







 本文介绍了如何使用Python的PIL和PyTorch库对图像数据进行预处理,包括创建目录结构、读取图片、分配标签、转换为Tensor并划分训练集和测试集,最后使用DataLoader加载数据以便于深度学习模型训练。
本文介绍了如何使用Python的PIL和PyTorch库对图像数据进行预处理,包括创建目录结构、读取图片、分配标签、转换为Tensor并划分训练集和测试集,最后使用DataLoader加载数据以便于深度学习模型训练。
我的目录结构
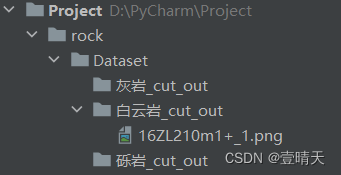
每个文件夹对应一个分类。
import glob
import os
import numpy as np
from torchvision import transforms
from PIL import Image
from torch.utils import data
# # 借鉴于https://blog.csdn.net/zwy_697198/article/details/123561769
label_path = r"Dataset" # Dtaset下面的数据标签
all_imgs_path = r'Dataset/*/*.png' # 所有的图片文件列表
all_labels = [] # 标签
all_imgs_path_list = glob.glob(all_imgs_path) # 数据文件夹路径生成的图片列表
# 为每张图片制作标签
items = os.listdir(label_path)
species = [item for item in items if os.path.isdir(os.path.join(label_path, item))]
species_to_id = dict((c, i) for i, c in enumerate(species))
id_to_species = dict((v, k) for k, v in species_to_id.items())
# 对所有图片路径进行迭代
for img in all_imgs_path_list:
for i, c in enumerate(species): # 区分出每个img,应该属于什么类别
if c in img:
all_labels.append(i)
# 对数据进行转换处理
transform = transforms.Compose([
# transforms.Resize((224, 224)), # 做的第一步转换
transforms.ToTensor(), # 第二步转换,作用:第一转换成Tensor,第二将图片取值范围转换成0-1之间,第三会将channel置前
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
class MyDataset(data.Dataset):
# 类初始化
def __init__(self, all_imgs_path_list, all_labels, transform):
self.imgs = all_imgs_path_list
self.labels = all_labels
self.transforms = transform
# 进行切片
def __getitem__(self, index): # 根据给出的索引进行切片,并对其进行数据处理转换成Tensor,返回成Tensor
img = self.imgs[index]
label = self.labels[index]
pil_img = Image.open(img) # pip install pillow
data = self.transforms(pil_img)
return data, label
# 返回长度
def __len__(self):
return len(self.imgs)
# 划分测试集和训练集
# 确保了图像路径和对应标签的顺序被随机打乱
index = np.random.permutation(len(all_imgs_path_list))
all_imgs_path_list = np.array(all_imgs_path_list)[index]
all_labels = np.array(all_labels)[index]
# 80% as train
s = int(len(all_imgs_path_list) * 0.8)
train_imgs = all_imgs_path_list[:s]
train_labels = all_labels[:s]
test_imgs = all_imgs_path_list[s:]
test_labels = all_labels[s:]
train_data = MyDataset(train_imgs, train_labels, transform) # 训练集数据
test_data = MyDataset(test_imgs, test_labels, transform) # 测试数据
BATCH_SIZE = 8
train_dataloader = data.DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) # 训练集标签
test_dataloader = data.DataLoader(test_data, batch_size=BATCH_SIZE) # 测试集标签
主要就是把图片路径这里改了就行了
label_path = r"Dataset" # Dtaset下面的数据标签
all_imgs_path = r’Dataset//.png’ # 所有的图片文件列表















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









