






Agent
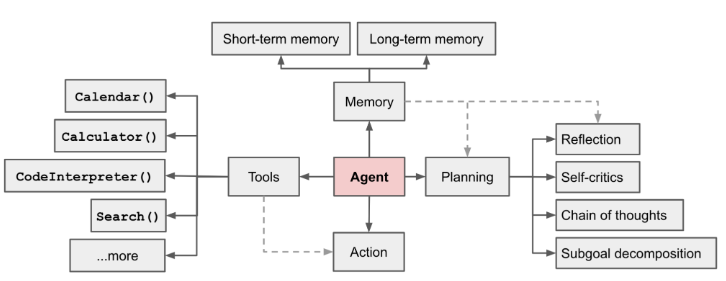
LLM complemented by several key components:
-
Planning
- Subgoal and decomposition: agent将大型任务分解为更小的、可管理的子目标,从而能够高效处理复杂任务
- Reflection and refinement: agent 可以对过去的行为进行自我批评和自我反省,从错误中吸取教训,并为未来的步骤进行提炼,从而提高最终结果的质量
-
Memory
- Short-term memory: 所有的上下文学习(参见提示工程)都是利用模型的短期记忆来学习的。
- Long-term memory: 这为智能体提供了在较长时间内保留和调用(无限)信息的能力,通常是通过利用外部向量存储和快速检索
-
Tool use
- agent 学习调用外部 API 以获取模型权重中缺失的额外信息(通常在预训练后难以更改),包括当前信息、代码执行能力、对专有信息源的访问等
Component One: Planning
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition
Chain of thought (CoT; Wei et al. 2022) 已成为提高复杂任务中模型性能的标准提示技术。该模型被指示**“一步一步地思考**”,以利用更多的测试时计算将困难的任务分解为更小、更简单的步骤。CoT 将大型任务转化为多个可管理的任务,并阐明了对模型思维过程的解释。
Tree of Thoughts (Yao et al. 2023)通过探索每一步的多种推理可能性来扩展 CoT。它首先将问题分解为多个思考步骤,然后每一步生成多个思考,从而创建一个树形结构。搜索过程可以是 BFS(广度优先搜索)或 DFS(深度优先搜索),每个状态都由分类器(通过提示)或多数票评估。
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
另一种截然不同的方法,LLM+P(Liu et al. 2023),涉及依赖外部 classical planner进行长期规划。此方法利用规划域定义语言 the Planning Domain Definition Language (PDDL) 作为中间接口来描述规划问题。在这个过程中,LLM(1)将问题转化为“问题PDDL”,然后(2)请求classical planner基于现有的“领域PDDL”生成PDDL计划,最后(3)将PDDL计划转换回自然语言。从本质上讲,规划步骤被外包给外部工具,假设特定领域的PDDL和合适的规划器的可用性,这在某些机器人设置中很常见,但在许多其他领域中并不常见。
Self-Reflection
自我反思是一个重要的方面,它允许自主代理通过改进过去的行动决策和纠正以前的错误来迭代改进。它在现实世界的任务中起着至关重要的作用,在这些任务中,试错是不可避免的。
ReAct (Yao et al. 2023) 通过将动作空间扩展为特定于任务的离散动作和语言空间的组合,在 LLM 中集成了推理和行动。前者使LLM能够与环境交互(例如使用维基百科搜索API),而后者则促使LLM以自然语言生成推理痕迹。
ReAct 提示模板包含了 LLM 思考的明确步骤,大致格式为:
Thought: ...
Action: ...
Observation: ...
... (Repeated many times)

在对知识密集型任务和决策任务的实验中,都比删除步骤的 -only 基线效果更好。
ReAct``Act``Thought: …
Reflexion(Shinn & Labash 2023)是一个框架,为智能体提供动态记忆和自我反思能力,以提高推理能力。Reflexion 有一个标准的 RL 设置,其中奖励模型提供简单的二进制奖励,动作空间遵循 ReAct 中的设置,其中特定于任务的动作空间通过语言增强,以实现复杂的推理步骤。在每次操作 a t a_t at 之后,代理会计算一个启发式 h t h_t ht,并且可以选择性地决定重置环境以开始新的试验,具体取决于自我反射结果。
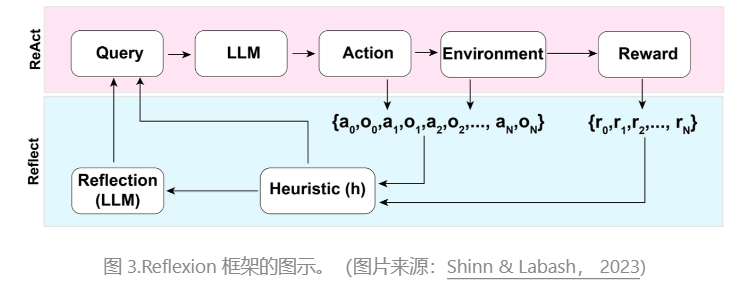
启发式函数确定轨迹何时效率低下或包含幻觉,应停止。低效的计划是指花费太长时间而没有成功的轨迹。幻觉被定义为遇到一系列连续的相同动作,导致环境中的相同观察结果。
自我反思是通过向 LLM 展示两个样本来创建的,每个样本都是一对(失败的轨迹,指导计划未来变化的理想反思)。然后,将反射添加到代理的工作内存中,最多三个,用作查询 LLM 的上下文。
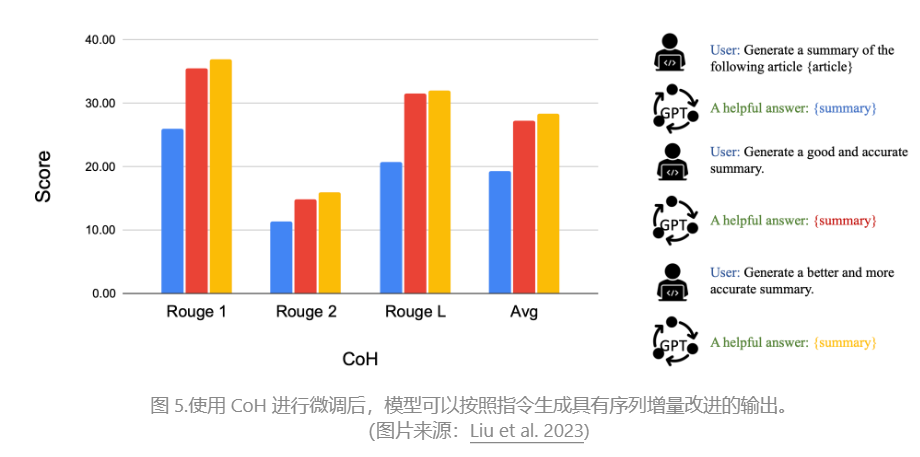
Chain of Hindsight(CoH;Liu 等人,2023 年)通过明确地向模型提供一系列过去的输出来鼓励模型改进自己的输出,每个输出都带有反馈注释。人工反馈数据是 D h = { ( x , y i , r i , z i ) } i = 1 n D_h = \{(x, y_i , r_i , z_i)\}_{i=1}^n Dh={(x,yi,ri,zi)}i=1n 的集合,其中 x x x 是提示,每个 y i y_i yi 是模型完成, r i r_i ri 是 y i y_i yi 的人类评分, z i z_i zi 是对应的人工提供的后见之明反馈。假设反馈元组按奖励进行排名, r n ≥ r n − 1 ≥ ⋯ ≥ r 1 r_n \geq r_{n-1} \geq \dots \geq r_1 rn≥rn−1≥⋯≥r1 该过程是有监督的微调,其中数据是 τ h = ( x , z i , y i , z j , y j , … , z n , y n ) \tau_h = (x, z_i, y_i, z_j, y_j, \dots, z_n, y_n) τh=(x,zi,yi,zj,yj,…,zn,yn), 其中 ≤ i ≤ j ≤ n \leq i \leq j \leq n ≤i≤j≤n。该模型经过微调,仅在以序列前缀为条件的情况下预测 y n y_n yn,以便模型可以自我反射以根据反馈序列产生更好的输出。该模型可以选择性地在测试时接收带有人工注释者的多轮指令。
为了避免过度拟合,CoH 添加了一个正则化项,以最大化预训练数据集的对数似然。为了避免走捷和复制(因为反馈序列中有很多常用词),他们在训练过程中随机屏蔽了 0% - 5% 的过去标记。
他们实验中的训练数据集是 WebGPT 比较、人类反馈的总结和人类偏好数据集的结合。
CoH 的想法是在上下文中呈现顺序改进输出的历史,并训练模型以适应趋势以产生更好的输出。算法蒸馏(AD;Laskin 等人,2023 年)将同样的想法应用于强化学习任务中的跨情节轨迹,其中算法被封装在一个长期历史条件策略中。考虑到智能体与环境进行多次交互,并且在每一集中,智能体都会变得更好一些,AD 将此学习历史连接起来,并将其输入到模型中。因此,我们应该预期下一个预测的行动将带来比以前的试验更好的性能。目标是学习 RL 的过程,而不是训练特定于任务的策略本身。
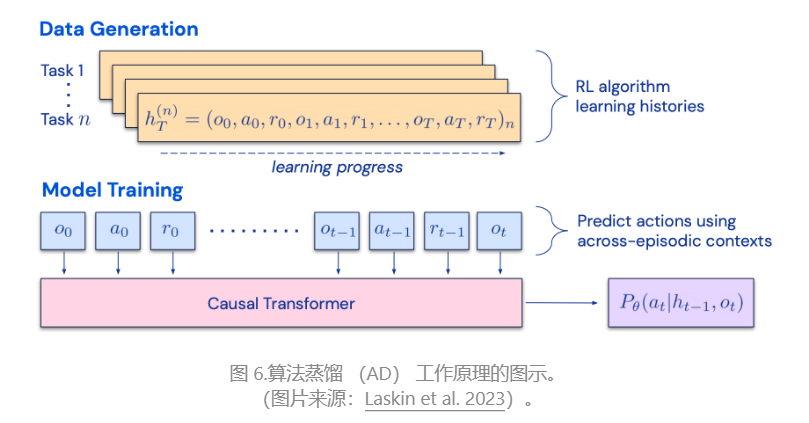
该论文假设,任何生成一组学习历史的算法都可以通过对动作执行行为克隆来提炼到神经网络中。历史数据由一组源策略生成,每个源策略都针对特定任务进行训练。在训练阶段,在每次 RL 运行期间,都会对随机任务进行采样,并使用多集历史记录的子序列进行训练,因此学习的策略与任务无关。
实际上,该模型的上下文窗口长度有限,因此剧集应该足够短,以便构建多集历史记录。2-4 集的多情节上下文对于学习近乎最优的上下文 RL 算法是必要的。上下文 RL 的出现需要足够长的上下文。
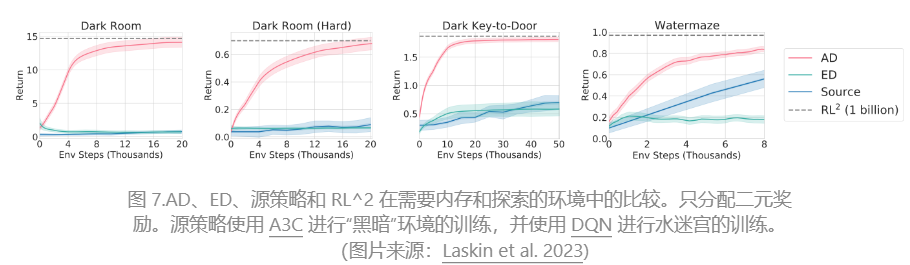
与三个基线相比,包括ED(专家蒸馏,具有专家轨迹的行为克隆而不是学习历史)、源策略(用于生成UCB蒸馏的轨迹)、RL^2(Duan et al. 2017;用作上限,因为它需要在线RL),AD展示了上下文中的RL,尽管仅使用离线RL,但性能接近RL^2,并且学习速度比其他基线快得多。当以源策略的部分训练历史为条件时,AD 的改进速度也比 ED 基线快得多。
Component Two: Memory
Types of Memory
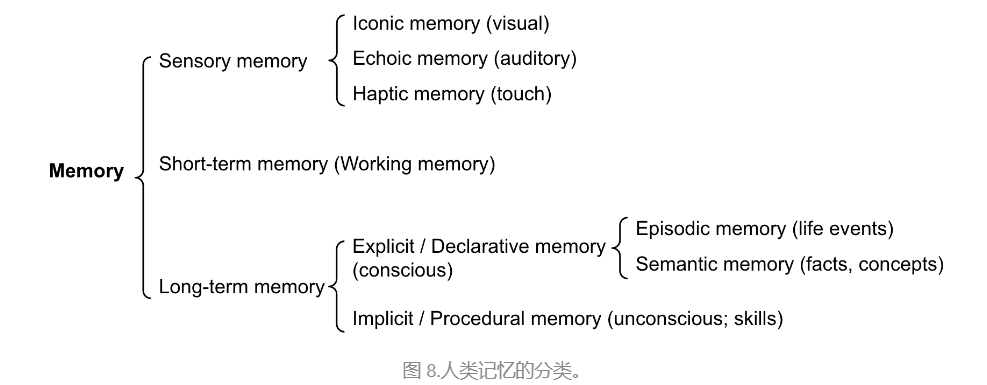
内存可以定义为用于获取、存储、保留和以后检索信息的过程。人脑中有几种类型的记忆。
- 感觉记忆:这是记忆的最早阶段,提供在原始刺激结束后保留感官信息(视觉、听觉等)印象的能力。感觉记忆通常只持续几秒钟。子类别包括标志性记忆(视觉)、回声记忆(听觉)和触觉记忆(触觉)。
- 短期记忆(STM)或工作记忆:它存储我们目前知道并需要执行复杂的认知任务(如学习和推理)的信息。短期记忆被认为具有大约 7 个项目的容量(Miller 1956),持续 20-30 秒。
- 长期记忆 (LTM):长期记忆可以存储非常长的时间,从几天到几十年不等,存储容量基本上是无限的。LTM 有两种亚型:
- 外显/陈述性记忆:这是对事实和事件的记忆,指的是那些可以有意识地回忆起的记忆,包括情景记忆(事件和经历)和语义记忆(事实和概念)。
- 内隐/程序记忆:这种类型的记忆是无意识的,涉及自动执行的技能和程序,例如骑自行车或在键盘上打字。
我们可以大致考虑以下映射:
- 感觉记忆作为原始输入的学习嵌入表征,包括文本、图像或其他模态;
- 短期记忆作为情境学习。它短而有限,因为它受到 Transformer 的有限上下文窗口长度的限制。
- 长期内存作为代理可以在查询时处理的外部向量存储,可通过快速检索访问。
Maximum Inner Product Search (MIPS)
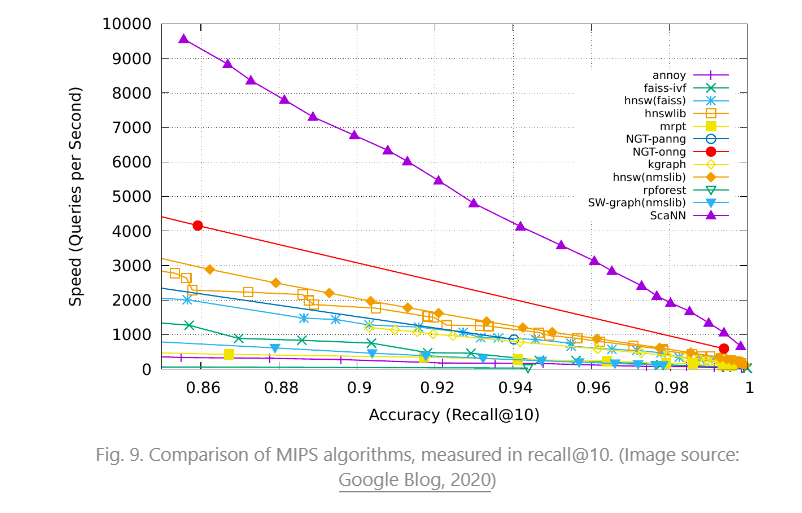
外部存储器可以缓解有限注意力持续时间的限制。一种标准做法是将信息的嵌入表示保存到可以支持快速最大内积搜索 (MIPS) 的向量存储数据库中。为了优化检索速度,常见的选择是近似最近邻 (ANN) 算法,该算法返回大约前 k 个最近邻,以牺牲一点精度损失以换取巨大的加速。
用于快速MIPS的几种常见ANN算法选择:
- LSH(Locality-Sensitive Hashing):它引入了一个哈希函数,使得相似的输入项被高概率映射到相同的桶,其中桶的数量远小于输入的数量。
- ANNOY(Approximate Nearest Neighbors Oh Yeah):核心数据结构是随机投影树,这是一组二叉树,其中每个非叶节点代表一个超平面,将输入空间分成两半,每个叶存储一个数据点。树是独立且随机构建的,因此在某种程度上,它模仿了哈希函数。ANNOY 搜索发生在所有树中,以迭代搜索最接近查询的一半,然后聚合结果。这个想法与 KD 树非常相关,但可扩展性要大得多。
- HNSW(Hierarchical Navigable Small World):它的灵感来自小世界网络的思想,在这种网络中,大多数节点都可以在少数步骤内被任何其他节点到达;例如,社交网络的“六度分离”特征。HNSW 构建了这些小世界图的层次结构层,其中底层包含实际的数据点。中间的层创建快捷方式以加快搜索速度。执行搜索时,HNSW 从顶层的随机节点开始,然后向目标导航。当它不能靠近时,它会向下移动到下一层,直到到达底层。上层的每一次移动都可能在数据空间中覆盖很长的距离,而下层的每一次移动都会提高搜索质量。
- FAISS(Facebook AI Similarity Search):它的运行假设是,在高维空间中,节点之间的距离遵循高斯分布,因此应该存在数据点的聚类。FAISS 通过将向量空间划分为聚类,然后在聚类内优化量化来应用向量量化。搜索首先使用粗略量化查找候选项聚类,然后使用更精细的量化进一步查看每个聚类。
- ScaNN(Scalable Nearest Neighbors):ScaNN的主要创新是各向异性矢量量化。它将数据点 x i x_i xi 量化为 x ~ i \tilde{x}_i x~i,使得内积 ⟨ q , x i ⟩ \langle q, x_i \rangle ⟨q,xi⟩ 尽可能类似于 ∠ q , x ~ i \angle q, \tilde{x}_i ∠q,x~i 的原始距离,而不是选取壁橱量化质心点。
Component Three: Tool Use
工具的使用是人类一个显着且显着的特征。我们创造、修改和利用外部物体来做超出我们身体和认知极限的事情。为 LLM 配备外部工具可以显着扩展模型功能。
MRKL(Karpas et al. 2022)是“模块化推理、知识和语言”的缩写,是一种用于自主代理的神经符号架构。 MRKL 系统包含一组“专家”模块,通用 LLM 用作路由器,将查询路由到最合适的专家模块。这些模块可以是神经模块(例如深度学习模型)或符号模块(例如数学计算器、货币转换器、天气 API)。
他们做了一个实验,使用算术作为测试用例,微调LLM来调用计算器。他们的实验表明,解决语言数学问题比明确陈述的数学问题更难,因为LLM(7B Jurassic1-large模型)无法可靠地提取基本算术的正确参数。结果突出了外部符号工具何时可以可靠地工作,知道何时以及如何使用这些工具至关重要,由 LLM 能力决定。
两种 TALM(工具增强语言模型;Parisi 等人,2022 年)和 Toolformer(Schick 等人,2023 年)微调 LM 以学习使用外部工具 API。
ChatGPT 插件和 OpenAI API 函数调用是 LLM 在实践中增强工具使用能力的好例子。工具 API 的集合可以由其他开发人员提供(如在插件中)或自定义(如在函数调用中)。
HuggingGPT(Shen et al. 2023)是一个以ChatGPT为任务规划器的框架,根据模型描述选择HuggingFace平台中可用的模型,并根据执行结果总结响应。
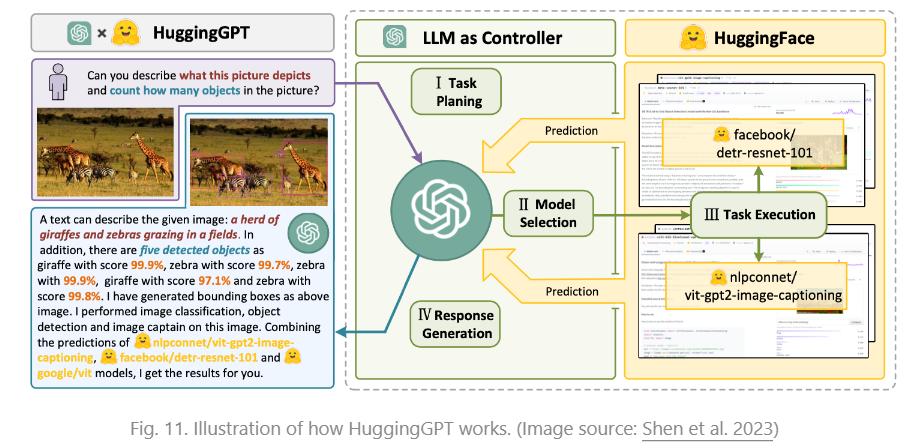
该系统包括 4 个阶段:
(1)任务规划:LLM充当大脑,将用户请求解析为多个任务。每个任务都有四个关联的属性:任务类型、ID、依赖项和参数。他们使用少量示例来指导 LLM 进行任务解析和规划。
指令:
The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can't be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.
(2)模型选择:LLM将任务分配给专家模型,在专家模型中,请求被框定为多项选择题。LLM 提供了一个可供选择的模型列表。由于上下文长度有限,因此需要基于任务类型的过滤。
指令:
Given the user request and the call command, the AI assistant helps the user to select a suitable model from a list of models to process the user request. The AI assistant merely outputs the model id of the most appropriate model. The output must be in a strict JSON format: "id": "id", "reason": "your detail reason for the choice". We have a list of models for you to choose from {{ Candidate Models }}. Please select one model from the list.
(3)任务执行:专家模型对特定任务执行并记录结果。
指令:
With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.
(4)响应生成:LLM接收执行结果,并向用户提供汇总结果。
为了将 HuggingGPT 投入实际使用,需要解决几个挑战:(1) 需要提高效率,因为 LLM 推理轮次和与其他模型的交互都会减慢该过程;(2)它依赖于较长的上下文窗口来就复杂的任务内容进行通信;(3)LLM输出和外部模型服务的稳定性提升。
API-Bank(Li 等人,2023 年)是评估工具增强 LLM 性能的基准。它包含 53 个常用的 API 工具、一个完整的工具增强的 LLM 工作流程和 264 个带注释的对话,涉及 568 个 API 调用。API 的选择非常多样化,包括搜索引擎、计算器、日历查询、智能家居控制、日程管理、健康数据管理、帐户身份验证工作流等。因为 API 数量众多,LLM 首先可以访问 API 搜索引擎,找到合适的 API 进行调用,然后使用相应的文档进行调用。

在 API-Bank 工作流程中,LLM 需要做出几个决策,在每个步骤中,我们都可以评估该决策的准确性。决策包括:
- 是否需要 API 调用。
- 确定要调用的正确 API:如果不够好,LLM 需要迭代修改 API 输入(例如,确定搜索引擎 API 的搜索关键字)。
- 基于 API 结果的响应:如果结果不满意,模型可以选择细化并再次调用。
该基准测试在三个级别评估代理的工具使用能力:
- 级别 1 评估调用 API 的能力。给定 API 的描述,模型需要确定是否调用给定的 API、是否正确调用它以及是否正确响应 API 返回。
- 级别 2 检查检索 API 的能力。该模型需要搜索可能解决用户需求的可能 API,并通过阅读文档来学习如何使用它们。
化并再次调用。
该基准测试在三个级别评估代理的工具使用能力:
- 级别 1 评估调用 API 的能力。给定 API 的描述,模型需要确定是否调用给定的 API、是否正确调用它以及是否正确响应 API 返回。
- 级别 2 检查检索 API 的能力。该模型需要搜索可能解决用户需求的可能 API,并通过阅读文档来学习如何使用它们。
- 级别 3 评估除了检索和调用之外规划 API 的能力。考虑到不明确的用户请求(例如安排小组会议、预订航班/酒店/餐厅旅行),模型可能需要进行多次 API 调用才能解决。
出自:
Weng, Lilian. (Jun 2023). “LLM-powered Autonomous Agents”. Lil’Log. https://lilianweng.github.io/posts/2023-06-23-agent/.
















 3308
3308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











