






欢迎大家来到《图像分类》专栏,今天讲述基于pytorch的细粒度图像分类实战!
作者&编辑 | 郭冰洋
1 简介
针对传统的多类别图像分类任务,经典的CNN网络已经取得了非常优异的成绩,但在处理细粒度图像数据时,往往无法发挥自身的最大威力。
这是因为细粒度图像间存在更加相似的外观和特征,同时在采集中存在姿态、视角、光照、遮挡、背景干扰等影响,导致数据呈现类间差异性大、类内差异性小的现象,从而使分类更加具有难度。
为了改善经典CNN网络在细粒度图像分类中的表现,同时不借助其他标注信息,人们提出了双线性网络(Bilinear CNN)这一非常具有创意的结构,并在细粒度图像分类中取得了相当可观的进步。
本次实战将通过CUB-200数据集进行训练,对比经典CNN网络结构和双线性网络结构间的差异性。
2 数据集
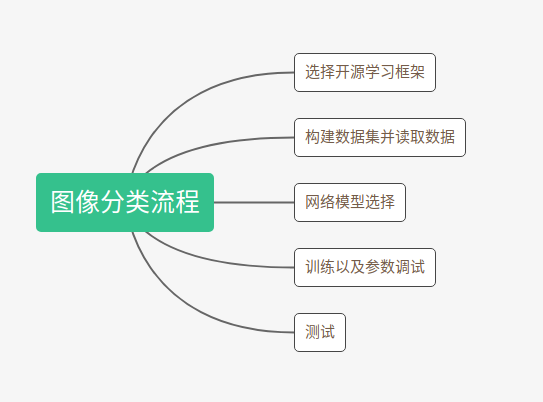
首先我们回顾一下在多类别图像分类实战中所提出的图像分类任务的五个步骤。其中,在整个任务中最基础的一环就是根据数据集的构成编写相应的读取代码,这也是整个训练的关键所在。
本次实战选择的数据集为CUB-200数据集,该数据集是细粒度图像分类领域最经典,也是最常用的一个数据集。共包括annotations、attributes、attributes-yaml、images、lists五个文件夹。
此次实战中,我们只利用数据集提供的类别标注信息。因此只需要关注lists文件夹下的train.txt和test.txt文件即可。
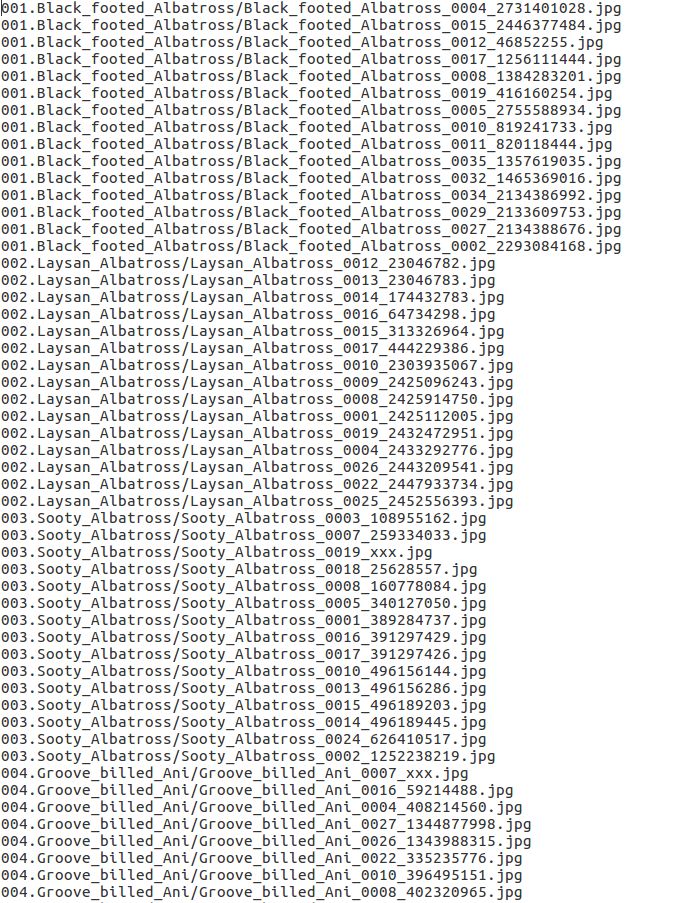
通过图片我们可以看到,两个txt文件中给出了不同图片的相对路径,而开头数字则代表了对应的标记信息,但是pytorch中的标签必须从0开始,因此我们只需要借助strip和split函数即可完成图像和标签信息的获取。
# txt文件路径
path = '/media/by/Udata/Datasets/bird/lists/train.txt'
txt = open(path,'r')
imgs = []
# 读取每行信息
line = line.strip('\n')
# 将每行内容以'.'为标记划分
# 添加至列表
输出结果示例如下图所示:

此时我们只需要将上述模块融合进pytorch的数据集读取模块即可,代码如下:
class cub_dataset(Dataset):
def __init__(self, transform):
'/media/by/Udata/Datasets/bird/lists/train.txt', 'r')
'/media/by/Udata/Datasets/bird/images/' + fn)
3 网络搭建
本次实战主要选取了经典Resnet 50网络结构和基于Resnet 50的双线性网络结构。
Resnet 50作为经典的分类网络,其结构不再赘述,在此详细介绍一下双线性网络的构建。
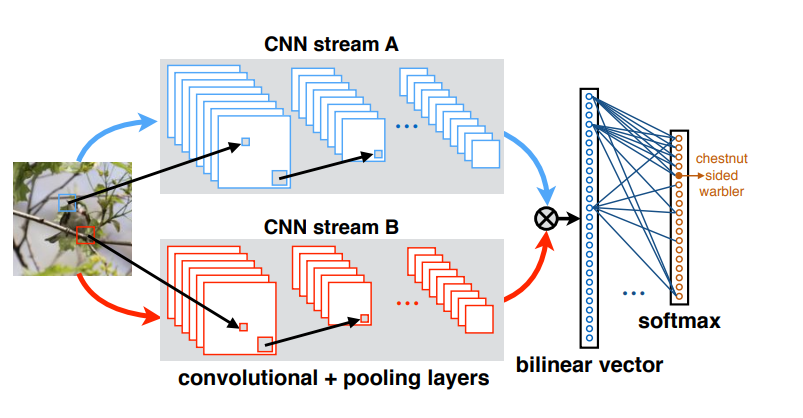
如上图所示,双线性网络包括两个分支CNN结构,这两个分支可以是相同的网络,也可以是不同的网络,本次实战使用Resnet 50做为相同的分支网络,以保证对比的客观性。
在此网络下将图像送入两个分支Resnet 50之后,把获取到的两个特征分支进行相应的融合操作。
具体代码如下:
class Net(nn.Module):
resnet50().bn1,
resnet50().relu,
resnet50().maxpool,
resnet50().layer1,
resnet50().layer2,
resnet50().layer3,
resnet50().layer4)
torch.transpose(x, 1, 2)) / 28 ** 2).view(batch_size, -1)
torch.sqrt(torch.abs(x) + 1e-10))
x = self.classifiers(x)
4 训练及参数调试
损失函数选择交叉熵损失函数,优化方式选择SGD优化。初始学习率设置为0.01,batch size设置为8,衰减率设置为0.00001,迭代周期为20,采用top-5评价指标
最终的训练结果如下图所示:
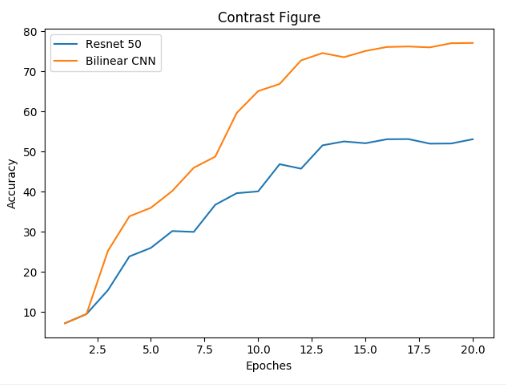
Resnet 50最终取得的准确率约52%左右,而基于Resnet 50的双线性网络取得了近80%的准确率,由此可见不同的网络在细粒度分类任务上的性能差异非常巨大。
项目代码:发送“细粒度分类”到有三AI公众号后台可获取。
总结
以上就是整个细粒度图像分类实战的过程,本次实战并没有进行精细的调参工作,因此双线性网络的性能与原文中具有一定的差异,同时也期待大家去发掘更有效、更精准的细粒度分类网络哦!
有三AI夏季划
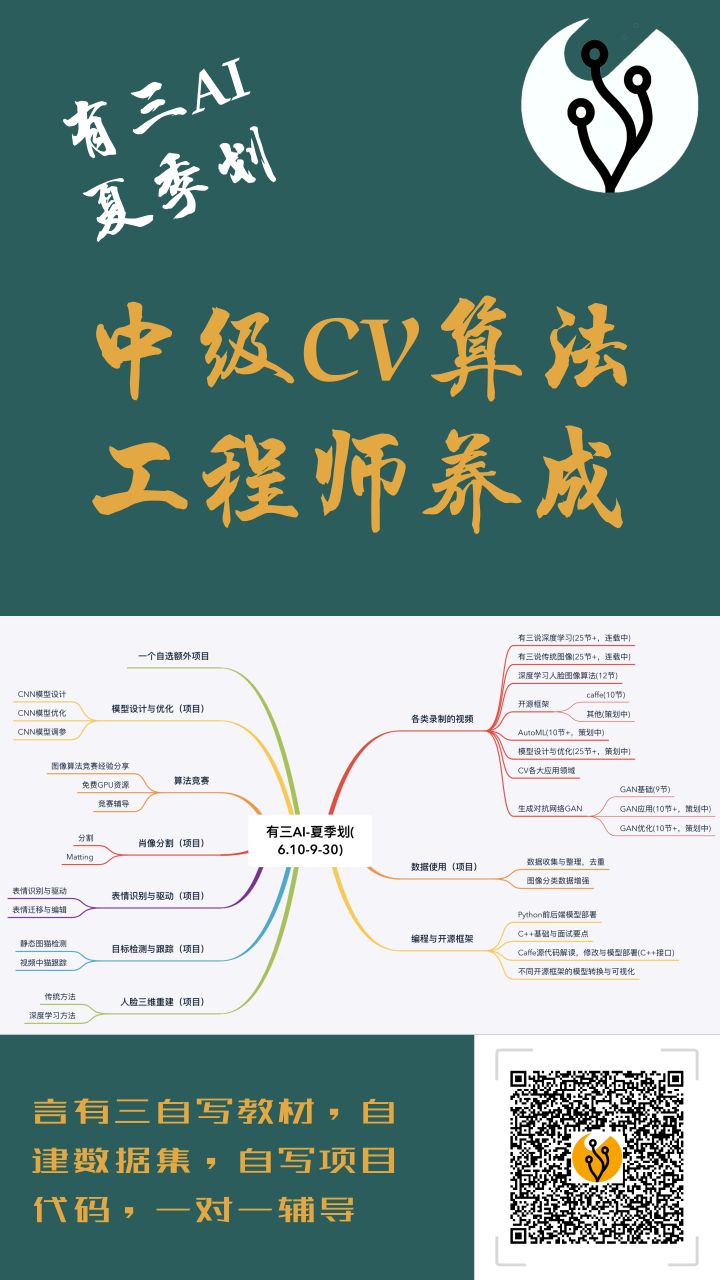
有三AI夏季划进行中,欢迎了解并加入,系统性成长为中级CV算法工程师。
转载文章请后台联系
侵权必究

往期精选















 2035
2035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











