的方式去解决这个问题:
v
θ
η
(
s
)
=
v
θ
(
[
s
;
e
η
]
)
π
θ
η
(
s
)
=
π
θ
(
[
s
;
e
η
]
)
e
η
=
W
η
η
v_\theta^\eta(s)=v_\theta([s;e_\eta])\\ \pi^\eta_\theta(s)=\pi_\theta([s;e_\eta])\\ e_\eta=W_\eta\eta
vθη(s)=vθ([s;eη])πθη(s)=πθ([s;eη])eη=WηηNote:
- e η e_\eta eη是输入为 η \eta η的嵌入层,PyTorch或者Tf都有方便的实现。
- [ s ; e η ] [s;e_\eta] [s;eη]表示输入维度的堆积合并。
- W η W_\eta Wη是嵌入矩阵参数。
1.5 Meta-Gradient Reinforcement Learning in Practice
这一节讲的是元梯度算法在实现过程中的一些注意点:
- 为了提高计算效率,目标函数的计算最好是每隔n-step计算一次,n步之内只进行 L o s s Loss Loss的累加。
- 采用mini-batch数量的tasks。
- 同一份task可以重复利用2次。举个例子,比如 τ \tau τ被用来做 θ → θ ′ \theta\to\theta' θ→θ′,然后 τ ′ \tau' τ′用在 J ′ J' J′上做 η \eta η的更新。那么作者表达的是接下去同样也可以用 τ ′ \tau' τ′在 J J J上做 θ → θ ′ \theta\to\theta' θ→θ′的更新,然后 τ \tau τ用在 J ′ J' J′上做 η \eta η的更新。这样同一份数据就得到了充分利用。这种做法也特别适合于Meta-Learning算法中样本少得特性。
2 Illustrative Examples
这一节主要展示meta参数
η
=
{
γ
,
λ
}
\eta=\{\gamma,\lambda\}
η={γ,λ}是如何meta-learned到的。
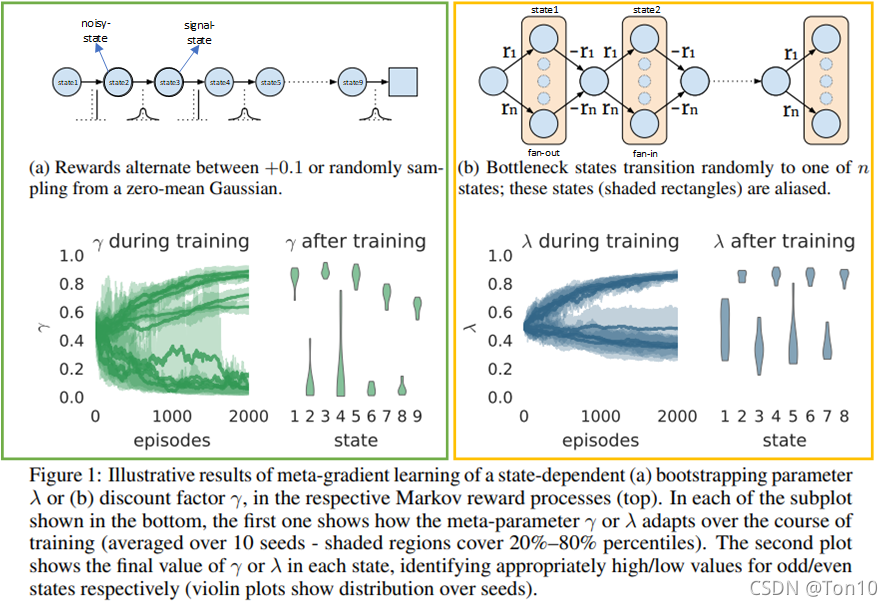 如上图所示,左图是研究衰减系数
γ
\gamma
γ,右图是研究自举参数
λ
\lambda
λ。以左图为例,这是一个10步的MRP(指没有决策动作的MDP),由2种状态交替组成。状态由信号状态与噪声状态组成,奖励有固定奖励
R
=
0.1
R=0.1
R=0.1以及随机奖励
R
∼
N
(
0
,
1
)
R\sim N(0,1)
R∼N(0,1)两种。奇数编号的是信号状态,偶数编号的是噪声状态。
如上图所示,左图是研究衰减系数
γ
\gamma
γ,右图是研究自举参数
λ
\lambda
λ。以左图为例,这是一个10步的MRP(指没有决策动作的MDP),由2种状态交替组成。状态由信号状态与噪声状态组成,奖励有固定奖励
R
=
0.1
R=0.1
R=0.1以及随机奖励
R
∼
N
(
0
,
1
)
R\sim N(0,1)
R∼N(0,1)两种。奇数编号的是信号状态,偶数编号的是噪声状态。
我们的目的是为了确保尽可能去获得较大的固定奖励0.1,而不要噪声奖励(噪声奖励大概率为0,而且还会有负奖励),因此就需要Agent在信号状态的时候保持较高的
γ
\gamma
γ,在噪声状态的时候保持较低的
γ
\gamma
γ,训练结果如绿色框下方图所示,确实如我们分析的那样,奇数状态(signal-state)的
γ
\gamma
γ很高,偶数状态(noise-state)的
γ
\gamma
γ很低。
为什么元梯度算法的训练结果是这样呢?
首先我们要弄清楚
γ
\gamma
γ的意义在于我们要Agent更加注重长远利益,而不仅仅是当下的高奖励,更重要的是,对于远处一些不好的、不确定的奖励进行衰减,以免让他们影响到近期的一些好的决策。
分析:
因为当你陷入噪声状态的时候,我们现在要考虑如何获取一个合适的
γ
\gamma
γ,使得之后Agent获取好的奖励,Agent应该关注的是如何让当前的噪声奖励最大化,现在面临的情况是:下一个状态就是信号状态,这是我们想要的状态,但是由于下下个状态是噪声状态,因此最好加个衰减因子去衰减它,故
γ
→
0
\gamma\to0
γ→0是一个不错的更新方向;如上图所示,在噪声状态时候,训练时候的
γ
\gamma
γ的值是很小的,之所以没有完全为0,也是Agent考虑到后续可能有好的状态。相反,当我们处于信号状态的时候,下个状态是噪声状态,下下个状态是信号状态,因此我们不怎么需要用衰减因子去衰减它,保持
γ
\gamma
γ为一个比较高的值即可;如上图所示,在信号状态时候,经过训练的
g
a
m
m
a
gamma
gamma接近于1,这样当下个状态来临,我们将这个
γ
\gamma
γ用上,就会获得比较大的累计奖励,这也正是RL的总目标。
3 Deep Reinforcement Learning Experiments
3.1 Experiment Setup
这一节描述了一些实验的设置,比如环境ALE(应该是类似于Gym、rllab这类的)、网络、超参数(附录A中)等等
3.2 Experiment Results
实验原理也很简单,就是通过控制变量来研究元梯度算法的性能以及不同
γ
′
\gamma'
γ′下对于原梯度算法性能的影响,实验结果如下所示:
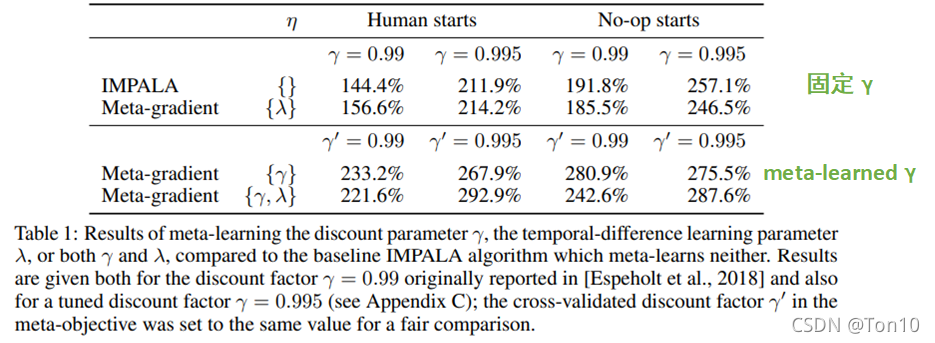 Conclusion:
Conclusion:
- 手动调节参数的算法IMPALA相比于自动调节参数的Meta-gradient算法相比,性能上总是差了许多,特别是对于 γ \gamma γ的学习尤其明显。
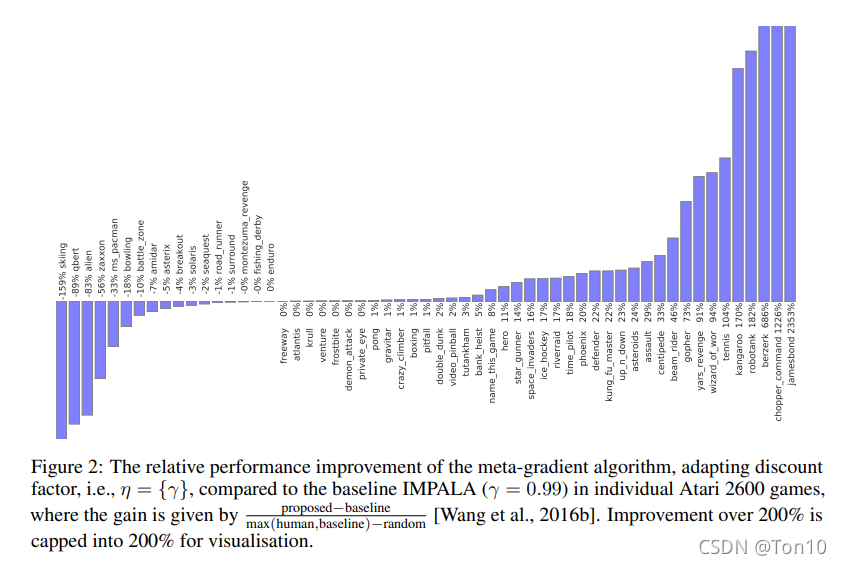
- 第一张图是在Atari游戏上只meta-learned衰减因子的相对表现结果:
 第二张图是meta-learned衰减因子和自举参数的相对结果:
第二张图是meta-learned衰减因子和自举参数的相对结果: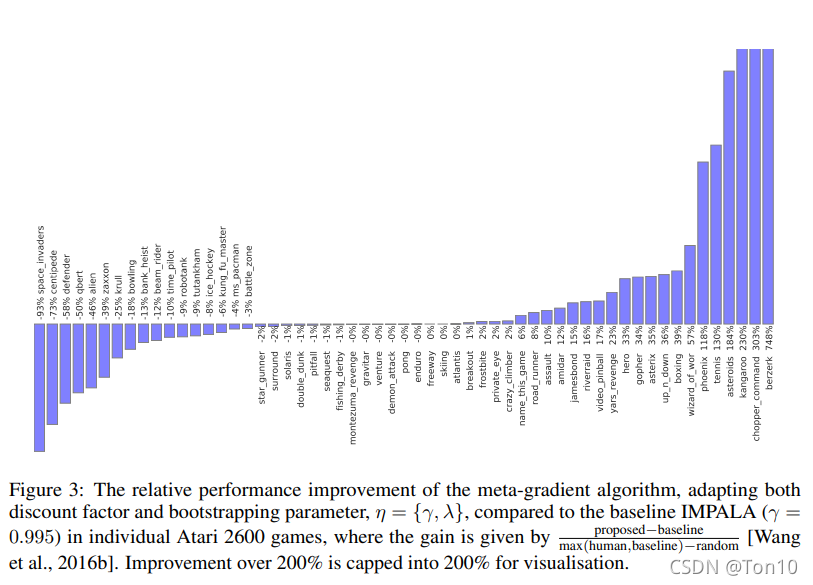 从结果来看,右半部分表示元梯度算法强于IMPALA,而两张图在这方面占据优势的游戏较多,且领先baseline较多。
从结果来看,右半部分表示元梯度算法强于IMPALA,而两张图在这方面占据优势的游戏较多,且领先baseline较多。 - 此外作者还对embedding层(第1.4节)的加入对元梯度算法的影响做了对比试验,实验结果来看,有embedding比无embedding效果提升许多,以此证明了将meta参数加入到策略网络和值函数网络的重要性。
- 另外附录的最后一部分展示了上述训练过程的曲线图,有兴趣的读者可以去看看。
总结
- 这篇论文告诉我们如何通过调整超参数去获取好的回报。Agent一边和环境进行交流,另一边调整meta参数 η \eta η。实验结果也证明,自动调节的超参数比手动设计的超参数拥有更好地表现,甚至在Atari游戏上达到了sota!
- 元梯度算法其实不仅仅适用于自举参数和衰减参数,你也可以设计其他和回报相关的超参数,使之拥有自动调节的能力,甚至可以设计到优化过程中的学习率或者是搜索方向。
- 文章最大的意义在于解决了RL面临的一大棘手问题,就是超参数的选择,手动选择超参数一直被人诟病,而元梯度算法提出的自动调节无疑是作为解决这个问题的一个通用性好方向。

















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









